本文主要是介绍音频数据集1--LJSpeech单人语音,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
LJ Speech Dataset
版本号: 1.1 , 文件大小: 2.6GB
1.简介
1. 1 内容简介
LJS是一个语音数据集,包含 13,100 个音频片段,内容为Linda Johnson(欧美女性)朗读的 7 本书籍段落(非小说类)。每个片段都提供文本转录,片段长度从 1 到 10 秒不等,总长度约为 24 小时。
- 7本书籍内容
发表于 1884 年至 1964 年之间,内容如下:
1. 莫里斯,威廉等人。《艺术与手工艺论文集》。1893 年。2.格里菲思,亚瑟。《纽盖特编年史》,第 2 卷。1884 年。3.罗斯福,富兰克林·D。《富兰克林·德拉诺·罗斯福的炉边闲谈》。1933-42 年。4.哈兰德,马里恩。《马里恩·哈兰德的初学者烹饪》。1893 年。5.罗尔特-惠勒,弗朗西斯。《科学 - 宇宙历史》,第 5 卷:生物学。1910 年。6.班克斯,埃德加·J。《古代世界七大奇迹》。1916 年。7.总统肯尼迪总统遇刺事件委员会。总统肯尼迪总统遇刺事件委员会报告。1964 年。
- 数据集参数
总片段数-Total Clips: 13,100不同单词数-Distinct Words: 13,821总单词数-Total Words: 225,715 # 单词总数量,重复出现也统计总字符数-Total Characters: 1,308,678总时长-Total Duration: 23:55:17平均片段时长-Mean Clip Duration: 6.57 sec最短片段时长-Min Clip Duration: 1.11 sec最长片段时长-Max Clip Duration: 10.10 sec每片段的平均单词数-Mean Words per Clip: 17.23
1.2 制作简介
- 静音分段
通过录音中的静音部分自动分段
- 文本匹配语音内容
通过质量保证检查 (Quality Assurance Pass)来保证文本的准确性。
- 比特率:128kbps
数据来原LibriVox的格式为MP3,数据有伪影
伪影 (artifacts) 是指在音频文件的压缩和解压缩过程中,由于丢失特征造成的音频失真或不自然效果
- 脉冲编码调制(Pulse Code Modulation,PCM):
用于模拟信号转换为数字信号
采样率: 每秒钟采样的次数(例如44.1 kHz)。
位深度: 每个样本使用的比特数(例如16位)。
声道数: 音频的声道数(例如立体声是2个声道)。
比特率 (bps)=采样率×位深度×声道数
对于CD质量的音频(44.1 kHz, 16位, 立体声):
44 , 100 H z × 16 b i t s × 2 c h a n n e l s = 1 , 411 , 200 b p s = 1 , 411.2 k b p s 44,100Hz×16bits×2channels=1,411,200bps=1,411.2kbps 44,100Hz×16bits×2channels=1,411,200bps=1,411.2kbps
由于MP3是有损压缩格式,通过去除部分音频信息以压缩数据达到较低的比特率,即本数据的128 kbps。
2.音频文件
- 音频片段位于 wavs文件夹
单个音频文件命名从 LJ001-0001 到 LJ050-0278
代表有50个段落(章节),每个章节有约 200-300个片段
例如,050章有278个片段
- 音频可视化
050章的前30个片段可视化:
分别是 时域、频域、频谱(y轴log)、mel谱
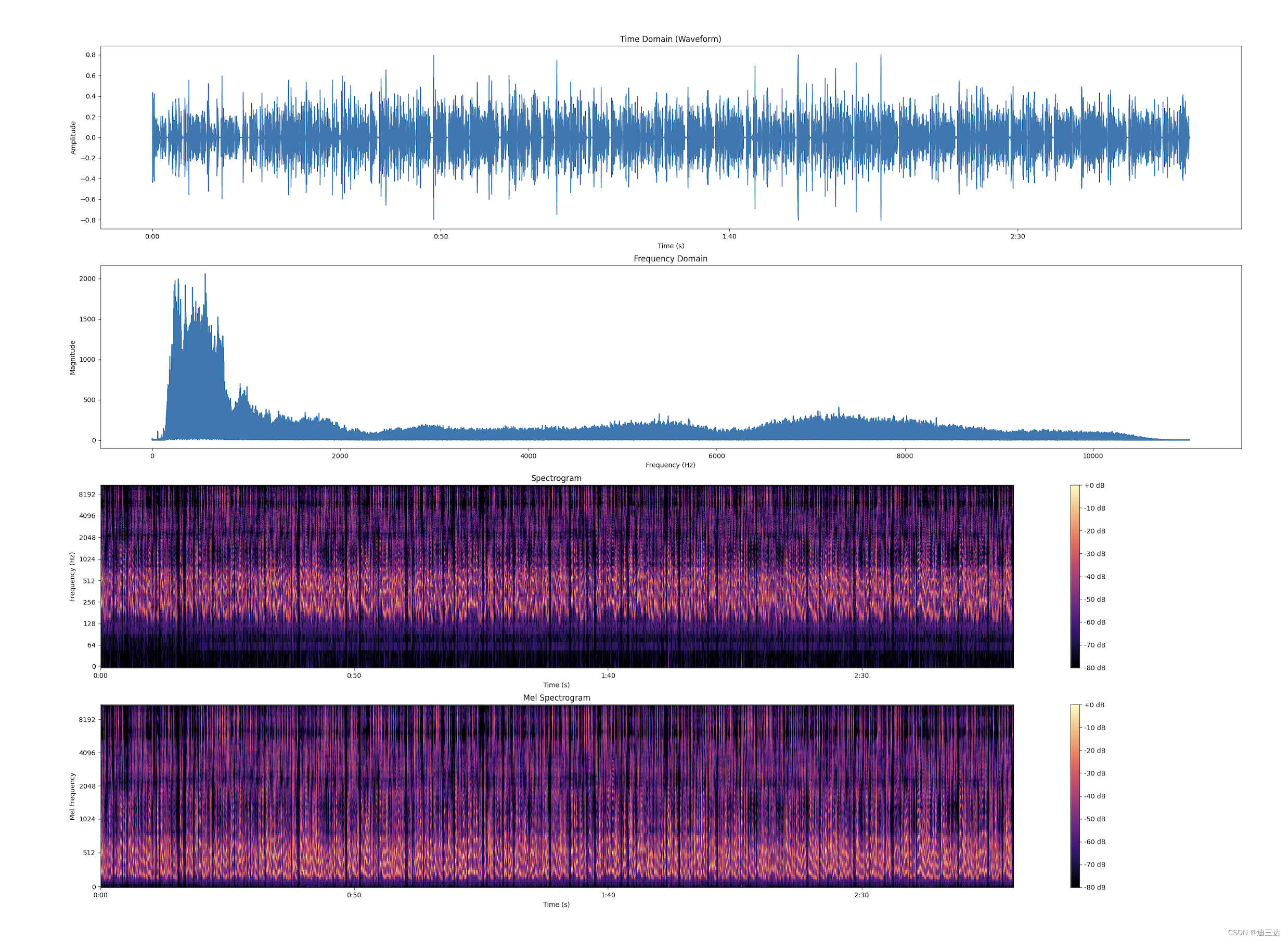
3.标注文件
- 文本标注位于 metadata.csv 文件。
其中 19 个转录本包含非 ASCII 字符(例如,LJ016-0257 包含“raison d’être”)
样例如下:
第一段音频 LJ001-0001 (10s):> Printing in the only sense with which we are at present concerned differs from most if not from all the arts and crafts represented in the Exhibition第二段音频 LJ001-0002 (2s):> in being comparatively modern.|in being comparatively modern.第三段音频 LJ001-0003 (9s):> For although the Chinese took impressions from wood blocks engraved in relief for centuries before the woodcutters of the Netherlands by a similar process- 2次标注
音频的标注文本有2个版本,第1个数字是用阿拉伯字符标记,第2个数字是用英文单词标记,2个标注文本通过字符 ‘|’ 分割。
举几个言例:
LJ001-0008|has never been surpassed.|has never been surpassed.LJ001-0045|1469, 1470;|fourteen sixty-nine, fourteen seventy;LJ002-0035|8. The press yard.|eight. The press yard.- 缩写
部分标注单词为缩写(Abbreviation), 其展开(Expansion)后对照如下:
Mr. Mister
Mrs. Misess (*)
Dr. Doctor
No. Number
St. Saint
Co. Company
Jr. Junior
Maj. Major
Gen. General
Drs. Doctors
Rev. Reverend
Lt. Lieutenant
Hon. Honorable
Sgt. Sergeant
Capt. Captain
Esq. Esquire
Ltd. Limited
Col. Colonel
Ft. Fort
4. Pytorch处理
HiFiGAN中处理如下
将文本标注**“metadata.csv“**的文件转为txt格式,并拆分为:
- 训练集标注”training.txt”
12950个判断
- 验证集标注”validation.txt”
150个片段
Reference
-
文中图片代码
-
https://keithito.com/LJ-Speech-Dataset/
-
https://github.com/keithito/tacotron
这篇关于音频数据集1--LJSpeech单人语音的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






