本文主要是介绍Redis进阶 - Redis 淘汰策略,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

我们知道Redis是分布式内存数据库,基于内存运行,可是有没有想过比较好的服务器内存也不过几百G,能存多少数据呢,当内存占用满了之后该怎么办呢?Redis的内存是否可以设置限制? 过期的key是怎么从内存中删除的?不要怕,本篇我们一起来看一下Redis的内存淘汰策略是如何释放内存的。
一、概述
开篇提到 Redis 是基于内存的数据库,当内存满了的时候会发生什么呢?Redis的内存是否可以设置限制? 过期的key是怎么从内存中删除的?其实在Redis中是可以设置内存最大限制的,因此我们不用担心Redis占满机器的内存影响其他服务,这个参数 maxmemory 是可以配置的:
# 配置文件
maxmemory <bytes>
# 命令行
127.0.0.1:6379> config get maxmemory
1) "maxmemory"
2) "0"
127.0.0.1:6379> config set maxmemory 1GB
OK
127.0.0.1:6379> config get maxmemory
1) "maxmemory"
2) "1073741824"
二、内存淘汰策略
Redis 的内存淘汰策略是指在Redis的用于缓存的内存不足时,怎么处理需要新写入且需要申请额外空间的数据。Redis中共有下面几种内存淘汰策略:
| 内存淘汰策略 | 说明 |
|---|---|
| noeviction | 默认策略,不进行淘汰。当内存不足时,所有写操作命令会返回错误,读操作命令可以正常执行。 |
| allkeys-lru | 当内存不足时,从所有数据中挑选最近最少使用的数据淘汰。 |
| allkeys-random | 当内存不足时,从所有数据中任意选择数据进行淘汰。 |
| allkeys-lfu | 当内存不足时,从所有数据中挑选最不经常访问的数据淘汰。 |
| volatile-lru | 当内存不足时,从已设置过期时间的数据中,挑选最近最少使用的数据淘汰。 |
| volatile-random | 当内存不足时,从已设置过期时间的数据中任意选择数据淘汰。 |
| volatile-ttl | 当内存不足时,在设置了过期时间的key中,根据key的过期时间进行淘汰,越早过期的越优先被淘汰。 |
| volatile-lfu | 当内存不足时,从已设置过期时间的数据中,挑选最不经常访问的数据淘汰。 |
使用下面的参数 maxmemory-policy 配置淘汰策略:
127.0.0.1:6379> config get maxmemory-policy
1) "maxmemory-policy"
2) "noeviction"
127.0.0.1:6379> config set maxmemory-policy allkeys-random
OK
127.0.0.1:6379> config get maxmemory-policy
1) "maxmemory-policy"
2) "allkeys-random"
三、缓存淘汰算法
3.1 FIFO 算法
FIFO 是最简单的淘汰策略,遵循着先进先出的原则。最先进入缓存的数据,在缓存空间不足时被清除。这里简单提一下:

3.2 LRU 算法
LRU(Least recently used,最近最少使用),该算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。LRU算法的常见实现方式为链表,其基本思路是新数据插入到列表头部,每当缓存命中(即缓存数据被访问),则将数据移到列表头部。当列表满的时候,将列表尾部的数据丢弃。
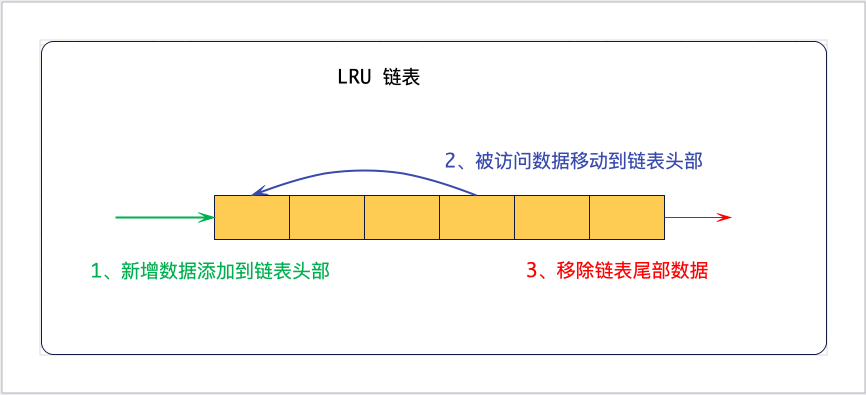
而在Redis中使用的是近似LRU算法,为什么说是近似呢?Redis中是随机采样5个key,然后从中选择访问时间最早的key进行淘汰,因此当采样key的数量与Redis库中key的数量越接近,淘汰的规则就越接近LRU算法。但官方推荐5个就足够了,最多不超过10个,越大就越消耗CPU的资源。

有一点需要特意说明下,在LRU算法下,如果一个热点数据最近很少访问,而非热点数据近期访问了,就会误把热点数据淘汰而留下了非热点数据,这种情况有可能会引起 Redis 缓存击穿。
3.3 LFU 算法
LFU(Least Frequently Used 最少频率使用),它是基于“如果一个数据在最近一段时间内使用次数很少,那么在将来一段时间内被使用的可能性也很小”的思路。LFU算法反映了一个key的热度情况,不会因LRU算法的偶尔一次被访问被误认为是热点数据。
LFU算法的常见实现方式为链表,其基本思路是新数据放在链表尾部 ,链表中的数据按照被访问次数降序排列,访问次数相同的按最近访问时间降序排列,链表满的时候从链表尾部移出数据。

结语
把今天最好的表现当作明天最新的起点…….~
投身于天地这熔炉,一个人可以被毁灭,但绝不会被打败!一旦决定了心中所想,便绝无动摇。迈向光明之路,注定荆棘丛生,自己选择的路,即使再荒谬、再艰难,跪着也要走下去!放弃,曾令人想要逃离,但绝境重生方为宿命。若结果并非所愿,那就在尘埃落定前奋力一搏!

这篇关于Redis进阶 - Redis 淘汰策略的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





