本文主要是介绍【LLM】PISSA:一种高效的微调方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
介绍PISSA前,先简单过一下LLMs微调经常采用的LoRA(Low-Rank Adaptation)微调的方法,LoRA 假设权重更新的过程中有一个较低的本征秩,对于预训练的权重参数矩阵 W 0 ∈ R d × k W_0 ∈ R^{d×k} W0∈Rd×k,( d d d 为上一层输出维度, k k k 为下一层输入维度),使用低秩分解来表示其更新:
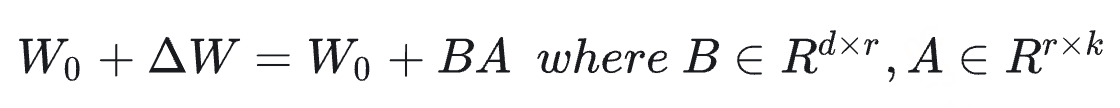
在训练过程中, W 0 W_0 W0冻结不更新, A A A、 B B B 包含可训练参数。
则 LoRA 的前向传递函数为:
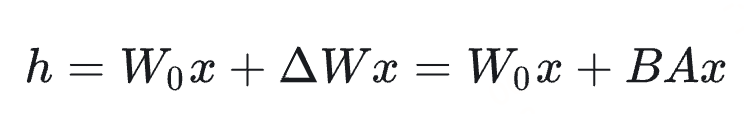
初始化时,常将低秩矩阵 A A A高斯初始化, B B B初始化为0。这样在训练初期AB接近于零,不会影响模型的输出。
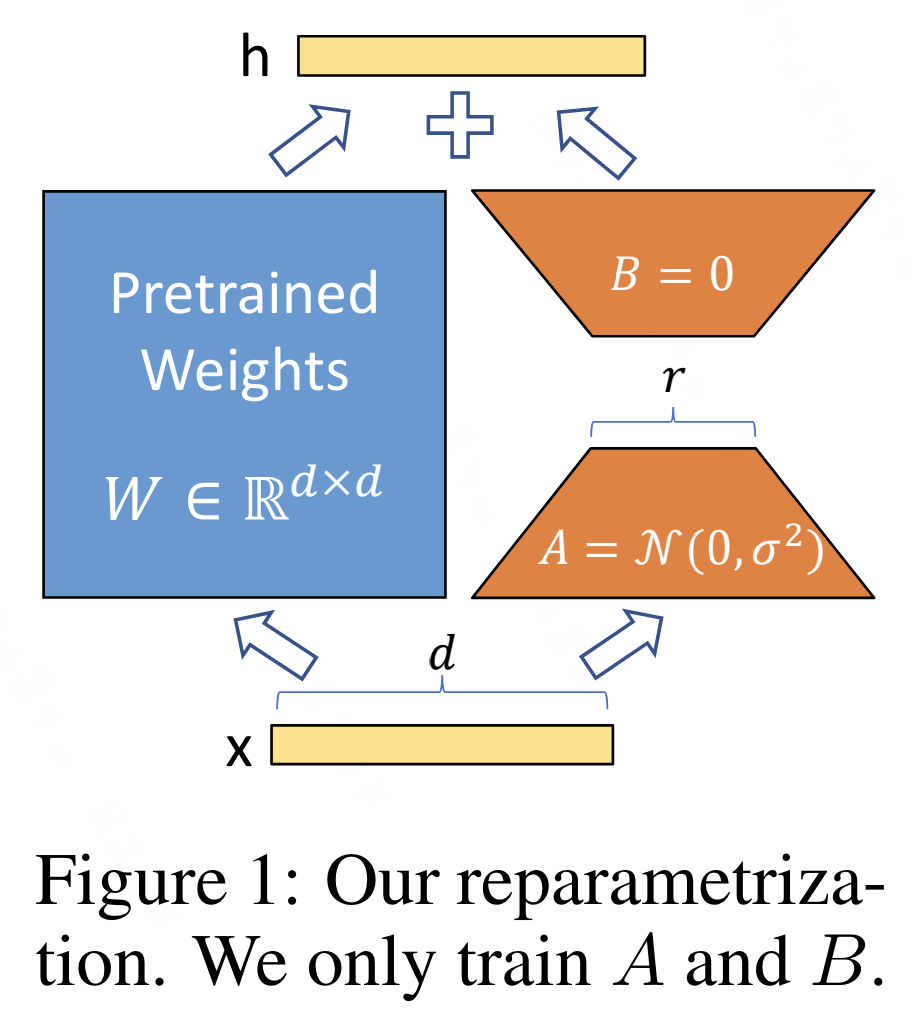
PISSA
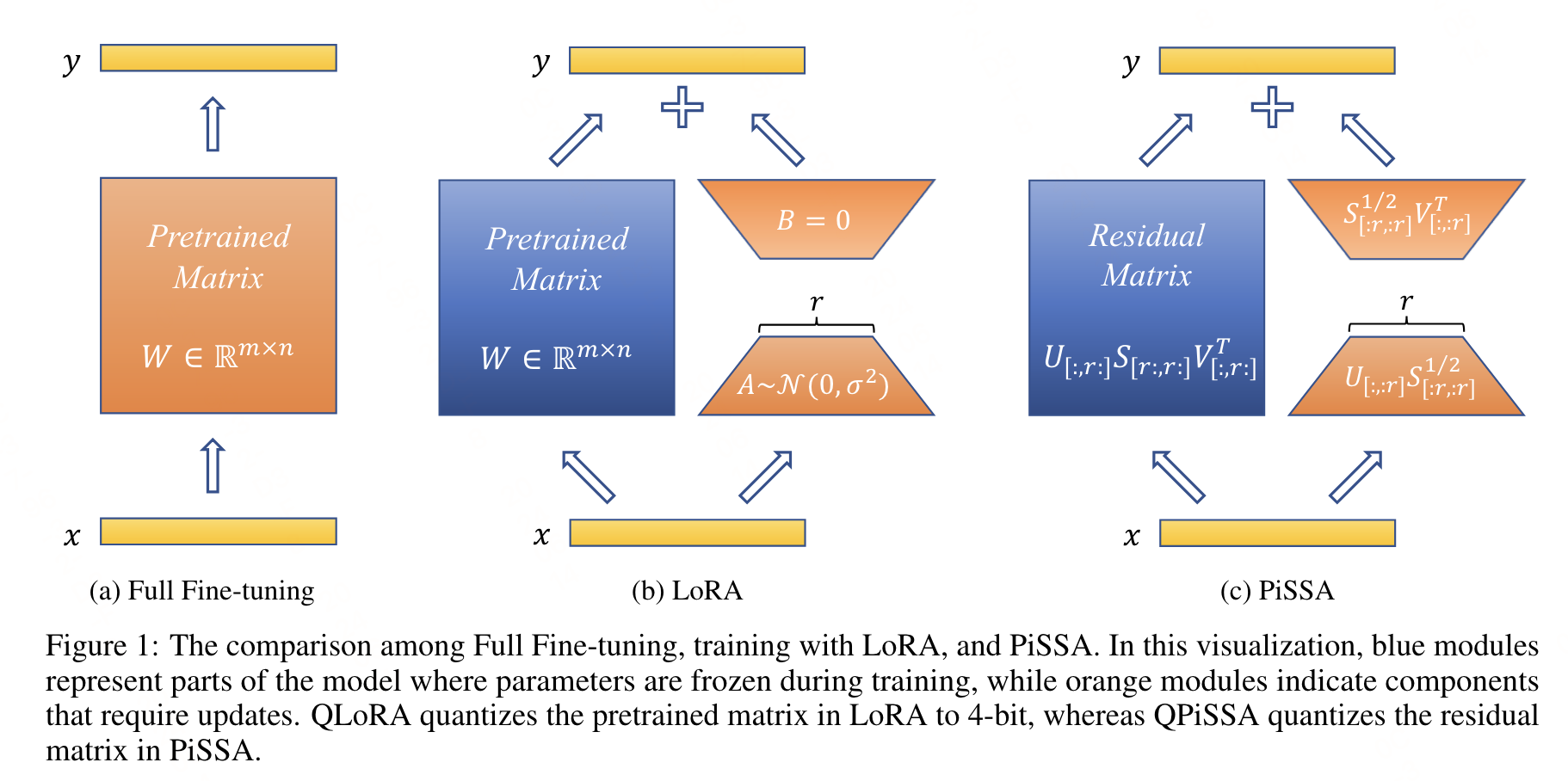
从图中可以看出,PISSA和LoRA主要的区别是初始化方式不同:
- LoRA:使用随机高斯分布初始化 A A A, B B B初始化为零。过程中只训练了低秩矩阵 A A A、 B B B。
- PISSA:同样基于低秩特性的假设,但PISSA不是去近似 ∆ W ∆W ∆W,而是直接对 W W W进行操作。PiSSA使用奇异值分解(SVD)将 W W W分解为两个矩阵 A A A和 B B B的乘积加上一个残差矩阵 W r e s W^{res} Wres。 A A A和 B B B使用 W W W的主奇异值和奇异向量进行初始化,而 W r e s W^{res} Wres则使用剩余的奇异值和奇异向量初始化,并在微调过程中保持不变。也就能保证初始化时和基座模型一样。因此,和LoRA一样,PISSA的训练中也只训练了低秩矩阵 A A A 和 B B B,而 W r e s W^{res} Wres保持冻结。
初始化A和B矩阵:使用主要的奇异值和奇异向量初始化两个可训练的矩阵:
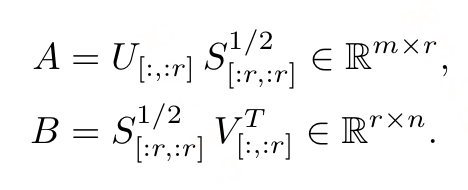
构建残差矩阵 W r e s W^{res} Wres:使用残差奇异值和奇异向量构建残差矩阵:
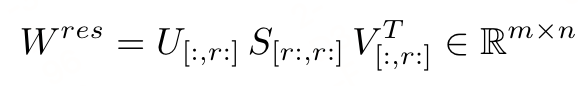
实验
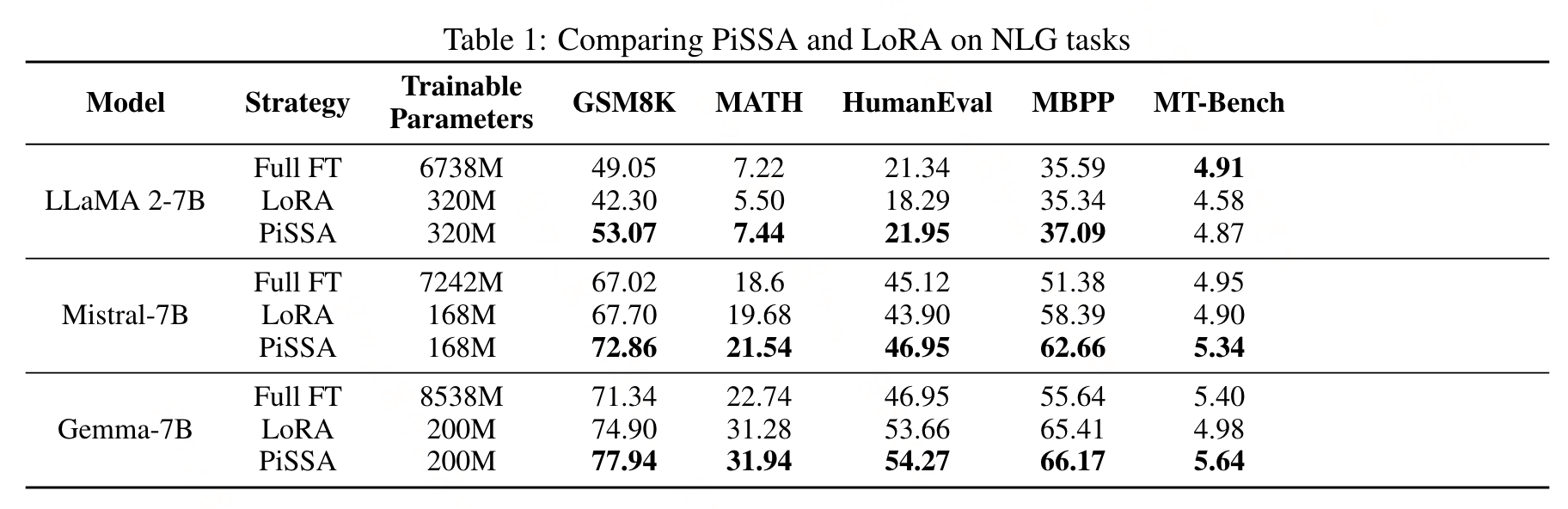
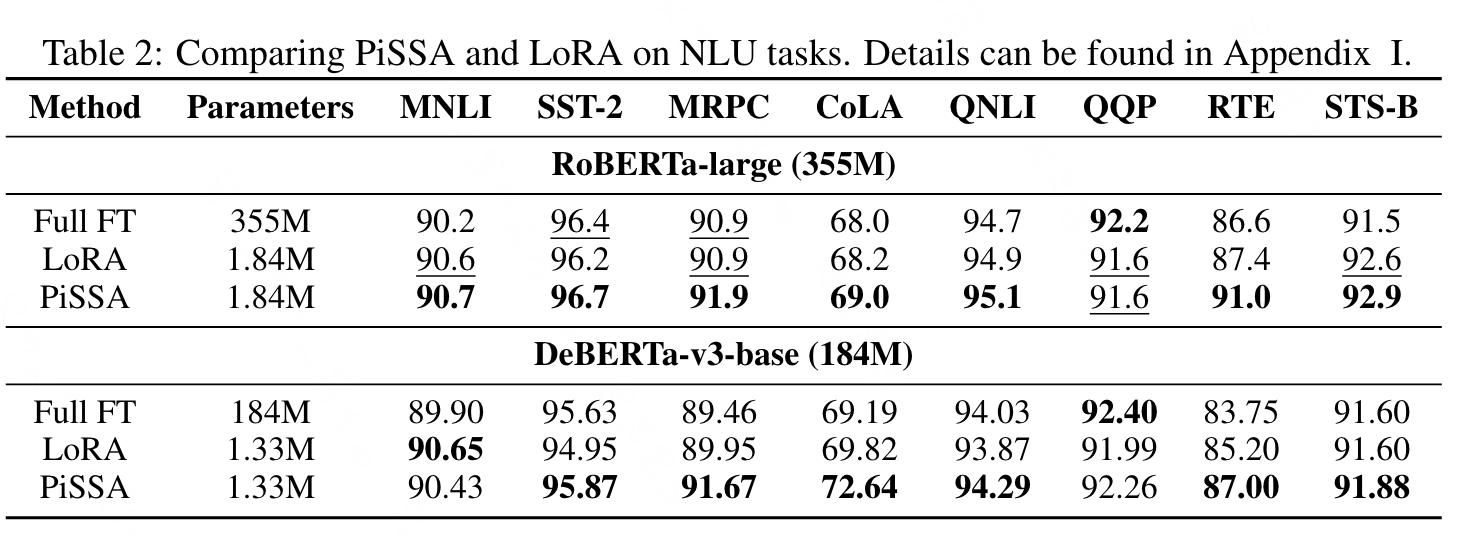
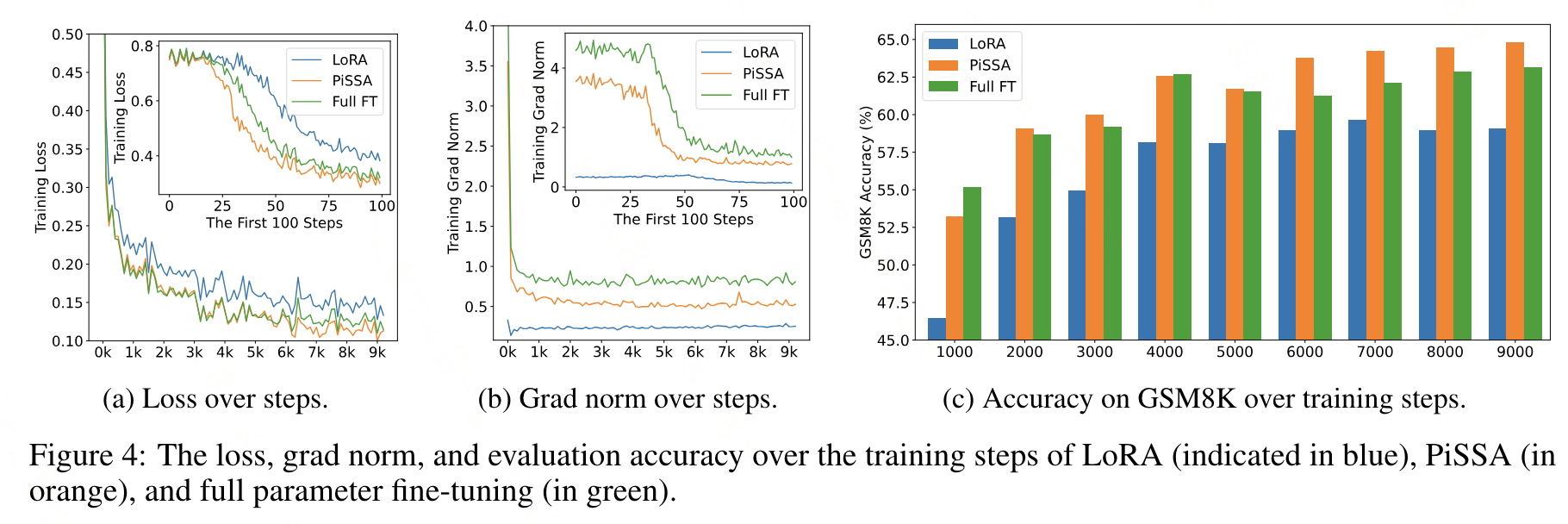
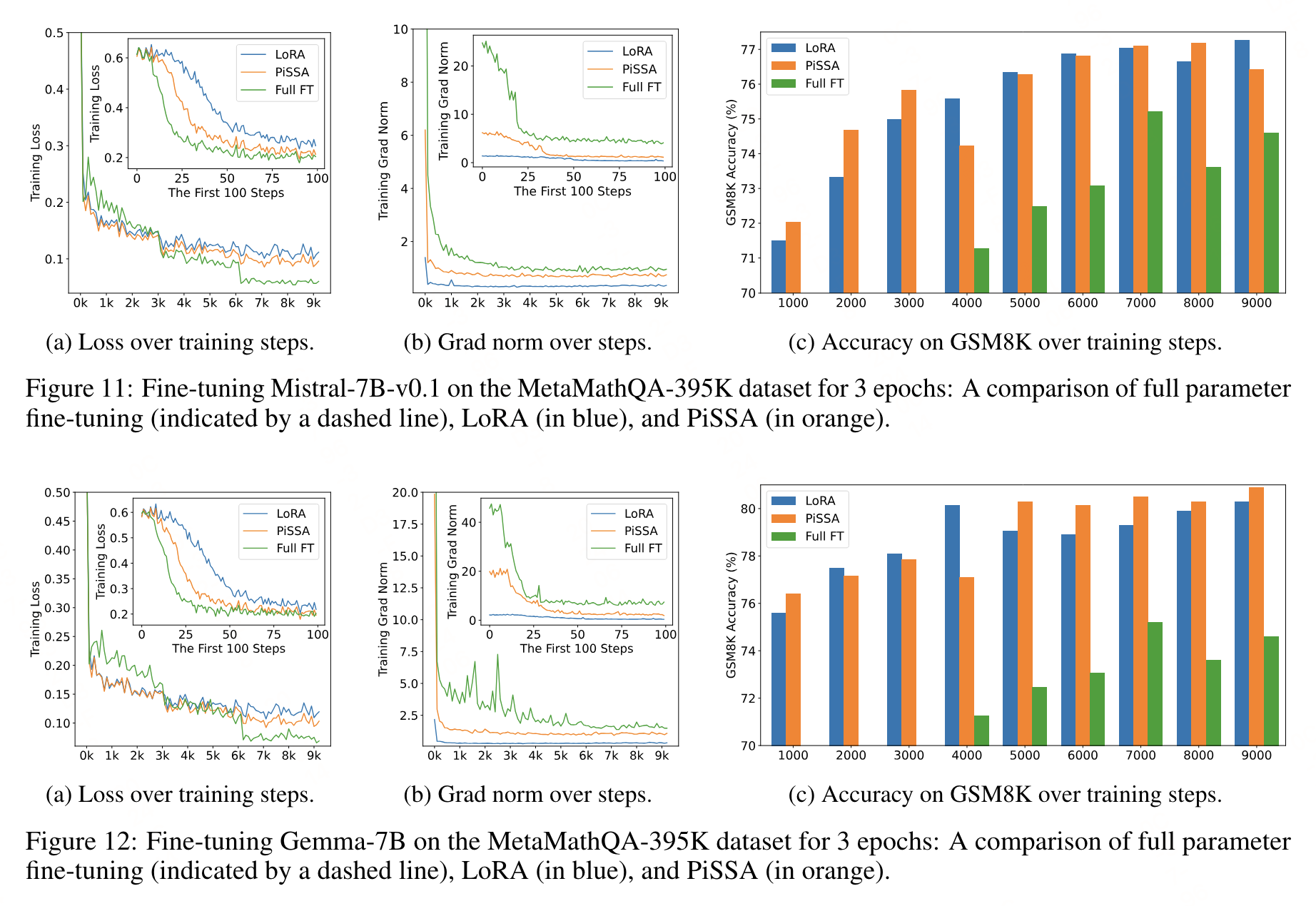
PISSA微调
import torch
from peft import LoraConfig, get_peft_model
from transformers import AutoTokenizer, AutoModelForCausalLM
from trl import SFTTrainer
from datasets import load_datasetmodel = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf", torch_dtype=torch.bfloat16, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf")
tokenizer.pad_token_id = tokenizer.eos_token_id
lora_config = LoraConfig(# init_lora_weights="pissa", # Configure the initialization method to "pissa", which may take several minutes to execute SVD on the pre-trained model.init_lora_weights="pissa_niter_4", # Initialize the PiSSA with fast SVD, which completes in just a few seconds.
)
peft_model = get_peft_model(model, lora_config)peft_model.print_trainable_parameters()dataset = load_dataset("imdb", split="train[:1%]")trainer = SFTTrainer(model=peft_model,train_dataset=dataset,dataset_text_field="text",max_seq_length=128,tokenizer=tokenizer,
)
trainer.train()
peft_model.save_pretrained("pissa-llama-2-7b")
pissa加载
import torch
from peft import PeftModel
from transformers import AutoModelForCausalLMmodel = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf", torch_dtype=torch.bfloat16, device_map="auto"
)
# Performs SVD again to initialize the residual model and loads the state_dict of the fine-tuned PiSSA modules.
peft_model = PeftModel.from_pretrained(model, "pissa-llama-2-7b")
将 PiSSA 转换为 LoRA
import torch
from peft import PeftModel
from transformers import AutoModelForCausalLMmodel = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf", torch_dtype=torch.bfloat16, device_map="auto"
)
# No SVD is performed during this step, and the base model remains unaltered.
peft_model = PeftModel.from_pretrained(model, "pissa-llama-2-7b-lora")
总结
PiSSA是一种高效的微调方法,它通过奇异值分解提取大型语言模型中的关键参数,并仅对这些参数进行更新,以实现与全参数微调相似的性能,同时显著降低计算成本和参数数量。
参考文献
- PISSA: PRINCIPAL SINGULAR VALUES AND SINGULAR VECTORS ADAPTATION OF LARGE LANGUAGE MODELS,https://arxiv.org/pdf/2404.02948
- https://github.com/GraphPKU/PiSSA
- LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS,https://arxiv.org/pdf/2106.09685
- https://github.com/microsoft/LoRA
这篇关于【LLM】PISSA:一种高效的微调方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





