本文主要是介绍7 数据预处理-数据标准化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据预处理-数据标准化
- 数据预处理-数据标准化
- 正规化 Normalization
- 例子1 - 数据标准化
- 例子2 - 数据标准化对机器学习成效的影响
- 正规化 Normalization
正规化 Normalization
这个文章知识讲解了入门的数据预处理,更多的归一化方法请看:
http://blog.csdn.net/u012052268/article/details/74028952 sklearn中常用数据预处理方法
由于资料的偏差与跨度会影响机器学习的成效,因此正规化(标准化)数据可以提升机器学习的成效。首先由例子来讲解:
- 例子1 - 数据标准化
- 例子2 - 数据标准化对机器学习成效的影响
例子1 - 数据标准化
#数据预处理模块
from sklearn import preprocessing
import numpy as np#建立Array
a = np.array([[10, 2.7, 3.6],[-100, 5, -2],[120, 20, 40]], dtype=np.float64)
#数据预处理模块 有一个方法:scale 归一化数据
print(preprocessing.scale(a))
# [[ 0. -0.85170713 -0.55138018]
# [-1.22474487 -0.55187146 -0.852133 ]
# [ 1.22474487 1.40357859 1.40351318]]# 或者是
print(preprocessing.minmax_scale(a,feature_range=(-1,1)))
'''
结果是:
[[ -2.77555756e-17 -1.00000000e+00 -7.33333333e-01][ -1.00000000e+00 -7.34104046e-01 -1.00000000e+00][ 1.00000000e+00 1.00000000e+00 1.00000000e+00]]
'''例子2 - 数据标准化对机器学习成效的影响
# 标准化数据模块
from sklearn import preprocessing
import numpy as np# 将资料分割成train与test的模块
frfrom sklearn.model_selection import train_test_split# 生成适合做classification资料的模块
from sklearn.datasets.samples_generator import make_classification # Support Vector Machine中的Support Vector Classifier
from sklearn.svm import SVC # 可视化数据的模块
import matplotlib.pyplot as plt #生成具有2种属性的300笔数据
X, y = make_classification(n_samples=300, n_features=2,n_redundant=0, n_informative=2, random_state=22, n_clusters_per_class=1, scale=100)
'''
参数的含义:
n_samples:样本数。
n_features:特征总数。
n_informative:信息特征的数量。
n_redundant:冗余特征数。
n_repeated:从信息和冗余特征中随机抽取的重复特征数。
n_classes:分类问题的类(或标号)的个数。
n_clusters_per_class:每个类的群集数。
random_state:随机数生成器使用的种子。
'''#可视化数据
plt.scatter(X[:, 0], X[:, 1], c=y)
plt.show()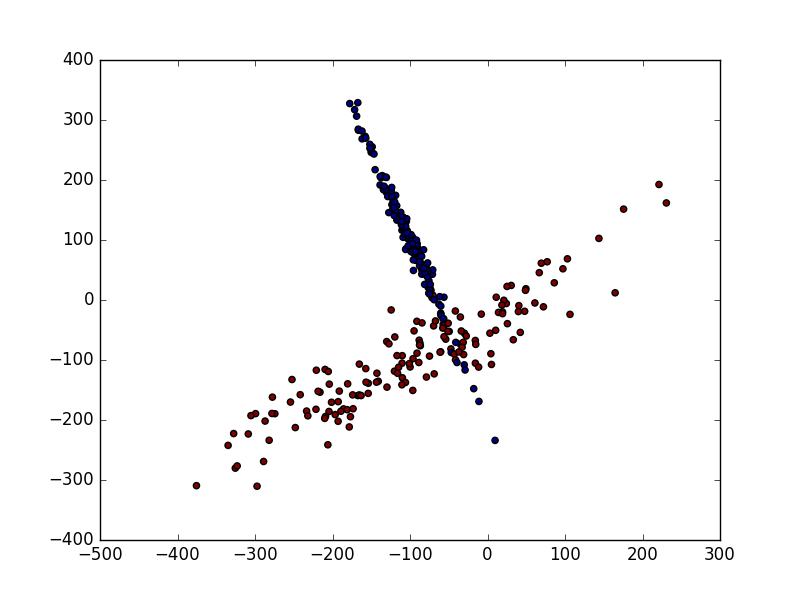
标准化前的预测准确率只有0.477777777778
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
clf = SVC()
clf.fit(X_train, y_train)
print(clf.score(X_test, y_test))
# 0.477777777778数据标准化后
数据的单位发生了变化, X 数据也被压缩到差不多大小范围.标准化后的预测准确率提升至0.9
X = preprocessing.scale(X)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
clf = SVC()
clf.fit(X_train, y_train)
print(clf.score(X_test, y_test))
# 0.9这篇关于7 数据预处理-数据标准化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




