本文主要是介绍深度学习 —— 1.单一神经元,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
深度学习初级课程
- 1.单一神经元
- 2.深度神经网络
- 3.随机梯度下降法
- 4.过拟合和欠拟合
- 5.剪枝、批量标准化
- 6.二分类
前言
本套课程仍为 kaggle 课程《Intro to Deep Learning》,仍按之前《机器学习》系列课程模式进行。前一系列《Keras入门教程》内容,与本系列有部分重复内容,但重点在于快速入门深度学习中的keras 使用,即从代码入手,快速掌握代码的使用,原理讲得很少。
从原理入手,一步一代码,如果进行建模型的整个过程。
内容
欢迎来到深度学习!
欢迎来到 kaggle 的深度学习课程介绍!你就要学会开始构建自己的深度神经网络所需的一切。使用Keras和Tensorflow,您将学习如何:
- 创建一个完全连接的神经网络架构
- 将神经网络应用于两个经典的机器学习问题:回归和分类
- 用随机梯度下降法训练神经网络,以及
- 通过剪枝、批量标准化和其他技术提高性能
什么是深度学习?
近年来,人工智能领域最令人印象深刻的一些进展是在深度学习领域。自然语言翻译、图像识别和游戏都是深度学习模型接近甚至超过人类水平的任务。
那么什么是深度学习呢?深度学习是一种机器学习方法,其特点是计算量大。这种计算深度使深度学习模型能够解开在最具挑战性的现实世界数据集中发现的各种复杂和分层模式。
神经网络凭借其强大的功能和可扩展性,已经成为深度学习的定义模型。神经网络由神经元组成,每个神经元单独执行一个简单的计算。神经网络的力量来自于这些神经元所能形成的复杂连接。
线性单位
让我们从神经网络的基本组成部分开始:单个神经元。如图所示,只有一个输入的神经元(或单元)如下所示:

线性单位:y = w x + b
输入是 x ,它与神经元的连接有一个权重(weight),即w 。每当一个值流经一个连接时,你就用该连接的权重乘以该值。对于输入x ,到达神经元的是w ∗ x 。神经网络通过修改其权重来“学习”。
b 是一种特殊的权重,我们称之为偏差(bias)。偏差没有任何与之相关的输入数据;相反,我们把1 放在图中,这样到达神经元的值就是b (因为1 ∗ b = b )。偏压使神经元能够独立于输入修改输出。
y是神经元最终输出的值。为了得到输出,神经元将通过其连接接收到的所有值相加。这个神经元的激活是y = w ∗ x + b ,或者用公式y = w x + b 。
公式 y = w x + b 看起来熟悉吗?
这是一个直线方程,这是斜率截距方程,其中w 是斜率,b 是y截距。
示例-线性单元作为模型
虽然单个神经元通常只作为更大网络的一部分发挥作用,但从单个神经元模型开始作为基线通常是有用的。单神经元模型就是线性模型。
让我们思考一下,这在80种谷物这样的数据集上是如何工作的。训练一个以“糖”(每份糖的克数)为输入,以“卡路里”(每份卡路里)为输出的模型,我们可能会发现偏差为 b = 90,重量为 w = 2.5。我们可以这样估计每餐含5克糖的谷物的卡路里含量:

而且,对照我们的配方,我们的卡路里 = 2.5 × 5 + 90 = 102.5 ,就像我们预期的那样。
多输入
80 谷物数据集的功能远不止“糖”。如果我们想把模型扩展到包括纤维或蛋白质含量这样的东西呢?这很容易。我们可以给神经元增加更多的输入连接,每增加一个功能就增加一个。为了找到输出,我们将每个输入乘以其连接权重,然后将它们相加。
三个输入连接:x 0 、x 1 和 x 2 ,以及偏置b。
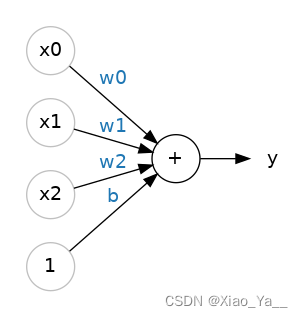
有三个输入的线性单元。
这个神经元的公式是y = w 0 x 0 + w 1 x 1 + w 2 x 2 + b 具有两个输入的线性单元将适合一个平面,而具有更多输入的单元将适合一个超平面。
Keras中的线性单位
在Keras中创建模型的最简单方法是通过Keras的 Sequential,它创建一个神经网络作为一个层堆栈。我们可以使用密集层(我们将在下一节中了解更多)创建类似上述模型的模型。
我们可以定义一个线性模型,接受三个输入特征(“糖sugars”、“纤维fiber”和“蛋白质protein”),并产生单一输出(“卡路里calories”),如下所示:
from tensorflow import keras
from tensorflow.keras import layers# Create a network with 1 linear unit
model = keras.Sequential([layers.Dense(units=1, input_shape=[3])
])
通过第一个参数units,我们定义了需要多少输出。在这种情况下,我们只是预测“卡路calories”,所以我们将使用units=1。对于第二个参数input_shape,我们告诉Keras输入的维度。设置input_shape=[3]可确保模型将接受三个特征作为输入(“糖”、“纤维”和“蛋白质”)。
这个模型现在可以适应训练数据了!
为什么input_shape是Python列表?
我们将在本课程中使用的数据是表格数据,比如熊猫数据框。对于数据集中的每个功能,我们将有一个输入。这些特性是按列排列的,所以我们总是有input_shape=[num_columns]。Keras在这里使用列表的原因是允许使用更复杂的数据集。例如,图像数据可能需要三个维度:[高度、宽度、通道]。
轮到你了
为红酒质量数据集定义一个线性模型。
练习部分
介绍
在教程中,我们学习了神经网络的构建模块:线性单元。我们看到,只有一个线性单元的模型将线性函数拟合到数据集(相当于线性回归)。在本练习中,您将构建一个线性模型,并在Keras中练习使用模型。
在开始之前,运行下面的代码单元来设置所有内容。
# Setup plotting
import matplotlib.pyplot as pltplt.style.use('seaborn-whitegrid')
# Set Matplotlib defaults
plt.rc('figure', autolayout=True)
plt.rc('axes', labelweight='bold', labelsize='large',titleweight='bold', titlesize=18, titlepad=10)# Setup feedback system
from learntools.core import binder
binder.bind(globals())
from learntools.deep_learning_intro.ex1 import *
红酒质量数据集由大约1600种葡萄牙红酒的理化测量数据组成。此外,还包括盲品测试中每种葡萄酒的质量评级。
首先,运行下一个单元格以显示此数据集的前几行。
import pandas as pd
red_wine = pd.read_csv('../input/dl-course-data/red-wine.csv')
red_wine.head()

可以使用shape属性获取数据帧(或Numpy数组)的行数和列数。
red_wine.shape # (rows, columns)
(1599, 12)
1) 输入维度
通过理化测量,我们能很好地预测葡萄酒的感知质量吗?
目标是“质量”,剩下的列是特性。在这项任务中,如何设置Keras模型的input_shape参数?
# YOUR CODE HERE
input_shape = ____# Check your answer
q_1.check()
2) 定义一个线性模型
现在定义一个适合此任务的线性模型。注意模型应该有多少输入和输出。
from tensorflow import keras
from tensorflow.keras import layers# YOUR CODE HERE
model = ____# Check your answer
q_2.check()
3) 查看权重
在内部,Keras用张量表示神经网络的权重。张量基本上是TensorFlow版本的Numpy数组,有一些差异使它们更适合深度学习。其中最重要的一点是张量与GPU(GPU)和TPU(TPU)加速器兼容。事实上,TPU是专门为张量计算而设计的。
模型的权重作为张量列表保存在其权重属性中。获取上面定义的模型的权重。
# YOUR CODE HERE
w, b = w, b = _____
# Check your answer
q_3.check()
Weights
<tf.Variable 'dense/kernel:0' shape=(11, 1) dtype=float32, numpy=
array([[ 0.54436415],[-0.14202559],[ 0.6889222 ],[ 0.2318945 ],[-0.6457067 ],[ 0.40594786],[ 0.04871047],[-0.20195675],[ 0.20735556],[ 0.13860786],[-0.18090099]], dtype=float32)>Bias
<tf.Variable 'dense/bias:0' shape=(1,) dtype=float32, numpy=array([0.], dtype=float32)>
正确:你看到每个输入都有一个权重(和一个偏差)了吗?但是请注意,权重值似乎没有任何模式。在训练模型之前,权重设置为随机数(偏差设置为0.0)。神经网络通过寻找更好的权值进行学习。
(顺便说一句,Keras将权重表示为张量,但也使用张量表示数据。当您设置input_shape参数时,您告诉Keras它应该为训练数据中的每个示例预期的数组维度。设置input_shape=[3]将创建一个接受长度为3的向量的网络,如[0.2,0.4,0.6])
可选:绘制未经训练的线性模型的输出
我们将在第5课中学习的这类问题是回归问题,目标是预测一些数值目标。回归问题就像“曲线拟合”问题:我们试图找到一条最适合数据的曲线。让我们看看线性模型产生的“曲线”。(你可能已经猜到这是一条线了!)
我们提到,在训练之前,模型的权重是随机设置的。运行下面的单元格几次,查看随机初始化生成的不同行。(这个练习没有编码——只是一个演示。)
import tensorflow as tf
import matplotlib.pyplot as pltmodel = keras.Sequential([layers.Dense(1, input_shape=[1]),
])x = tf.linspace(-1.0, 1.0, 100)
y = model.predict(x)plt.figure(dpi=100)
plt.plot(x, y, 'k')
plt.xlim(-1, 1)
plt.ylim(-1, 1)
plt.xlabel("Input: x")
plt.ylabel("Target y")
w, b = model.weights # you could also use model.get_weights() here
plt.title("Weight: {:0.2f}\nBias: {:0.2f}".format(w[0][0], b[0]))
plt.show()

继续前进
在第2课中添加隐藏层并使模型深入。
答案
# 1)输入维度
input_shape = [11]
# you could also use a 1-tuple, like input_shape = (11,)
# 也可以输入元组模式# 2)定义线性模型
from tensorflow import keras
from tensorflow.keras import layersmodel = keras.Sequential([layers.Dense(units=1, input_shape=[11])
])# 3)查看权重
w, b = model.weights
print("Weights\n{}\n\nBias\n{}".format(w, b))
这篇关于深度学习 —— 1.单一神经元的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



