本文主要是介绍redis哨兵集群高可用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 Redis的分片技术
1.1 分片介绍
1.1.1 传统方式的问题
说明:如果采用单台redis时,如果redis出现宕机现象.那么会直接影响我们的整个的服务.
1.1.2 采用分片模式
说明:由一台redis扩展到多台redis.由多台redis共同为用户提供服务.并且每台redis中保存1/N的数据.
好处:如果一台redis出现了问题.不会影响整个redis的服务.
1.1.3 配置多台redis
说明:将redis.conf文件拷贝3份到shard文件夹下.分别形成6379/6380/6381的文件
cp redis.conf shard/redis-6379.conf
1.1.4 修改端口
1.将端口改为6380

2.将端口号为6381
1.1.5 启动多台redis
redis-server redis-6379.conf
redis-server redis-6380.conf
redis-server redis-6381.conf
- 进入客户端
redis-cli -p 6380
- 关闭客户端
redis-cli -p 6380 shutdown
1.1.6 分片测试
@Testpublic void test02(){/*** 定义分片的连接池* 参数介绍* 1.poolConfig 定义链接池的大小* 2.shards 表示List<Shardinfo> 表示redis的信息的集合* * 补充知识:* Jedis 引入会有线程安全性问题.所以通过线程池的方式动态获取* jedis链接.*///定义链接池大小JedisPoolConfig poolConfig = new JedisPoolConfig();poolConfig.setMaxTotal(1000);poolConfig.setTestOnBorrow(true);//测试链接是否正常,如果不正常会重新获取poolConfig.setMaxIdle(30);//定义分片的list集合List<JedisShardInfo> shards = new ArrayList<JedisShardInfo>();shards.add(new JedisShardInfo("192.168.126.142",6379));shards.add(new JedisShardInfo("192.168.126.142",6380));shards.add(new JedisShardInfo("192.168.126.142",6381));ShardedJedisPool jedisPool = new ShardedJedisPool(poolConfig, shards);//获取redis的链接ShardedJedis jedis = jedisPool.getResource();for(int i=1;i<=20;i++){jedis.set("KEY"+i, ""+i);}System.out.println("redis插入操作成功!!!");}1.2 Redis分片的算法介绍
1.2.1 哈希一致性算法
说明:根据节点的信息进行哈希计算计算的结果在0-2^32-1 的范围内.计算完成之后能够进行动态的节点的挂载
特点:
- 均衡性
a) 尽可能的让数据均衡的落入缓存区
- 单调性
a) 如果数据已经进行了动态的分配.如果有新节点引入能够进行动态的分配.
- 分散性
a) 由于分布式开发,用户不能看到缓存的全部.那么数据计算的结果能位置不固定.好的哈希一致性算法应该尽可能的降低分散性
- 负载
a) 从另一个角度研究分散性.由于用户不能看到缓存区的全部,经过计算后,同一个缓存区可以会有多个数据.这样的方式不是特别的友好,所以高级的哈希算法应该尽可能降低负载.
1.2.2 图示
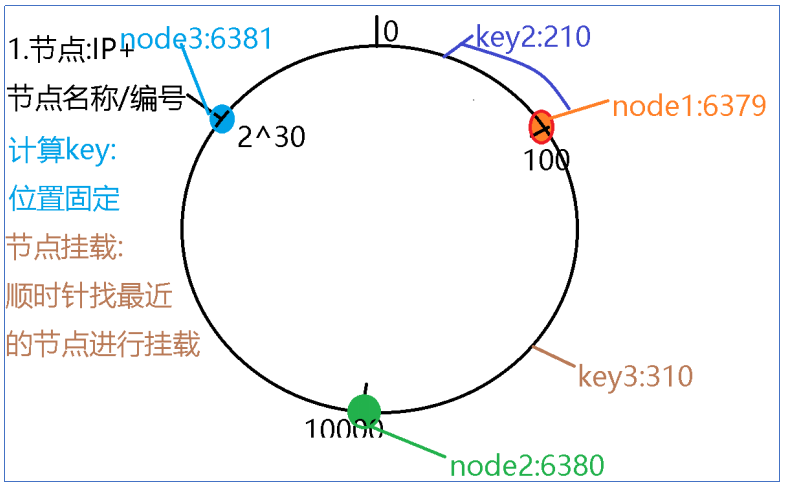
说明:
- 通过节点的ip+编号通过hash运算,算出具体的位置
- 如果需要进行key的存储.首先根据key值进行计算,找到位置,之后进行数据的存储
- 按照顺时针的方向,数据找最近的节点进行挂载.
- 取数据时通过node信息.获取数据.
- 以上的节点(node)信息都是动态的
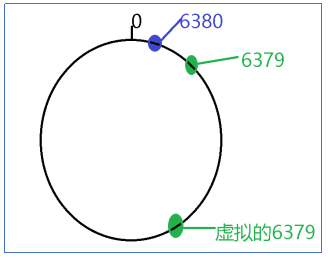
1.2.3 均衡性
说明:由于哈希计算可能会出现节点位置较近的现象.通过均衡性中虚拟节点.尽可能的让数据达到平均
1.2.4 单调性
说明:由于node节点信息可能会出现变化,数据可以动态的挂载到新的节点中.
如果节点需要删除.那么该节点中的数据会动态的挂载到新的节点中,保证数据是有效的

1.2.5 分散性
说明:由于采用了分布式的部署,某些用户不能够看到全部的缓存区(node)节点信息.这时在进行数据操作时,可会出现同一key位于不同的位置.
1.2.6 负载
说明:从另外的一个角度考虑分散性.同一个位置.可以存放不同的key
要求:好的hash算法应该尽可能的降低分散性和负载.
1.3 Spring的方式整合分片
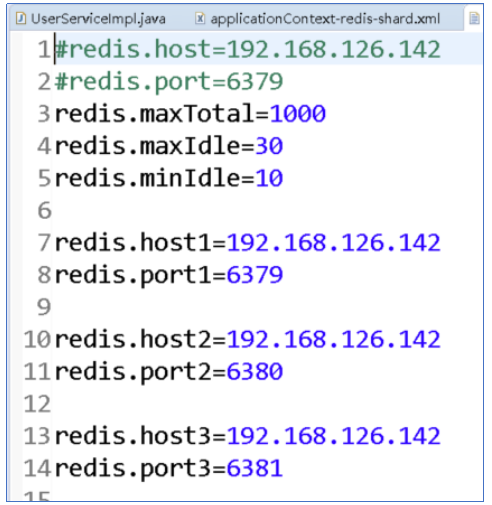
1.3.1 编辑配置文件
说明:将原有redis的配置文件改名,为了不让Spring容器扫描解析出错.
图上的配置文件保留原有的配置前边多加字母A.可以保证spring容器不会加载该配置
<!--通过线程池的方式整合单台redis --><bean id="poolConfig" class="redis.clients.jedis.JedisPoolConfig"><!--定义连接的总数 --><property name="maxTotal" value="${redis.maxTotal}"/><!--定义最大的空闲数量 --><property name="maxIdle" value="${redis.maxIdle}"/><!--定义最小空闲数量 --><property name="minIdle" value="${redis.minIdle}"></property></bean><!--List<JedisShardInfo> shards = new ArrayList<JedisShardInfo>();shards.add(new JedisShardInfo("192.168.126.142",6379));shards.add(new JedisShardInfo("192.168.126.142",6380));shards.add(new JedisShardInfo("192.168.126.142",6381));ShardedJedisPool jedisPool = new ShardedJedisPool(poolConfig, shards);--><!--定义jediShardinfo对象 --><bean id="host1" class="redis.clients.jedis.JedisShardInfo"><constructor-arg index="0" value="${redis.host1}" type="java.lang.String"/><constructor-arg index="1" value="${redis.port1}" type="int"/></bean><bean id="host2" class="redis.clients.jedis.JedisShardInfo"><constructor-arg index="0" value="${redis.host2}" type="java.lang.String"/><constructor-arg index="1" value="${redis.port2}" type="int"/></bean><bean id="host3" class="redis.clients.jedis.JedisShardInfo"><constructor-arg index="0" value="${redis.host3}" type="java.lang.String"/><constructor-arg index="1" value="${redis.port3}" type="int"/></bean><bean id="shardedJedisPool" class="redis.clients.jedis.ShardedJedisPool"><constructor-arg index="0" ref="poolConfig" /><constructor-arg index="1"><list><ref bean="host1"/><ref bean="host2"/><ref bean="host3"/></list></constructor-arg></bean>1.3.2 编辑redis.properties
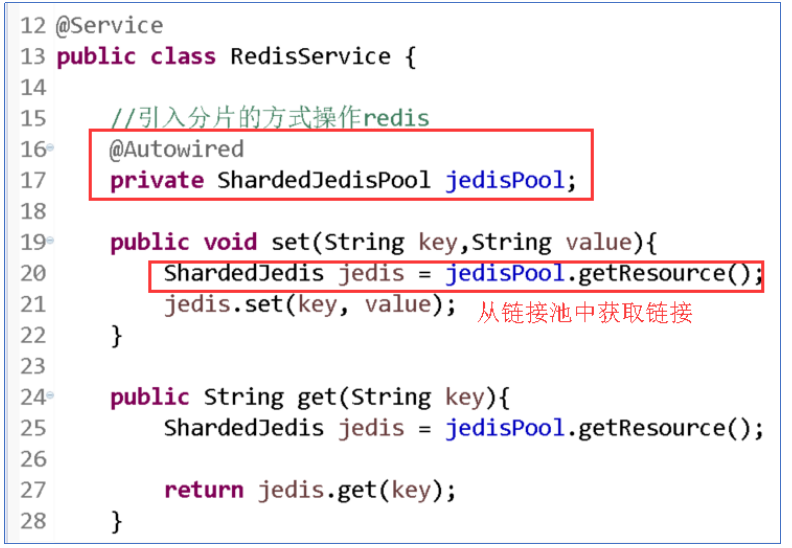
1.3.3 编辑RedisService
1.3.4 编辑业务层Service
说明:ItemCatService中通过Spring依赖注入的形式进行赋值.所以不需要修改.
思想(面向接口编程的好处)
2 Redis哨兵
2.1 搭建主从结构
2.1.1 配置主从
说明:配置主从时需要启动主从的redis节点信息.之后进行主从挂载.
2.1.2 主从挂载
- 复制新的配置文件,后重新启动新的redis节点信息
- 查询节点的状态
127.0.0.1:6380> info replication
实现挂载
127.0.0.1:6380> SLAVEOF 192.168.126.142 6379
通过该命令实现挂载
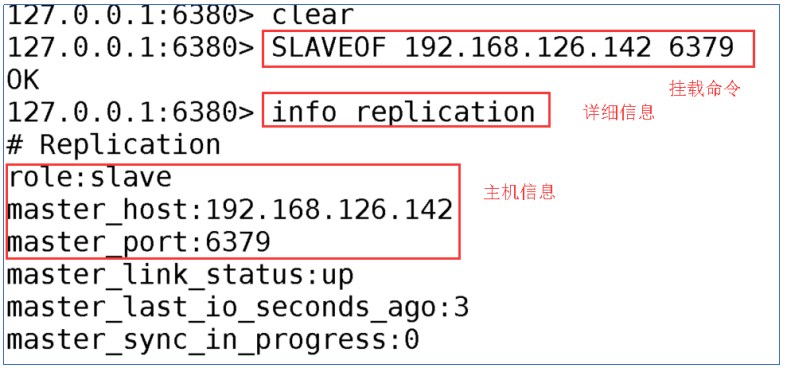
- 将6381挂载到6379中
SLAVEOF 192.168.126.142 6379
2.1.3 主从测试
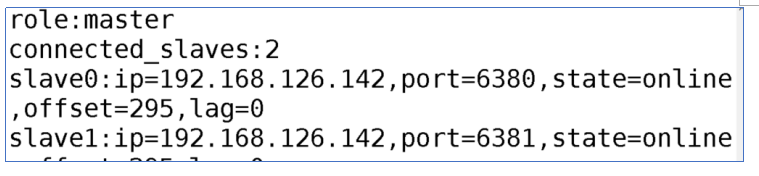
说明:通过6379查询info信息.并且通过set命令为6379赋值后检测从机中是否含有数据.
2.1.4 哨兵的原理

工作原理:
1.用户链接时先通过哨兵获取主机Master的信息
2.获取Master的链接后实现redis的操作(set/get)
3.当master出现宕机时,哨兵的心跳检测发现主机长时间没有响应.这时哨兵会进行推选.推选出新的主机完成任务.
4.当新的主机出现时,其余的全部机器都充当该主机的从机
2.1.5 哨兵的配置
1.将保护模式关闭

2.配置哨兵的监控
sentinel monitor mymaster 192.168.126.142 6379 1
mymaster:主机的名称
192.168.126.142:主机的IP
6379 :表示主机的端口号
1:表示有几个哨兵选举后生效
3修改时间
说明:当10秒后主机没有响应则选举新的主机

4.修改推选时间

2.1.6 启动哨兵
说明:当启动哨兵后,由于没有后台启动所以需要重新开启连接进行测试
redis-sentinel sentinel-6379.conf

将redis主机宕机后检测哨兵是否工作
测试结果.当redis主机宕机后,哨兵自动选举出新的主机
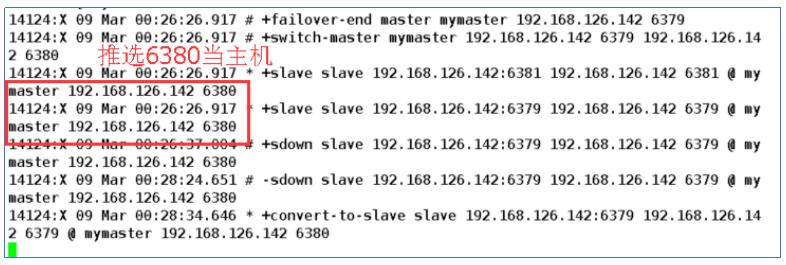
检测6380是否为主机 info replication

2.1.7 多台哨兵测试
1.哨兵编译后的文件
cp sentinel-6379.conf sentinel-6380.conf
- 修改端口

- 修改序列号
说明:由于哨兵启动时会自动的生成序列号.序列号相同时哨兵不能相互通讯.所以修改为不同的
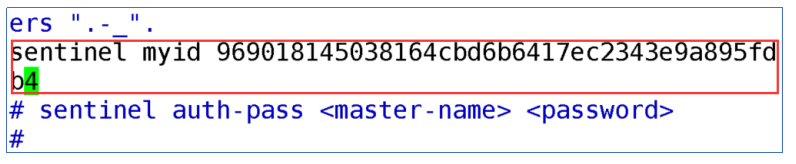
- 修改哨兵的个数

2.1.8 多台哨兵测试
说明:关闭redis主机后,检测哨兵是否能够生效,选举新的主机.如果能够选举新的主机表示多台哨兵搭建完成.
2.1.9 测试报错
说明:由于配置了哨兵,redis中配置了主从结构.所以从机不能进行写库操作,.如需测试分片需要关闭redis重新开启分片的redis

2.2 Spring整合哨兵
2.2.1 测试用例
//哨兵的测试@Testpublic void test03(){//创建哨兵的连接池//String类型表示的是哨兵的IP:端口号Set<String> sentinels = new HashSet<String>();String msg = new HostAndPort("192.168.126.142",26379).toString();System.out.println("通过对象输出哨兵的信息格式:"+msg);//为set集合赋值 保存全部的哨兵信息sentinels.add(new HostAndPort("192.168.126.142",26379).toString());sentinels.add(new HostAndPort("192.168.126.142",26380).toString());sentinels.add(new HostAndPort("192.168.126.142",26381).toString());/*** 参数介绍* 1.masterName 表示链接哨兵的主机的名称一般是字符串mymaster* 2.sentinels 哨兵的集合Set<>*/JedisSentinelPool sentinelPool = new JedisSentinelPool("mymaster", sentinels);Jedis jedis = sentinelPool.getResource();jedis.set("name", "tom");System.out.println("获取数据:"+jedis.get("name"));}2.3 Spring整合哨兵
2.3.1 编辑配置文件
<bean id="jedisSentinelPool" class="redis.clients.jedis.JedisSentinelPool"><constructor-arg index="0" value="${redis.masterName}"/><constructor-arg index="1"><set><value>${redis.sentinel.host1}</value><value>${redis.sentinel.host2}</value><value>${redis.sentinel.host3}</value></set></constructor-arg></bean>2.3.2 配置哨兵的配置文件
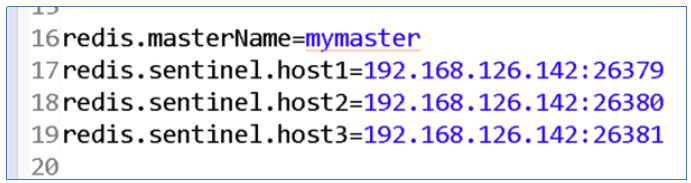
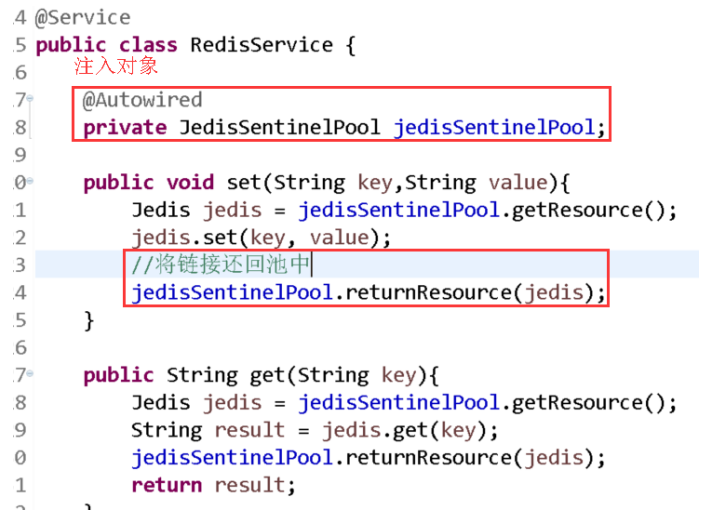
2.3.3 编辑工具类代码
说明:在工具类中定义方法.之后测试查看效果
这篇关于redis哨兵集群高可用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





