本文主要是介绍2007年-2021年 281个地级市-绿色创新效率相关数据收集,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
绿色创新效率是一个重要的概念,它涉及到在生产和消费过程中通过技术创新和管理创新来提高资源的利用效率,降低生产成本,减少对环境的负面影响,进而促进经济的可持续发展。这种效率的提升对企业、环境和社会都有积极的影响:
1. **经济效益**:绿色创新有助于降低企业的生产成本,提高其经济效益,从而增强市场竞争力。
2. **环境保护**:通过减少环境污染,绿色创新有助于保护生态环境,促进生态文明建设和社会的可持续发展。
3. **科技进步**:绿色创新推动科技进步和创新,提升整个社会的生产效率和生活质量。
数据集名称为“281个地级市-绿色创新效率相关数据”,涵盖了2007年至2021年的数据,为研究者提供了丰富的信息资源。这些数据由相关领域的学者整理,并在以下文献中有所引用:
- 王洪庆, 郝雯雯. 高新技术产业集聚对我国绿色创新效率的影响研究. 中国软科学, 2022, (08): 172-183.
- 王晗, 何枭吟, 许舜威. 创新型城市试点对绿色创新效率的影响机制. 中国人口·资源与环境, 2022, 32 (04): 105-114.
- 董会忠, 李旋, 张仁杰. 粤港澳大湾区绿色创新效率时空特征及驱动因素分析. 经济地理, 2021, 41 (05): 134-144.
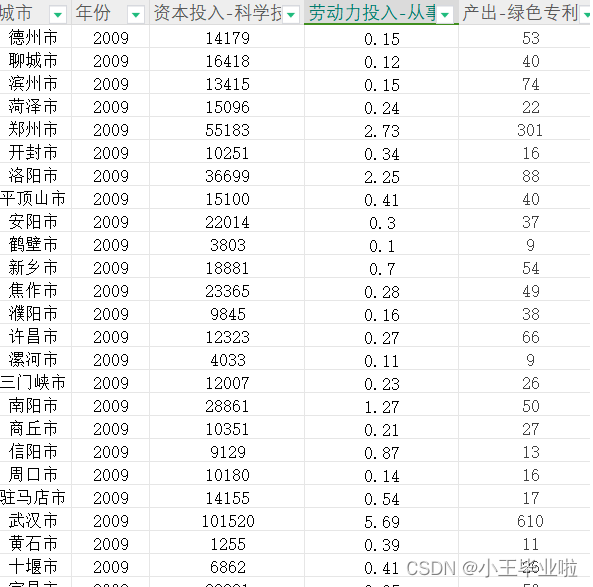
数据集包含的关键指标如下:
- **城市**:数据所涉及的城市名称。
- **年份**:数据记录的具体年份。
- **资本投入**:科学技术支出,单位为万元。
- **劳动力投入**:从事科技活动的从业人员数量,单位为万人。
- **产出**:绿色专利授权数,以项计。
- **环境污染综合指数**:采用熵值法计算的环境污染综合指数。
- **环境产出**:包括废水排放量(单位:万吨)、SO2排放量(单位:万吨)、烟粉尘排放量(单位:万吨)。
- **绿色创新效率**:衡量城市绿色创新效率的指标。
这些指标共同构成了评估城市绿色创新效率的多维度数据框架,有助于分析和理解不同城市在绿色创新方面的表现和潜力。通过这些数据,研究者可以深入探讨绿色创新效率的影响因素,以及如何通过政策和技术创新来提升城市的绿色发展水平。
https://download.csdn.net/download/2401_84585615/89462325
这篇关于2007年-2021年 281个地级市-绿色创新效率相关数据收集的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






