本文主要是介绍项目经验——交通行业数据可视化大屏、HMI设计,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
交通行业数据大屏、HMI设计时要的注意点:清晰可读、简洁直观、适配性强。颜色对比度满足WCAG标准,深色背景减少干扰,实时展示交通数据,支持有线网络控制内容更新,保障驾驶安全与决策效率。
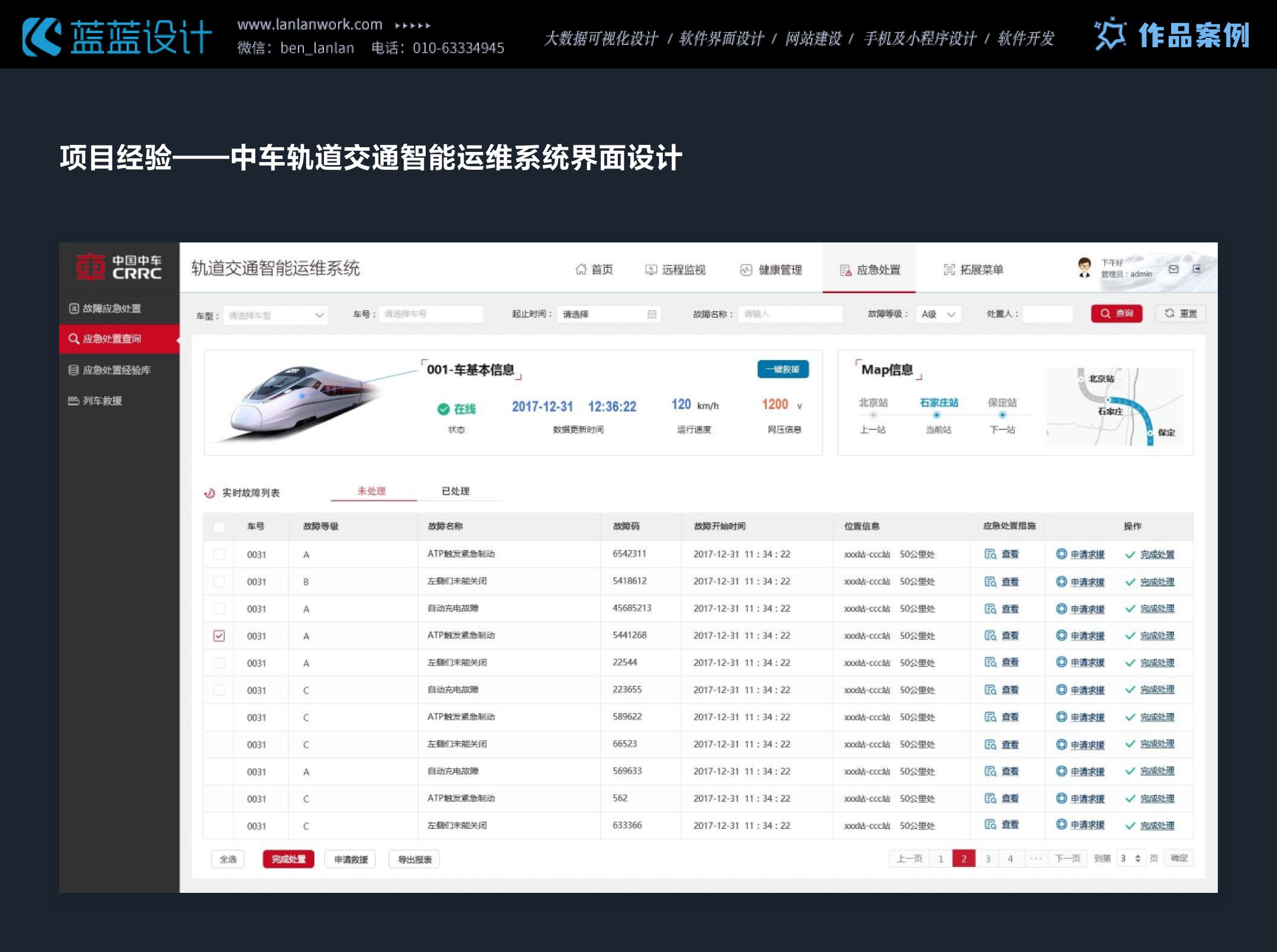
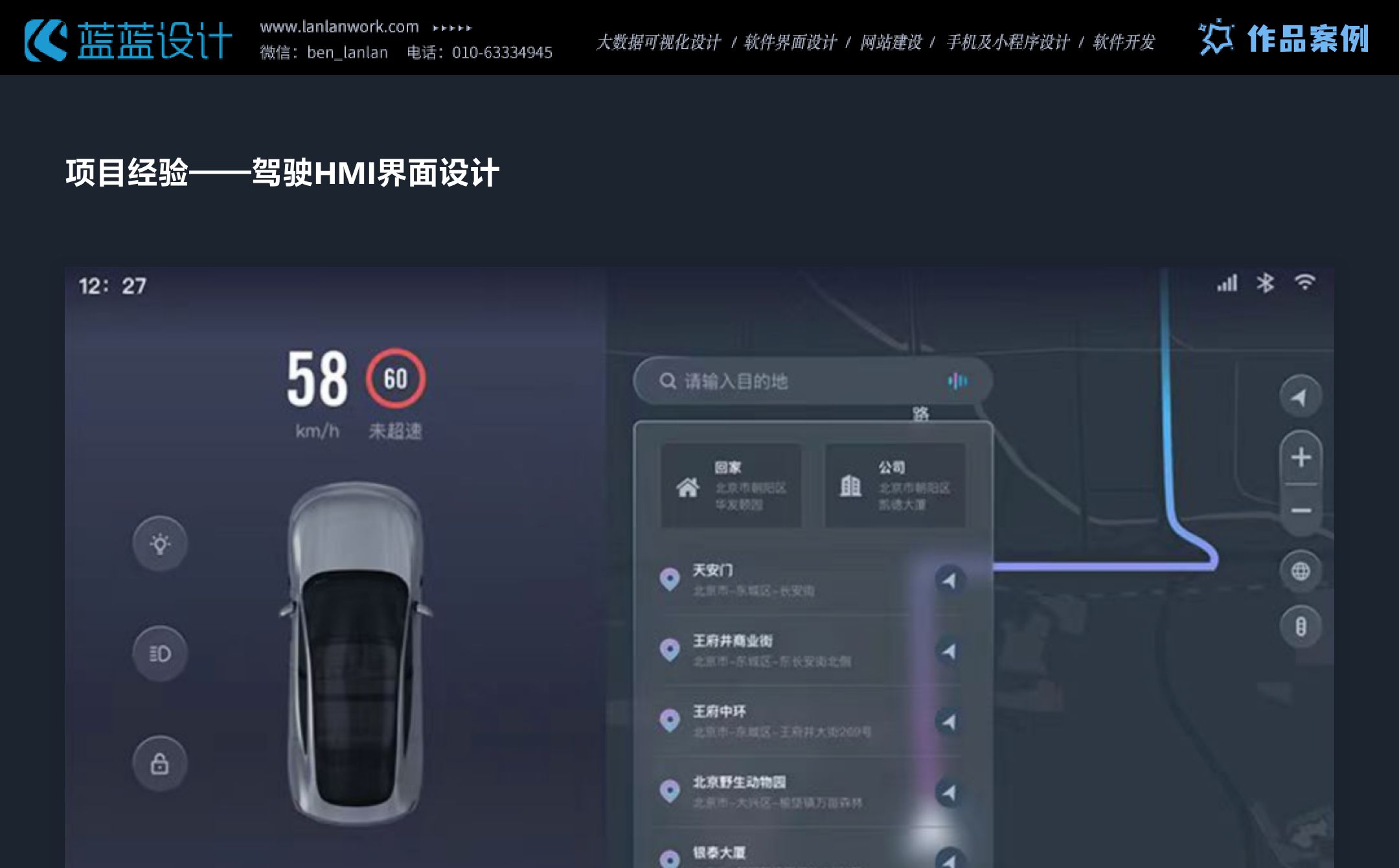
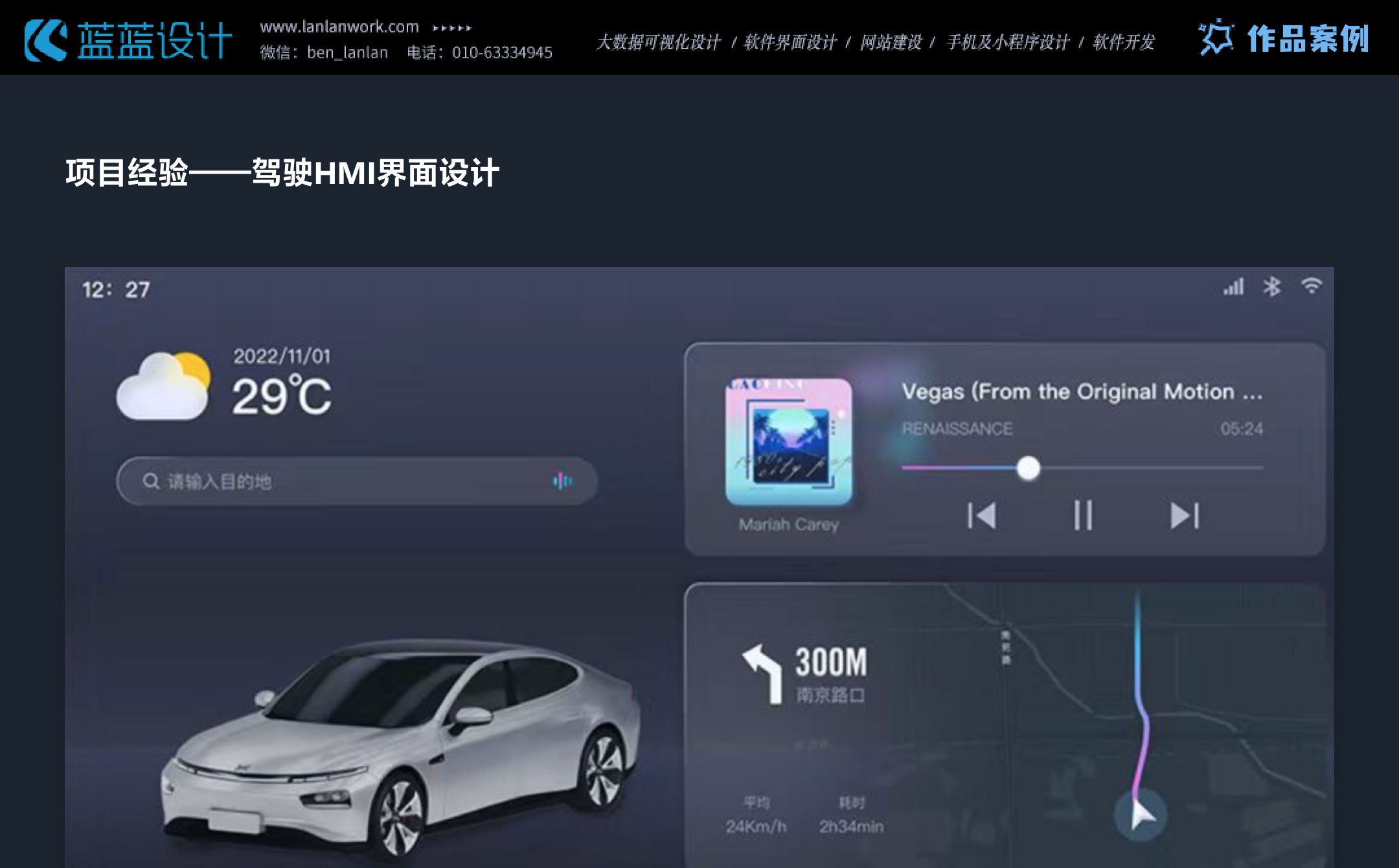
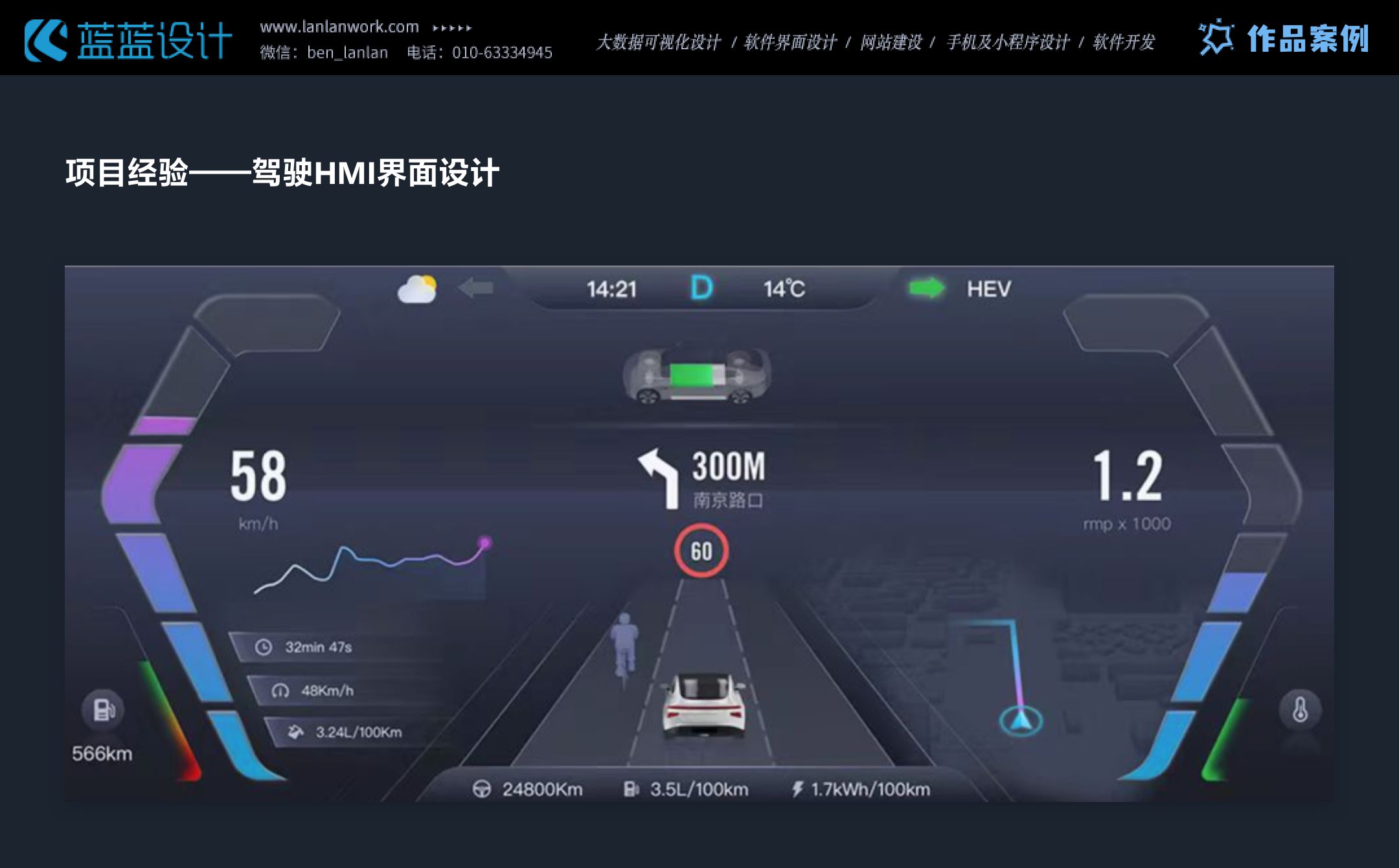
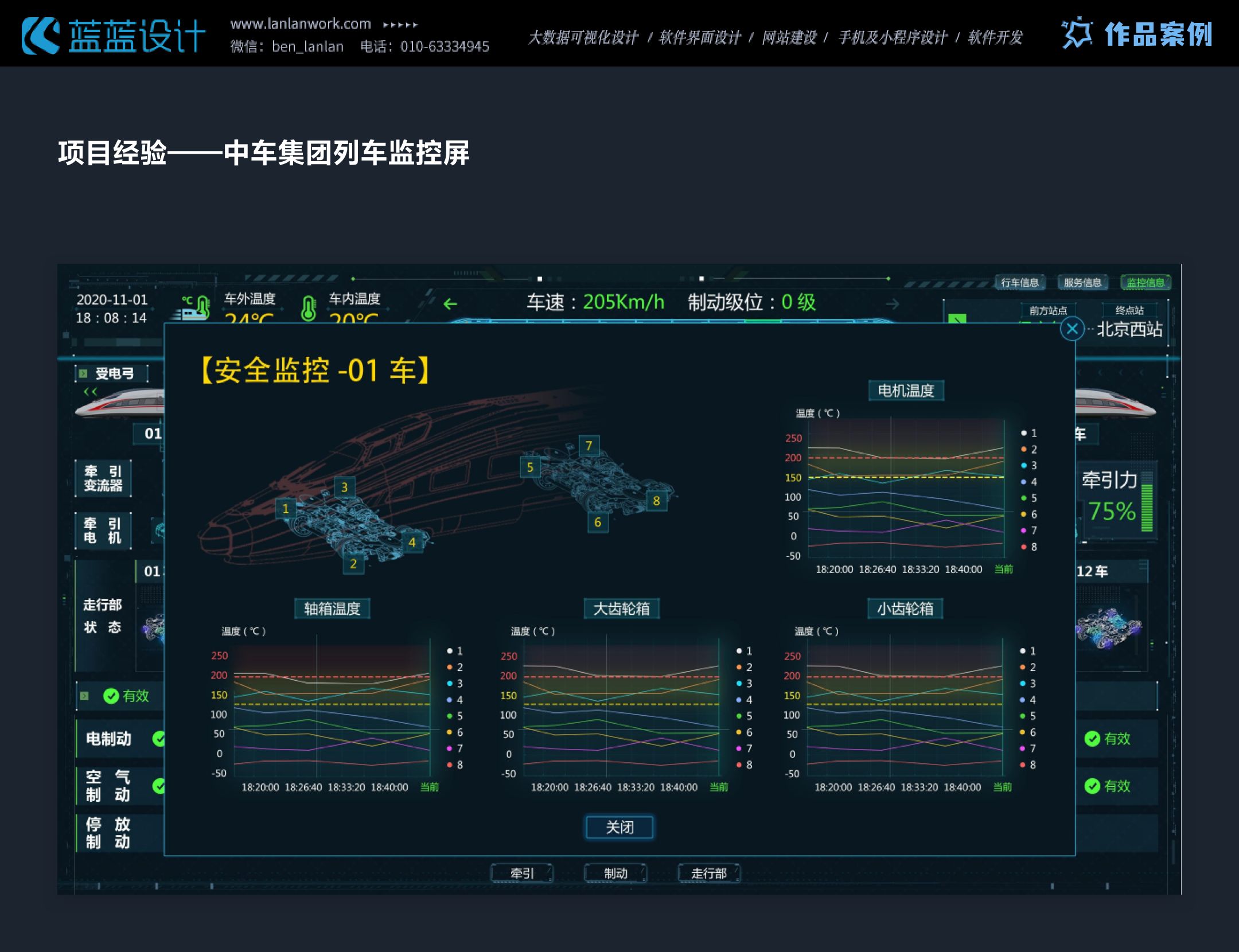

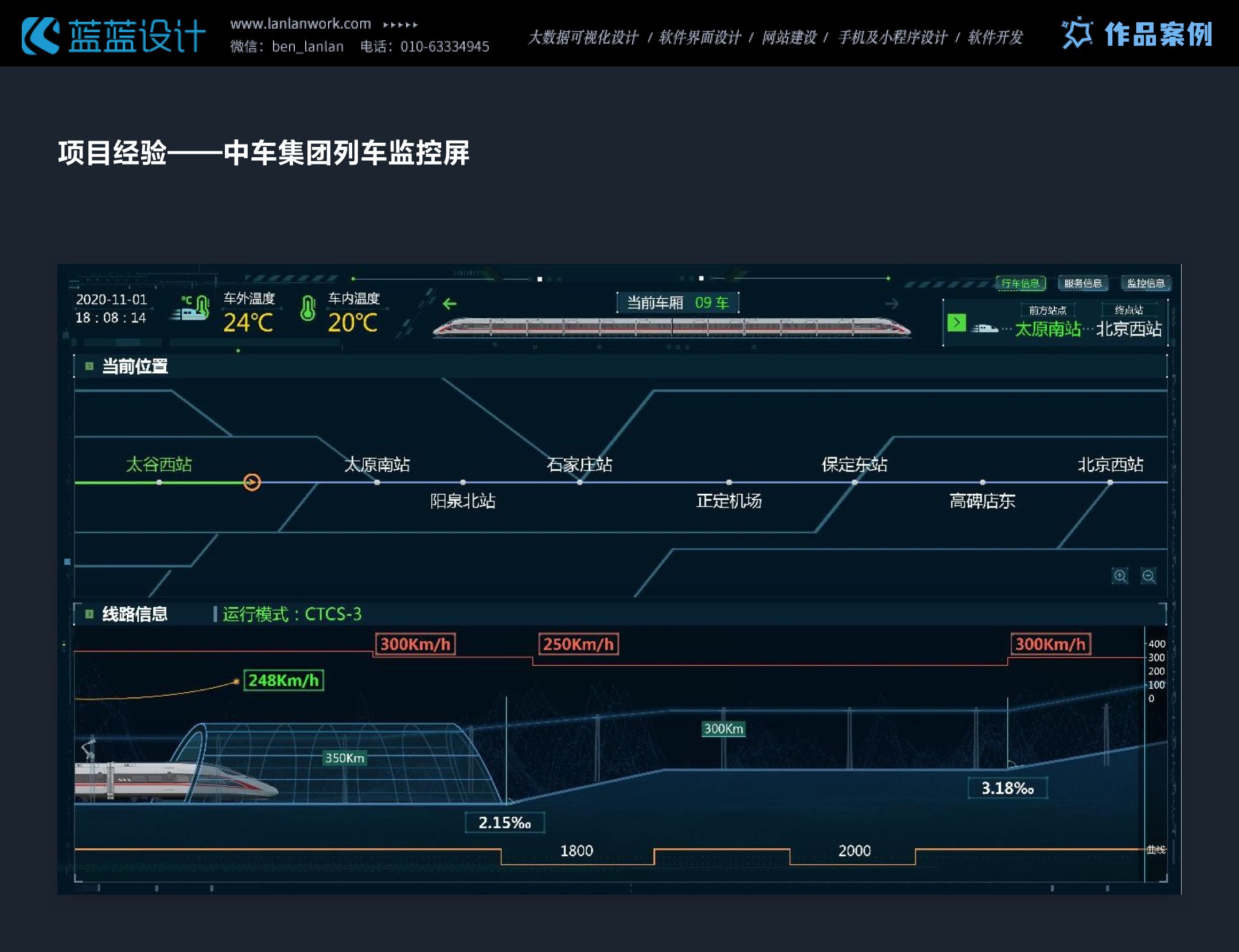
这篇关于项目经验——交通行业数据可视化大屏、HMI设计的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!
本文主要是介绍项目经验——交通行业数据可视化大屏、HMI设计,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
交通行业数据大屏、HMI设计时要的注意点:清晰可读、简洁直观、适配性强。颜色对比度满足WCAG标准,深色背景减少干扰,实时展示交通数据,支持有线网络控制内容更新,保障驾驶安全与决策效率。
这篇关于项目经验——交通行业数据可视化大屏、HMI设计的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!
http://www.chinasem.cn/article/1082158。
23002807@qq.com






