本文主要是介绍R语言——数据结构与数据处理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、练习使用seq( )函数创建向量:使用3种方法生成0~1,步长为0.1的向量,并在控制台打印出来。
2、练习使用rep( )函数创建向量:(1)生成一个4个元素均为3的向量;(2)生成一个1 1 2 2 3 3的向量。
3、使用matrix函数创建两个矩阵mat1、mat2。mat1的数据是1:6,3行2列的形式。mat2的数据是7:12,两行三列。(1)编写一个函数调用apply函数族,让矩阵mat1的每一个元素都减去矩阵mat1的最大值,并输出。(2)计算mat1、mat2矩阵相乘并输出%*%。
4、创建一个list列表,列表中包括两个向量、两个矩阵、一个数据框、两个函数(fun1、fun2)。其中fun1实现向量加法,fun2实现矩阵的乘法运算。打印出列表中的各个元素,并调用函数fun1、fun2,输出相应的打印结果。
5、练习读入csv、txt、xlsx格式的本地文件,并将csv文件导出为txt文件。
6、将下列数据以数据框的形式表示出来,并按照年龄,出生月份升序排序。
| 序号 | 姓名 | 年龄 | 出生月份 |
| 1 | Jacks | 27 | 2 |
| 2 | ROSE | 28 | 5 |
| 3 | KD | 27 | 6 |
| 4 | ICE | 29 | 3 |
| 5 | MIK | 27 | 1 |
- 练习使用seq( )函数创建向量:
代码:
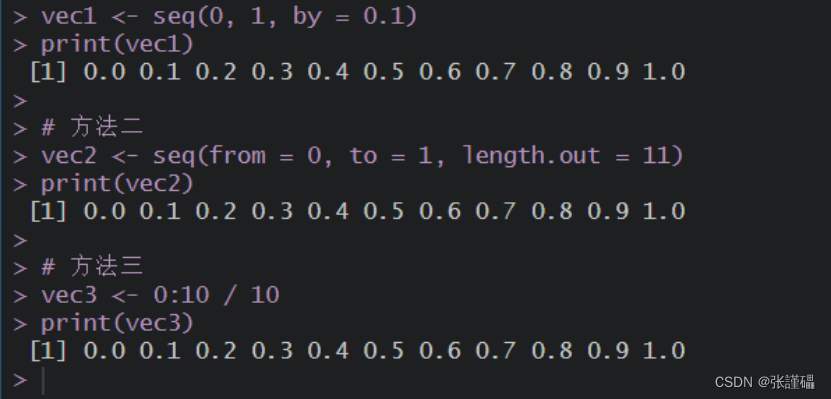
# 方法一vec1 <- seq(0, 1, by = 0.1)print(vec1)# 方法二vec2 <- seq(from = 0, to = 1, length.out = 11)print(vec2)# 方法三vec3 <- 0:10 / 10print(vec3)截图:
- 练习使用rep( )函数创建向量:
代码:
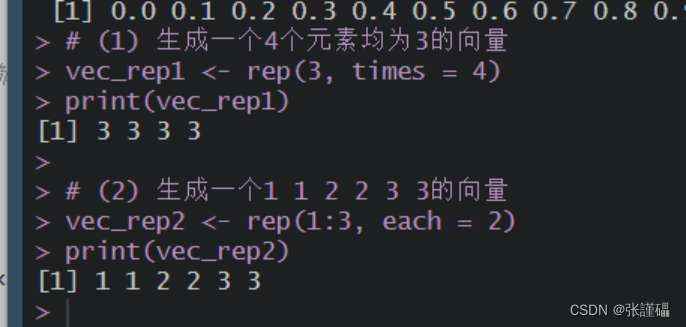
# (1) 生成一个4个元素均为3的向量vec_rep1 <- rep(3, times = 4)print(vec_rep1)# (2) 生成一个1 1 2 2 3 3的向量vec_rep2 <- rep(1:3, each = 2)print(vec_rep2)截图:
3、
代码:
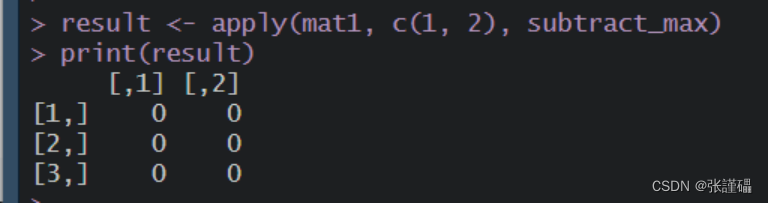
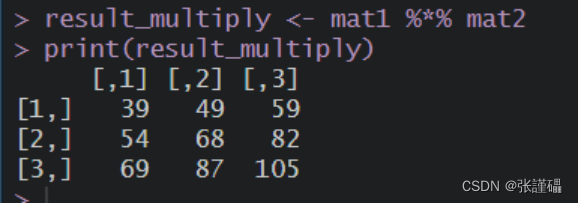
# 创建矩阵mat1mat1 <- matrix(1:6, nrow = 3, ncol = 2)print(mat1)# 创建矩阵mat2mat2 <- matrix(7:12, nrow = 2, ncol = 3)print(mat2)# (1) 使用apply函数族,让矩阵mat1的每一个元素都减去矩阵mat1的最大值,并输出subtract_max <- function(x) {x - max(x)}result <- apply(mat1, c(1, 2), subtract_max)print(result)# (2) 计算mat1、mat2矩阵相乘并输出%*%result_multiply <- mat1 %*% mat2print(result_multiply)截图:
(1)
(2)
4、
代码:
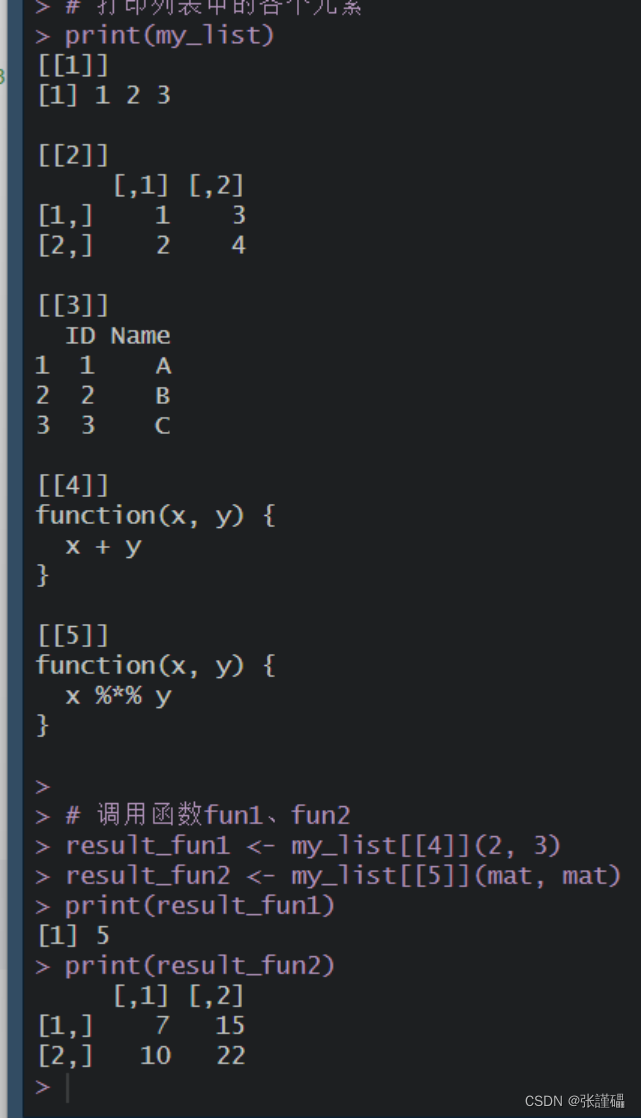
# 创建向量、矩阵、数据框和函数vec <- c(1, 2, 3)mat <- matrix(1:4, nrow = 2)df <- data.frame(ID = 1:3, Name = c("A", "B", "C"))fun1 <- function(x, y) {x + y}fun2 <- function(x, y) {x %*% y}# 创建列表my_list <- list(vec, mat, df, fun1, fun2)# 打印列表中的各个元素print(my_list)# 调用函数fun1、fun2result_fun1 <- my_list[[4]](2, 3)result_fun2 <- my_list[[5]](mat, mat)print(result_fun1)print(result_fun2)截图:
- 练习读入csv、txt、xlsx格式的本地文件,并将csv文件导出为txt文件。
数据实例:
| 序号 | 学院 | 班级 | 总金额 | ||
| 230 | 信息工程学院 | 数据科学与大数据技术20-1 | 800 | ||
| 231 | 信息工程学院 | 数据科学与大数据技术20-2 | 1500 | ||
| 232 | 信息工程学院 | 数据科学与大数据技术20-2 | 500 | ||
| 233 | 信息工程学院 | 数据科学与大数据技术21-1 | 500 | ||
| 234 | 信息工程学院 | 数据科学与大数据技术21-2 | 1000 | ||
| 235 | 信息工程学院 | 数据科学与大数据技术20-2 | 1500 | ||
| 236 | 信息工程学院 | 数据科学与大数据技术21-2 | 800 | ||
| 237 | 信息工程学院 | 数据科学与大数据技术21-2 | 800 | ||
| 238 | 信息工程学院 | 数据科学与大数据技术21-1 | 500 | ||
| 239 | 信息工程学院 | 数据科学与大数据技术21-1 | 500 | ||
| 240 | 信息工程学院 | 数据科学与大数据技术21-1 | 2000 | ||
| 241 | 信息工程学院 | 数据科学与大数据技术21-2 | 1000 | ||
| 242 | 信息工程学院 | 数据科学与大数据技术20-2 | 500 | ||
| 243 | 信息工程学院 | 数据科学与大数据技术21-2 | 800 | ||
| 244 | 信息工程学院 | 数据科学与大数据技术20-1 | 800 | ||
| 245 | 信息工程学院 | 物联网工程20-1 | 1500 | ||
| 246 | 信息工程学院 | 数据科学与大数据技术21-2 | 500 | ||
| 247 | 信息工程学院 | 物联网工程20-1 | 1200 | ||
| 248 | 信息工程学院 | 网络工程20-1 | 500 | ||
| 249 | 信息工程学院 | 物联网工程21-1 | 1000 | ||
| 250 | 信息工程学院 | 物联网工程21-2 | 800 | ||
| 251 | 信息工程学院 | 数据科学与大数据技术20-2 | 1000 | ||
| 252 | 信息工程学院 | 数据科学与大数据技术20-2 | 1500 | ||
| 253 | 信息工程学院 | 数据科学与大数据技术20-1 | 1500 | ||
| 254 | 信息工程学院 | 网络工程20-1 | 1400 | ||
| 255 | 信息工程学院 | 数字媒体技术21-2班 | 800 | ||
| 256 | 信息工程学院 | 数字媒体技术20-1 | 200 | ||
| 257 | 信息工程学院 | 数字媒体技术20-1 | 500 | ||
| 258 | 信息工程学院 | 数字媒体技术20-2 | 300 | ||
| 259 | 信息工程学院 | 数字媒体技术20-2 | 2300 | ||
| 260 | 信息工程学院 | 数字媒体技术20-2 | 300
|

代码:
# 导入所需的包library(readxl)# 读取CSV文件csv_data <- read.csv("student.csv")print("CSV文件内容:")print(csv_data)# 读取文本文件txt_data <- read.table("student.txt")print("文本文件内容:")print(txt_data)# 读取Excel文件xlsx_data <- read_excel("student.xlsx")print("Excel文件内容:")print(xlsx_data)# 将CSV文件导出为TXT文件write.table(csv_data, "student2.txt", sep = "\t", row.names = FALSE)print("CSV文件已导出为TXT文件。")截图:


6、
代码:
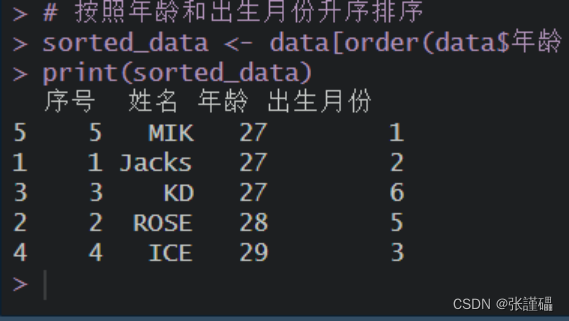
# 创建数据框data <- data.frame(序号 = 1:5,姓名 = c("Jacks", "ROSE", "KD", "ICE", "MIK"),年龄 = c(27, 28, 27, 29, 27),出生月份 = c(2, 5, 6, 3, 1))# 按照年龄和出生月份升序排序sorted_data <- data[order(data$年龄, data$出生月份), ]print(sorted_data)截图:
这篇关于R语言——数据结构与数据处理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




