本文主要是介绍数据资产与企业绩效的紧密关联:深入解析数据资产如何直接影响企业绩效,并探讨如何通过策略性利用数据,优化运营,进而提升企业的整体业绩与竞争力,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、引言
二、数据资产与企业绩效的紧密关联
(一)数据资产的定义与价值
(二)数据资产对企业绩效的影响
三、策略性利用数据资产优化运营
(一)建立数据驱动的企业文化
(二)构建完善的数据治理体系
(三)采用先进的数据分析技术
(四)实现数据资产的跨部门共享
四、案例分析与启示
(一)案例分析
(二)启示
五、结论
一、引言
在数字化浪潮席卷全球的今天,数据已成为企业不可或缺的重要资产。数据资产不仅承载着企业的运营信息,更蕴含着巨大的商业价值。越来越多的企业开始意识到,数据资产的有效管理和利用,与企业绩效的提升密切相关。本文将深入解析数据资产如何直接影响企业绩效,并探讨如何通过策略性利用数据,优化运营,进而提升企业的整体业绩与竞争力。

二、数据资产与企业绩效的紧密关联
(一)数据资产的定义与价值
数据资产,是指企业所拥有或控制的,以电子形式存在的,具有经济价值和战略意义的数据资源。这些数据资源包括但不限于客户数据、销售数据、生产数据、市场数据等。数据资产的价值不仅体现在其本身的准确性和完整性上,更在于其能够为企业提供决策支持,帮助企业实现精准营销、优化生产流程、提高运营效率等。
(二)数据资产对企业绩效的影响
1、提高决策效率:数据资产为企业提供了丰富的信息支持,使企业能够基于数据进行科学决策。这不仅能够降低决策风险,还能够提高决策效率,使企业在激烈的市场竞争中占据先机。
2、优化业务流程:通过对数据资产的分析,企业可以发现业务流程中的瓶颈和问题,从而进行有针对性的改进。这不仅能够提高业务效率,还能够降低运营成本,为企业创造更多的价值。
3、精准营销与客户服务:数据资产可以帮助企业更好地了解客户需求和行为,实现精准营销。同时,通过数据分析,企业还能够及时发现并解决客户问题,提高客户满意度和忠诚度。
4、风险控制与合规管理:数据资产在风险控制和合规管理方面也发挥着重要作用。通过对数据的监控和分析,企业能够及时发现潜在风险,并采取相应的措施进行防范。同时,数据资产还能够为企业的合规管理提供有力支持,确保企业遵守相关法律法规和行业规范。
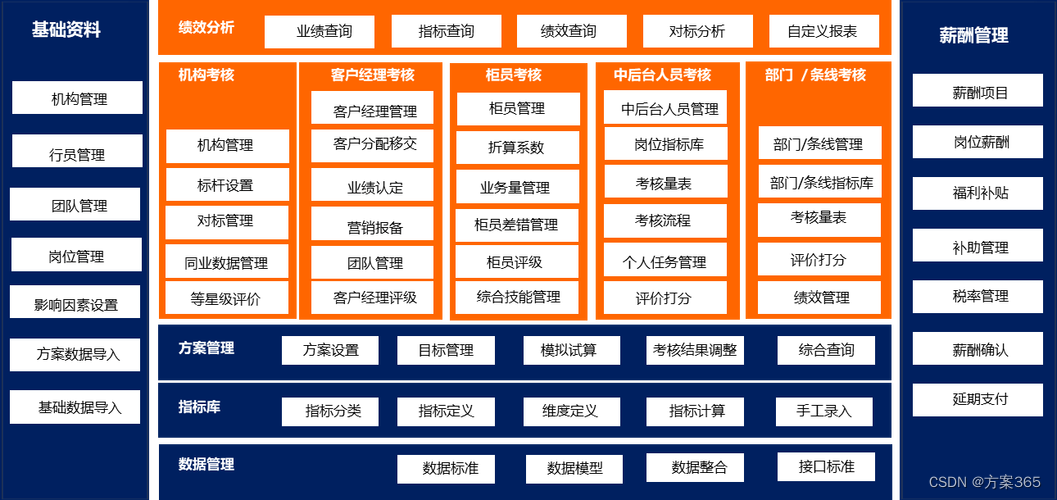
三、策略性利用数据资产优化运营
(一)建立数据驱动的企业文化
要实现数据资产的有效利用,首先需要在企业内部建立数据驱动的企业文化。这意味着企业需要从上到下都认识到数据的重要性,将数据作为决策的重要依据。同时,企业还需要为员工提供必要的数据分析和处理技能培训,使他们能够充分利用数据资产为企业创造价值。
(二)构建完善的数据治理体系
数据治理是确保数据资产质量和价值的重要保障。企业需要构建完善的数据治理体系,包括数据质量管理、数据安全管理、数据访问控制等方面。通过数据治理,企业可以确保数据的准确性、完整性和安全性,为数据资产的利用提供有力保障。
(三)采用先进的数据分析技术
随着大数据、人工智能等技术的不断发展,数据分析技术也在不断进步。企业需要积极采用这些先进技术,对数据进行深度挖掘和分析。通过数据分析,企业可以发现更多的商业机会和价值点,为企业的决策提供有力支持。
(四)实现数据资产的跨部门共享
数据资产的跨部门共享是提高企业运营效率的重要手段。企业需要打破部门之间的壁垒,实现数据资产的跨部门共享。通过共享数据,不同部门之间可以更好地协作和沟通,实现资源的优化配置和高效利用。
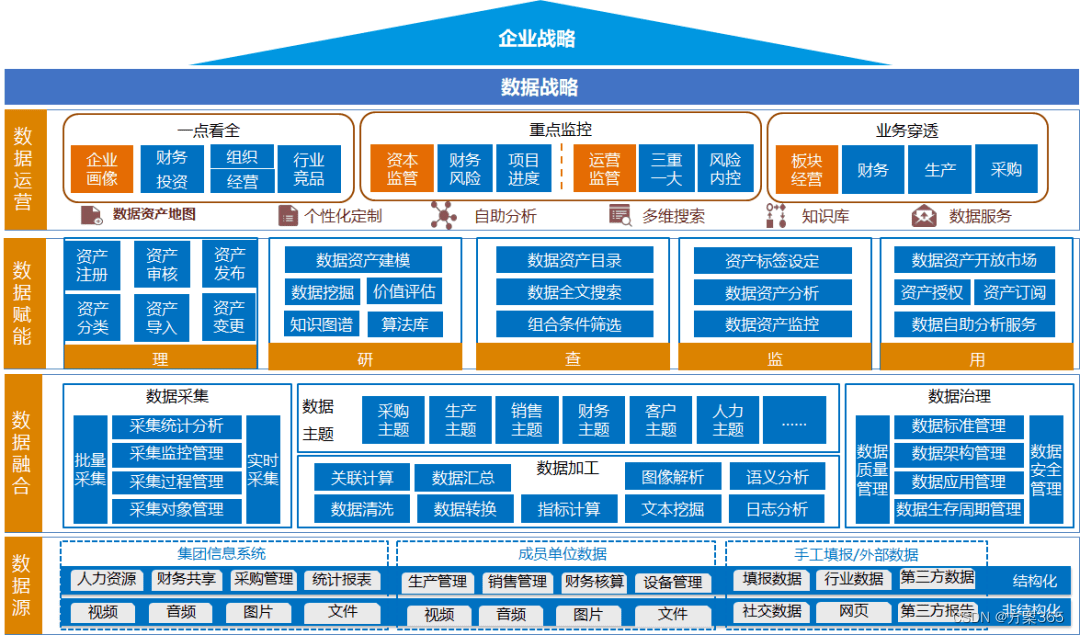
四、案例分析与启示
(一)案例分析
以某电商企业为例,该企业通过构建完善的数据治理体系和分析平台,实现了对海量用户数据的深度挖掘和分析。基于这些数据,企业能够精准地了解用户需求和行为,实现个性化推荐和精准营销。同时,企业还通过数据分析发现了一些潜在的风险和问题,并及时采取了相应的措施进行防范和改进。这些举措不仅提高了企业的运营效率和市场竞争力,还为企业创造了更多的商业价值。
(二)启示
从该案例中我们可以得到以下启示:首先,企业需要重视数据资产的重要性并构建完善的数据治理体系;其次,企业需要积极采用先进的数据分析技术对数据进行深度挖掘和分析;最后企业需要实现数据资产的跨部门共享以提高运营效率和市场竞争力。

“方案365”全新整理数据资产、乡村振兴规划设计、智慧文旅、智慧园区、数字乡村-智慧农业、智慧城市、数据治理、智慧应急、数字孪生、乡村振兴、智慧乡村、元宇宙、数据中台、智慧矿山、城市生命线、智慧水利、智慧校园、智慧工地、智慧农业、智慧旅游等300+行业全套解决方案。
五、结论
综上所述数据资产与企业绩效之间存在着紧密的联系。通过策略性利用数据资产优化运营可以为企业带来巨大的商业价值和竞争优势。因此企业需要重视数据资产的重要性并采取有效措施进行管理和利用以实现企业的可持续发展和长期成功。
这篇关于数据资产与企业绩效的紧密关联:深入解析数据资产如何直接影响企业绩效,并探讨如何通过策略性利用数据,优化运营,进而提升企业的整体业绩与竞争力的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






