本文主要是介绍44、基于深度学习的癌症检测(matlab),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、基于深度学习的癌症检测原理及流程
基于深度学习的癌症检测是利用深度学习算法对医学影像数据进行分析和诊断,以帮助医生准确地检测癌症病变。其原理和流程主要包括以下几个步骤:
-
数据采集:首先需要收集包括X光片、CT扫描、MRI等医学影像数据以及对应的癌症诊断结果的大量数据集。
-
数据预处理:对采集的医学影像数据进行预处理,包括去噪、标准化、图像增强等操作,以确保数据的质量和一致性。
-
特征提取:利用深度学习算法对预处理后的影像数据进行特征提取,提取出代表影像中癌症病变特征的高级特征表示。
-
训练模型:搭建深度学习模型,如卷积神经网络(CNN)、循环神经网络(RNN)等,使用提取的特征表示进行训练,让模型能够自动学习影像数据中与癌症相关的模式和规律。
-
模型评估:通过验证集或交叉验证等方法对训练好的深度学习模型进行评估,评估模型在未见过的数据上的性能表现。
-
癌症检测:使用训练好的深度学习模型对新的医学影像数据进行检测和诊断,判断是否存在癌症病变,并输出诊断结果。
-
可解释性分析:在输出诊断结果的同时,深度学习模型还可以提供对诊断依据的可解释性分析,解释模型是如何判断出病变的,并帮助医生理解判断依据。
通过以上流程,基于深度学习的癌症检测技术可以提高检测的准确性和效率,帮助医生更早地发现和治疗癌症,促进癌症的早期诊断和治疗。
2、基于深度学习的癌症检测说明
针对问题
训练一个神经网络来使用蛋白质表达谱上的质谱数据检测癌症。
数据来源
来自 FDA-NCI 临床蛋白质组学计划数据库的ovarian_dataset.mat文件
数据预处理
新文件包含变量 Y、MZ 和 grp。
说明:
Y 中的每列表示从一名患者身上获取的测量值。Y 中有 216 列,表示有 216 个患者,其中 121 个是卵巢癌患者,95 个是非癌症患者。
Y 中的每行表示 MZ 中指示的特定质量-电荷值下的离子强度水平。MZ 中有 15000 个质量-电荷值,Y 中的每行代表在特定质量-电荷值下患者的离子强度水平。
grp 保存关于哪些样本表示癌症患者以及哪些样本表示非癌症患者的索引信息。
3、关键特征排名
说明
特征的数量远大于观测值的数量,但是单个特征即可实现正确分类。因此,目标是找到一个分类器,该分类器应适当学习如何加权多个特征,同时生成不会过拟合的广义映射。
找到重要特征的简单方法:假设每个 M/Z 值都是独立的,并计算双向 t 检验。rankfeatures 返回最重要的 M/Z 值的索引,例如,按检验统计量绝对值排名的 100 个索引。
x 中的每一列表示 216 个不同患者中的一个。
x 中的每行表示每个患者在 100 个特定质量-电荷值之一下的离子强度水平。
变量 t 具有两行,包含 216 个值,其中每个值为 [1;0](表示癌症患者)或 [0;1](表示非癌症患者)。
代码
[x,t] = ovarian_dataset;
whos x t%显示数据信息4、使用前馈神经网络进行分类
1)说明
已确定一些重要特征,可以使用这些信息对癌症样本和正常样本进行分类
设置随机种子以便每次都重现相同的结果
代码
setdemorandstream(672880951)2)创建单隐藏层前馈神经网络
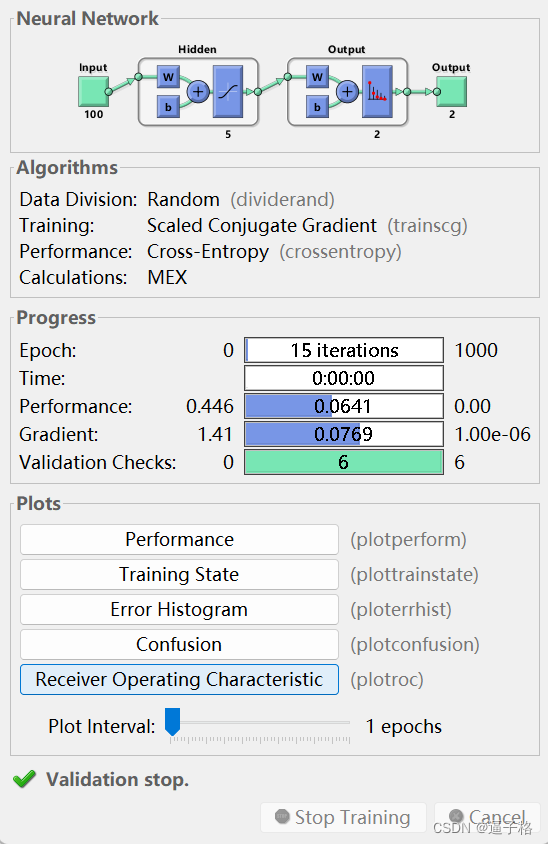
说明:创建并训练具有 5 个隐藏层神经元的单隐藏层前馈神经网络。
输入样本和目标样本自动分为训练集、验证集和测试集。
训练集用于对网络进行训练。只要网络针对验证集持续改进,训练就会继续。
测试集提供独立的网络准确度测量。
输入和输出的大小为 0,因为网络尚未配置成与输入数据和目标数据相匹配。在训练网络时会进行此配置。
代码
net = patternnet(5);
view(net)视图效果
3) 开始训练
说明:样本自动分为训练集、验证集和测试集。训练集用于对网络进行训练。只要网络针对验证集持续改进,训练就会继续。测试集提供独立的网络准确度测量。
代码
[net,tr] = train(net,x,t);4)均方误差图
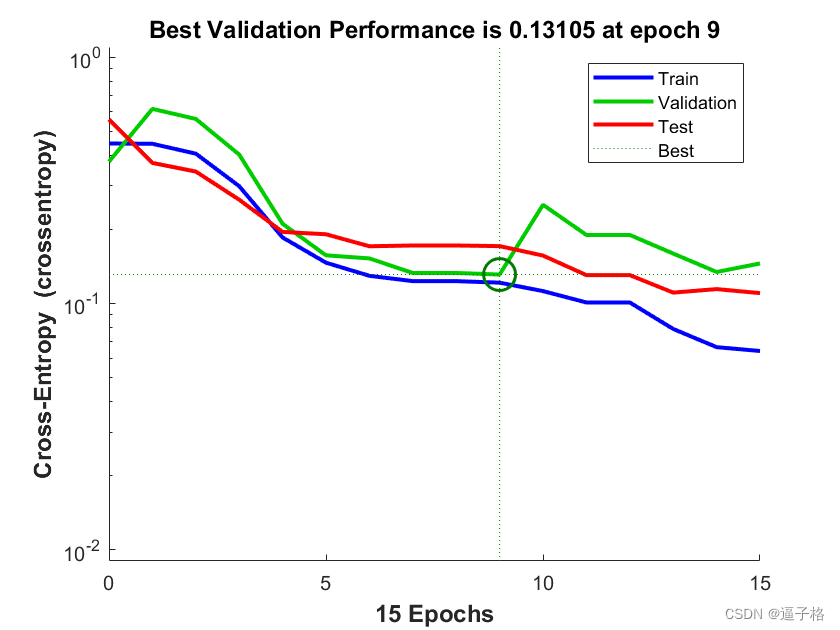
说明:性能以均方误差衡量,并以对数刻度显示。随着网络训练的加深,均方误差迅速降低。
代码
plotperform(tr)视图效果
5) 测试训练的神经网络
说明:从主数据集划分出来的测试样本测试经过训练的神经网络。
在训练中没有以任何方式使用过测试数据,因此测试数据是可用来测试网络的“样本外”数据集。这样可以估计出当使用真实数据进行测试时,网络的表现如何。
网络输出的范围为 0-1。对输出应用阈值以获得 1 和 0,分别表示癌症患者和非癌症患者。
代码
testX = x(:,tr.testInd);
testT = t(:,tr.testInd);
testY = net(testX);
testClasses = testY > 0.56)混淆矩阵图
说明
混淆矩阵图:衡量神经网络数据拟合程度
该混淆矩阵显示了正确和错误分类的百分比。正确分类表示为矩阵对角线上的绿色方块。红色方块表示错误分类。
如果网络是准确的,则红色方块中的百分比应该很小,表示几乎没有错误分类。
如果网络不准确,则可以尝试训练更长时间,或者训练具有更多隐藏神经元的网络。
正确和错误分类的总体百分比
代码
[c,cm] = confusion(testT,testY);
fprintf('Percentage Correct Classification : %f%%\n', 100*(1-c));
fprintf('Percentage Incorrect Classification : %f%%\n', 100*c);7)受试者工作特征图
说明
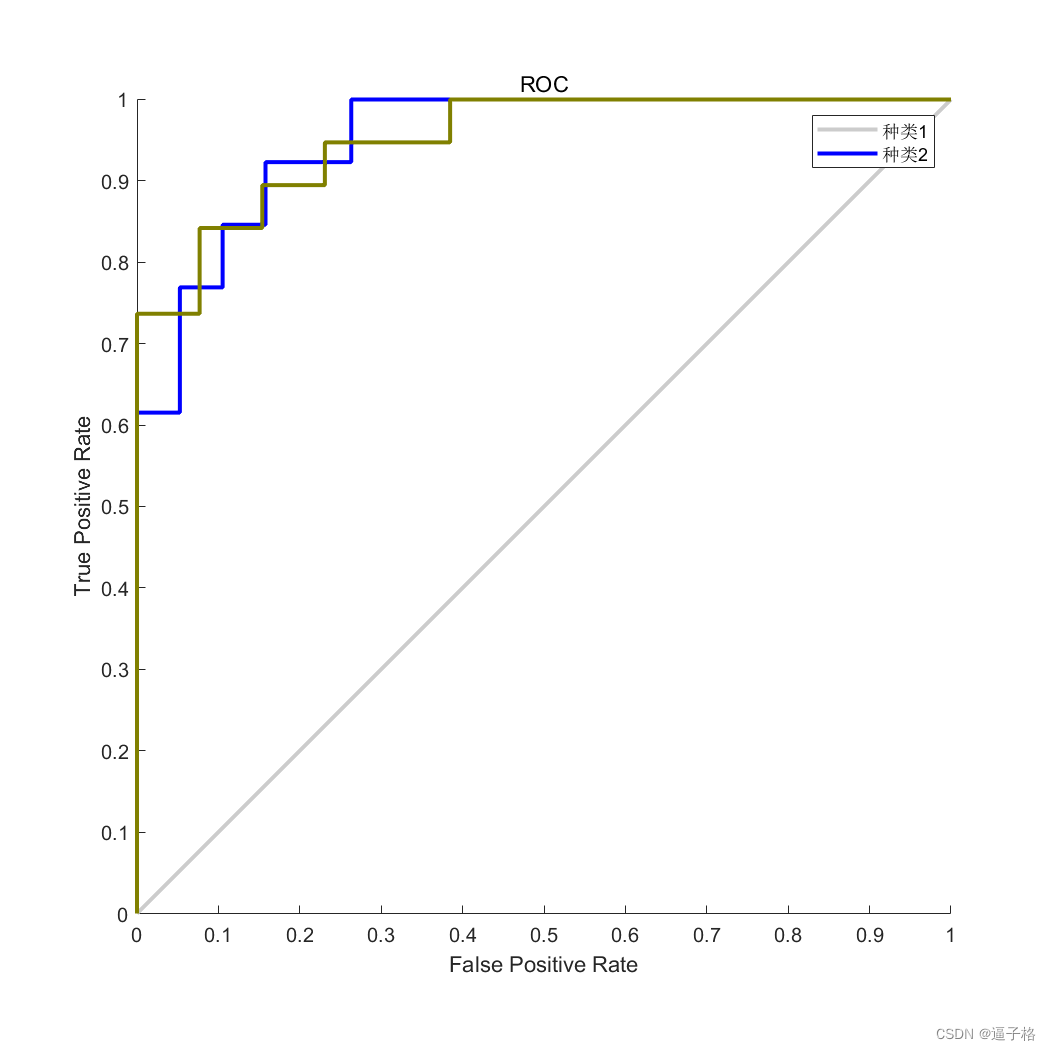
受试者工作特征图:衡量神经网络数据拟合程度
显示随着输出阈值从 0 变为 1,假正率和真正率之间的相关性。
线条越偏向左上方,达到高的真正率所需接受的假正数越少。最佳分类器是线条从左下角到左上角再到右上角,或接近于该模式。
第 1 类表示癌症患者,第 2 类表示非癌症患者。
代码
plotroc(testT,testY)
legend('种类1','种类2')视图效果
5、总结
基于深度学习的癌症检测在 MATLAB 中的实现通常涉及以下几个关键步骤:
-
数据预处理:首先,收集和准备医学影像数据集,包括癌症病变的影像数据和对应的标签(是否患有癌症)。然后对数据进行预处理,包括图像的调整、裁剪、缩放、标准化等,以确保数据质量和一致性。
-
构建深度学习模型:使用 MATLAB 中深度学习工具箱中的函数和工具来构建深度学习模型,如卷积神经网络(CNN)、循环神经网络(RNN)等。在模型的构建过程中,需要定义网络的架构、层的数量和类型,以及激活函数等参数。
-
数据划分和训练:将数据集划分为训练集、验证集和测试集。然后,使用训练集数据对深度学习模型进行训练,通过反向传播算法来不断调整模型参数,提高模型的准确性和泛化能力。
-
模型评估和优化:在训练过程中,通过验证集来评估模型的性能,根据评估结果进行模型的优化和调整,以提高模型在未见过数据上的泛化能力。
-
测试和应用:最终,在训练好的深度学习模型上使用测试集来评估模型的性能和准确性。通过模型对新的医学影像数据进行预测和诊断,实现癌症病变的检测。
通过以上步骤,基于深度学习的癌症检测在 MATLAB 中可以很好地实现,并且 MATLAB 提供了丰富的深度学习工具和函数,方便用户搭建和训练深度学习模型,应用于医学影像数据的分析和诊断。
6、源代码
代码
%% 基于深度学习的癌症检测
%说明:训练一个神经网络来使用蛋白质表达谱上的质谱数据检测癌症。
%数据来源:来自 FDA-NCI 临床蛋白质组学计划数据库的ovarian_dataset.mat文件
%数据预处理:新文件包含变量 Y、MZ 和 grp。
%Y 中的每列表示从一名患者身上获取的测量值。Y 中有 216 列,表示有 216 个患者,其中 121 个是卵巢癌患者,95 个是非癌症患者。
%Y 中的每行表示 MZ 中指示的特定质量-电荷值下的离子强度水平。MZ 中有 15000 个质量-电荷值,Y 中的每行代表在特定质量-电荷值下患者的离子强度水平。
% grp 保存关于哪些样本表示癌症患者以及哪些样本表示非癌症患者的索引信息。
%% 关键特征排名
%说明:特征的数量远大于观测值的数量,但是单个特征即可实现正确分类。因此,目标是找到一个分类器,该分类器应适当学习如何加权多个特征,同时生成不会过拟合的广义映射。
%找到重要特征的简单方法:假设每个 M/Z 值都是独立的,并计算双向 t 检验。rankfeatures 返回最重要的 M/Z 值的索引,例如,按检验统计量绝对值排名的 100 个索引。
%x 中的每一列表示 216 个不同患者中的一个。
%x 中的每行表示每个患者在 100 个特定质量-电荷值之一下的离子强度水平。
%变量 t 具有两行,包含 216 个值,其中每个值为 [1;0](表示癌症患者)或 [0;1](表示非癌症患者)。
[x,t] = ovarian_dataset;
whos x t%显示数据信息
%% 使用前馈神经网络进行分类
%说明:已确定一些重要特征,可以使用这些信息对癌症样本和正常样本进行分类。
%设置随机种子以便每次都重现相同的结果
setdemorandstream(672880951)
%创建并训练具有 5 个隐藏层神经元的单隐藏层前馈神经网络。输入样本和目标样本自动分为训练集、验证集和测试集。训练集用于对网络进行训练。只要网络针对验证集持续改进,训练就会继续。测试集提供独立的网络准确度测量。
%输入和输出的大小为 0,因为网络尚未配置成与输入数据和目标数据相匹配。在训练网络时会进行此配置。
net = patternnet(5);
view(net)
%开始训练
%样本自动分为训练集、验证集和测试集。训练集用于对网络进行训练。只要网络针对验证集持续改进,训练就会继续。测试集提供独立的网络准确度测量。
[net,tr] = train(net,x,t);
%性能以均方误差衡量,并以对数刻度显示。随着网络训练的加深,均方误差迅速降低。
%绘图会显示训练集、验证集和测试集的性能。
plotperform(tr)
%从主数据集划分出来的测试样本测试经过训练的神经网络。
%在训练中没有以任何方式使用过测试数据,因此测试数据是可用来测试网络的“样本外”数据集。这样可以估计出当使用真实数据进行测试时,网络的表现如何。
%网络输出的范围为 0-1。对输出应用阈值以获得 1 和 0,分别表示癌症患者和非癌症患者。
testX = x(:,tr.testInd);
testT = t(:,tr.testInd);
testY = net(testX);
testClasses = testY > 0.5
%混淆矩阵图:衡量神经网络数据拟合程度
%该混淆矩阵显示了正确和错误分类的百分比。正确分类表示为矩阵对角线上的绿色方块。红色方块表示错误分类。
%如果网络是准确的,则红色方块中的百分比应该很小,表示几乎没有错误分类。
%如果网络不准确,则可以尝试训练更长时间,或者训练具有更多隐藏神经元的网络。
%正确和错误分类的总体百分比
[c,cm] = confusion(testT,testY);
fprintf('Percentage Correct Classification : %f%%\n', 100*(1-c));
fprintf('Percentage Incorrect Classification : %f%%\n', 100*c);
%受试者工作特征图:衡量神经网络数据拟合程度
%显示随着输出阈值从 0 变为 1,假正率和真正率之间的相关性。
%线条越偏向左上方,达到高的真正率所需接受的假正数越少。最佳分类器是线条从左下角到左上角再到右上角,或接近于该模式。
%第 1 类表示癌症患者,第 2 类表示非癌症患者。
plotroc(testT,testY)
legend('种类1','种类2')这篇关于44、基于深度学习的癌症检测(matlab)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




