本文主要是介绍点击率预测|深度学习在CTR中的应用,FNN,SNN论文解读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
请点击上方“AI公园”,关注公众号
【导读】LR,FM,FFM都是浅层模型,想不想试试深度学习?请看下面:
摘要:预测用户的反馈,如点击率,转换率在很多的网络应用中非常的重要,如网络搜索、个人推荐、在线广告等。和图像和语音领域的特征不同,这些场景的输入的特征常常是多领域的,离散的,类别化的特征,相互之间的依赖的相关知识也很少。主流的用户反馈模型要么使用线性模型,要么手工组合高阶的特征,前者缺乏特征间的组合信息,后者会导致组合出庞大的特征空间。为了解决这个问题,我们提出了两个新的使用DNN的模型,能够自动的学习特征间的组合的模式,进行预测。为了能够让DNN有效的工作,我们使用了3中特征变换的方法,FM,RBM和DAE。本文展示了我们的模型的结构和有效的训练的方法。大量的试验和真实的数据表明了我们的方法比业界能做到业界领先。
1. 介绍
在线广告领域,定位目标用户的能力是对比传统线下广告的关键优势。所有的定位技术,都依赖于预测是否特定的用户认为这个广告是相关的,给出用户在特定的场景中点击的概率。目前大部分的CTR预测都是线性模型,如逻辑回归,朴素贝叶斯,FTRL逻辑回归和贝叶斯逻辑回归等。所有的这些都是基于使用one-hot编码的大量稀疏特征。线性模型简单,有效,但是性能偏差,应为无法学习到特征之间的相互关系。非线性模型可以通过特征间的组合提高模型的能力。如FMs,将二值化的特征映射成连续的低维空间,通过内积获取特征间的相互关系。梯度提升树,通过树的构建过程,自动的学习特征的组合。然而,这些方法并不能利用所有可能的组合。另外,许多模型手工的进行特征工程,自己决定如何进行特征的组合。另一个问题是,已有的CTR模型在对复杂数据间的潜在的模式上的表达能力是非常有限的。所以,它们的泛化能力是非常受限的。
深度学习在CV和NLP上取得了很大的成功,在非监督的训练中,神经网络可以从原始的特征中学习到高维的特征表示,这个能力也可以用在CTR上。在CTR中,大部分的输入特征是来自各个领域的,而且是离散的类别特征。特征之间的相互依赖是未知的。我们想看一下,深度学习能够如何提升模型的能力。
本文介绍了两种深度学习模型,称为FNN和SNN,FNN使用FM进行监督学习,得到嵌入层,可以有效的减少稀疏特征的维度,得到连续的稠密的特征。SNN是通过一个使用负样本采样方法的基于采样的玻尔兹曼机或者是一个基于采样的自动编码去噪机。在嵌入层之上,我们构建多层的神经网络来探索潜在的数据的模式。
2. 相关工作
将大型的输入向量嵌入到低维的向量空间式预测任务的一个很有效的方法,可以减少数据和模型的复杂度,提高模型的能力。最近提出了很多类似的模型,如FM之类。如果使用深度学习模型,通常有两个步骤,第一步,通过非监督学习(如限制玻尔兹曼机或者层叠的自编码去噪机)得到输入数据的分布。第二步,使用监督学习对模型进行finetune。我们的模型的新颖之处在于第一层的初始化,而不是使用原始的特征,维度高,稀疏度高,难以训练。我们的模型能够处理更加通用的多领域的类别特征。
3. 使用类别特征用DNNl来进行点击率预测
本节中,我们讨论了两个DNN模型,FNN和SNN,输入的类别特征都是分领域的通过one-hot编码。比如city,有多个单元,每个表示一个特定的字段,如city=Londln,只有一个正的(1),其他的都是负的(0)。编码之后的特征,表示为x,如下图:
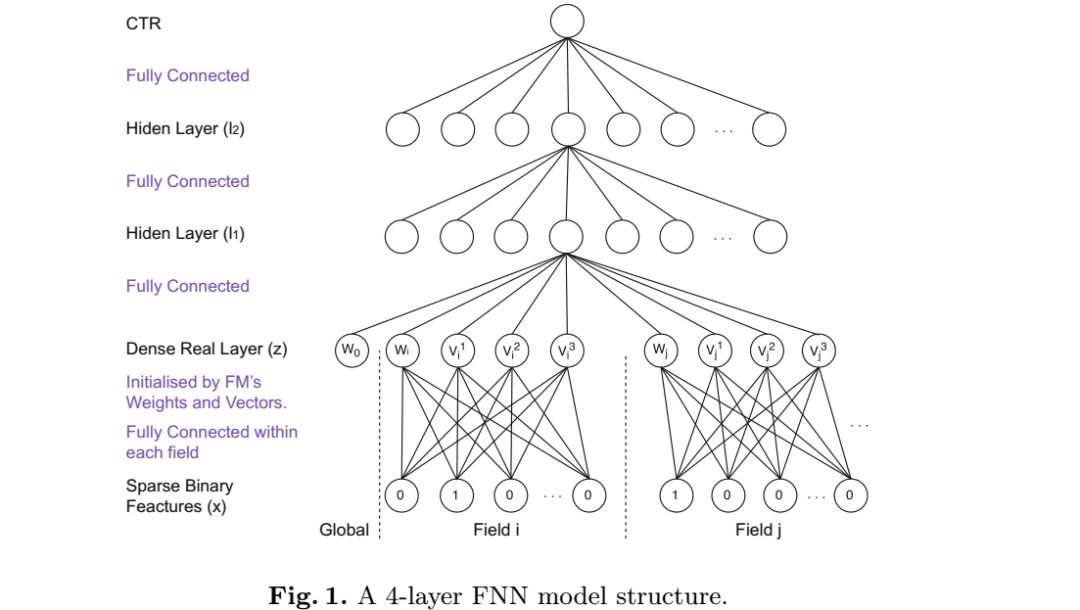
3.1 基于因子分解机的神经网络(FNN)
FNN的最底层是FM,如图1,最高层的输出是一个实数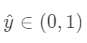 。点击率的概率可以表示为:
。点击率的概率可以表示为: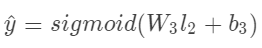
其中,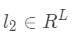 是这层的输入,
是这层的输入,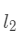 的计算方法:
的计算方法: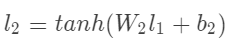
我们使用tanh作为激活函数是因为从经验上,这个要比其他的激活函数表现更好,类似的: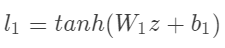
其中: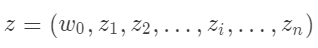
其中n是领域的数量,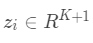 是第i个领域的FM的向量参数。
是第i个领域的FM的向量参数。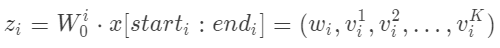
使用这种方法,第一层的z向量通过训练一个FM来进行初始化: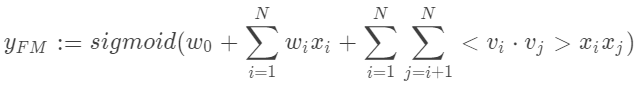
通过这种方法,上面的神经网络可以从FM的表示中更加有效的学习。可以学到更加多的潜在的数据间的模式,能够得到更好的效果。
更进一步,隐含层的权重(除了FM层)可以通过预训练的RBM来进行初始化。FM的权重可以通过SGD来进行更新,我们只需要更新那些不为0的单元,这样可以减少大量的计算。通过预训练对FM层和其他的层进行初始化之后,再通过监督学习的方法进行finetune,使用交叉熵的损失函数: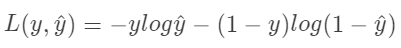
然后通过反向传播的方法来更新权值。由于输入x中的大量的元素都是0,我们可以只更新相关的权值来加速finetune。
3.2 基于采样的神经网络(SNN)
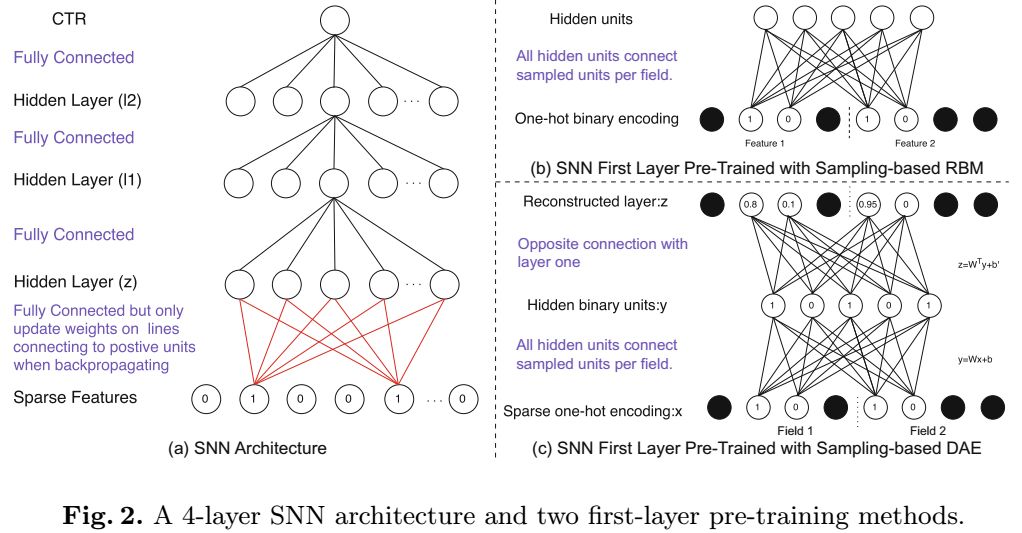
SNN的结构如上图,和FNN的区别在于底层的训练方式。SNN的底层是个全连接层,激活函数为sigmoid。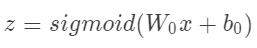 初始化的时候,我们预训练了RBM和DAE,为了解决训练时的one-hot编码带来的稀疏问题,我们使用了基于采样的RBM和基于采样的DAE,高效的计算初始化的权值。
初始化的时候,我们预训练了RBM和DAE,为了解决训练时的one-hot编码带来的稀疏问题,我们使用了基于采样的RBM和基于采样的DAE,高效的计算初始化的权值。
在训练时,我们不使用每个领域的全部的特征,例如city这个领域,只有一个元素是1,其他都是0,所以我们随机采样m个为0的元素,图2中(b)和(c)中的黑点表示的没有被采样到的为0的元素。然后我们使用在RBM上用对比散度,在DAE上用SGD来进行预训练,得到的稠密的特征表示作为后一层的输入。
3.3 正则化
为了防止过拟合,我们使用L2的正则化项,如下: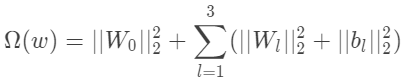
另外,dropout也是防止过拟合的一个很流行的方法,我们在实验中也用到了。
4. 实验
4.1 实验设置
数据集 我们使用的是iPinYou的数据集,这是一个公开的数据集。该数据集有19.5M条数据,14.79k条的正样本,所有的特征都是类别特征。在进行one-hot编码之后,二值化特征的数量是937.67K。我们将这些二值化的特征输入到不同的模型中来进行对比。在我们的实验中,分别使用了1458,22259,2261,3386号的广告以及整个数据集。
模型 我们对比的模型包括:
LR:逻辑回归模型
FM:因子分解机
FNN:基于因子分解机的神经网络
SNN:基于采样的神经网络
我们的实验代码FNN和SNN是Theano实现的。代码路径:https://github.com/wnzhang/deep-ctr 。
度量 度量方法采用ROC曲线以及AUC(曲线下面积)。
4.2 性能对比
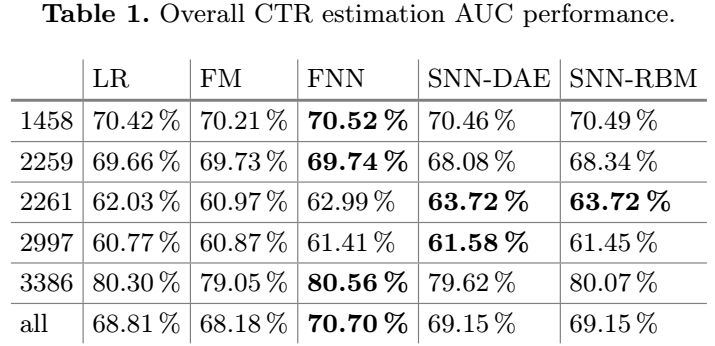
表1中显示的是不同的方法的对比。我们发现FM相比LR并没有提升多少,这表明2阶的特征组合并没有获取足够的数据潜在的关系。FNN和SNN要FM和LR好一些。
4.3 超参数的调试
使用深度学习需要用到一些超参数,下面显示了我们调试超参数的一些细节。我们使用SGD进行训练,我们尝试了不同的学习率,1,0.1,0.01,0.001,0.0001,选择了一个最佳的在验证集上进行验证。使用采样的SNN-RBM和SNN-DAE的时候,我们尝试了采样数量为m=1,2,4的情况,发现m=2是最好的。对于激活函数,我们尝试了线性函数,sigmoid,tanh,然后发现tanh是最好的。
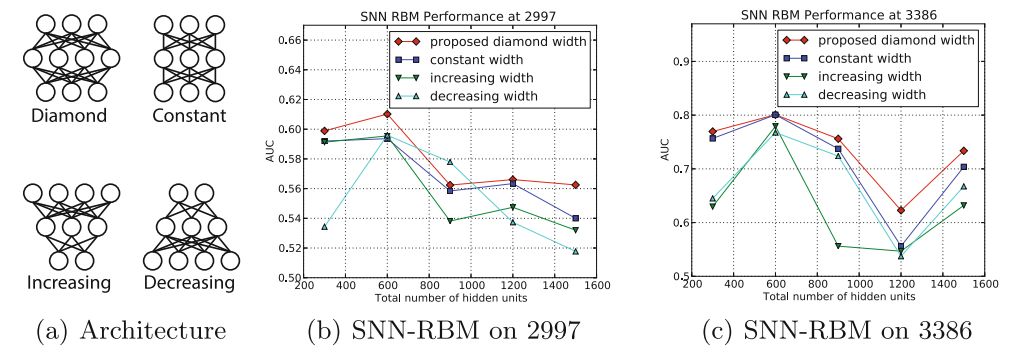
4.4 结构选择
在我们的模型中,我们研究了具有3,4,5个隐层的结构,发现具有3个隐层的结构效果最好。除了增减层数外,我们还对比了不同的结构,在总的隐含节点相同的情况下,发现钻石型的是最好的。最后使用的结构是(200,300,100)。
4.5 正则化比较
神经网络非常容易过拟合。我们对比了L2正则化和dropout。如下图。很显然,dropout的效果要比L2要好。
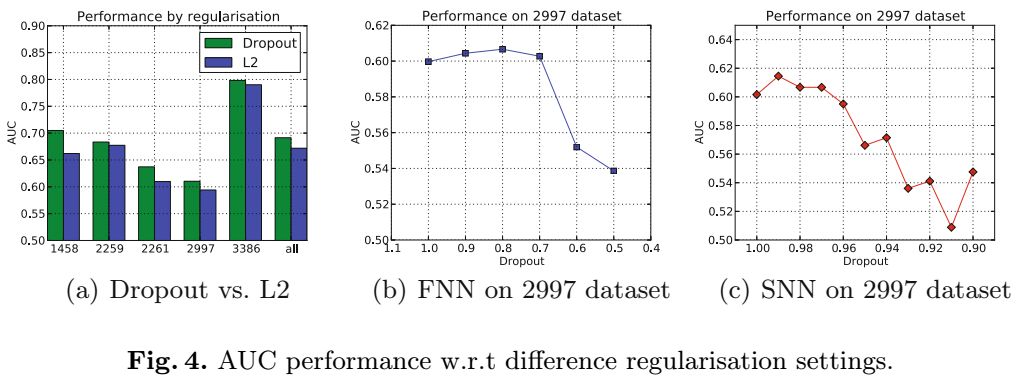
4.6 参数分析
作为对4.4节和4.5节的一个总结,模型中有两个非常重要的因素(i)层的大小的参数,决定了模型的结构(ii)dropout的比例参数,对泛化能力有较大的影响。从图中可以看出,dropout的比例的变化,对AUC的影响是比较大的。随着dropout比例的变大,模型的能力先变好,然后显著的下降。对于FNN来说,dropout的最佳值为0.8,对SNN来说,dropout的最佳值为0.99。
5. 结论
在本文中,我们研究了DNN对于多领域稀疏特征的点击率预测的潜力。我们提出了两个模型,FNN和SNN,两者通过预训练来初始化权值。我们在不同的模型上对实际的数据集进行了对比,发现FNN和SNN比之前的模型更好。
本文可以任意转载,转载时请注明作者及原文地址。

请长按二维码关注我们
这篇关于点击率预测|深度学习在CTR中的应用,FNN,SNN论文解读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



