本文主要是介绍Python数据科学 | 是时候跟Conda说再见了,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文来源公众号“Python数据科学”,仅用于学术分享,侵权删,干货满满。
原文链接:是时候跟Conda说再见了
1 简介
conda作为Python数据科学领域的常用软件,是对Python环境及相关依赖进行管理的经典工具,通常集成在anaconda或miniconda等产品中供用户日常使用。

但长久以来,conda在很多场景下运行缓慢卡顿、库解析速度过慢等问题也一直被用户所诟病,且由于anaconda、miniconda本身属于「商业性质」的软件产品,导致很多公司在未获得商业许可的前提下,内部使用anaconda、miniconda下载安装非开源许可渠道的软件库资源,被anaconda检测出企业IP地址,进而收到相关的律师函警告,引发了一系列的商业风险。
在这样的大背景下,由开源软件社区驱动的conda-forge组织发展迅速,提供了可免费使用,无商业风险且稳定高效的一系列开源工具及网络资源服务,今天我要给大家介绍的miniforge,就由conda-forge组织开发维护,可作为anaconda、miniconda的替代品。

2 miniforge的安装及使用
2.1 下载安装miniforge
miniforge官方安装包下载页(https://conda-forge.org/miniforge/)中的安装包资源托管在Github上:
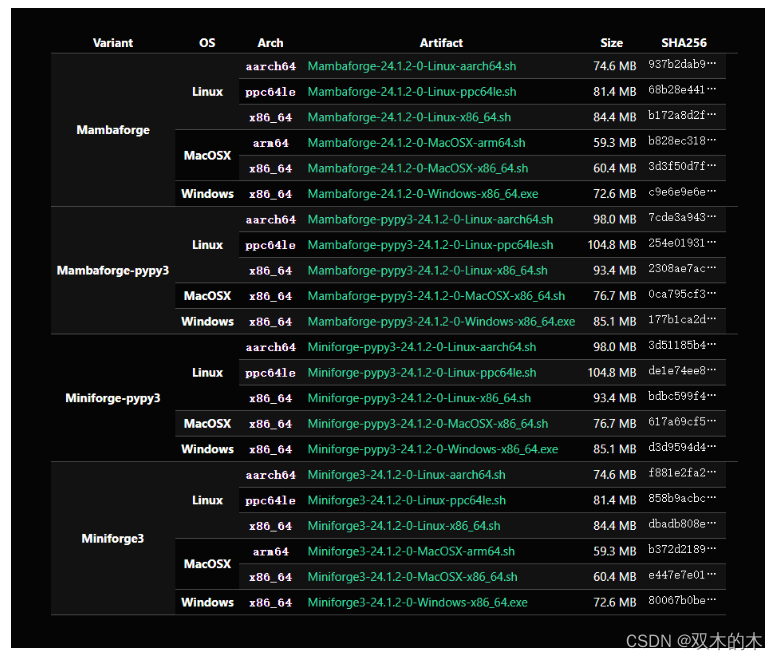
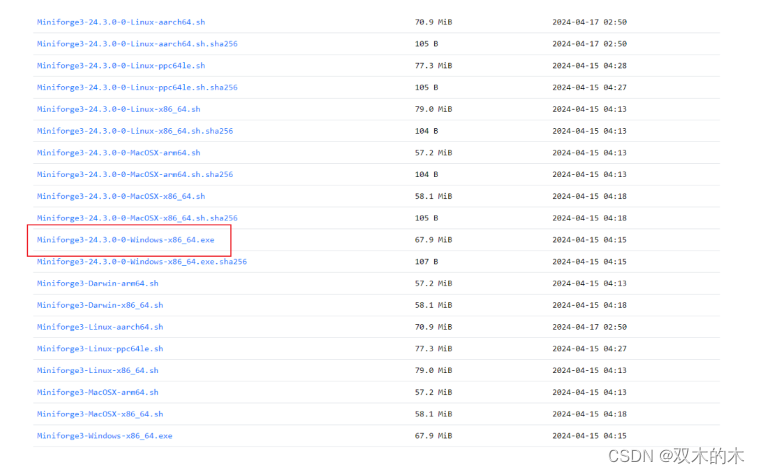
国内的朋友可以通过清华大学镜像站对miniforge安装包资源进行加速下载(https://mirrors.tuna.tsinghua.edu.cn/github-release/conda-forge/miniforge/),选择与自己系统相符合的版本进行下载即可,以windows为例,下载当前最新版本对应的Miniforge3-24.3.0-0-Windows-x86_64.exe:
下载完成后,双击打开进行安装(安装前建议「清空」电脑上先前残留的其他Python环境):
点击I Agree:
下一步:
选择或自定义安装路径:

根据推荐提示,悉数进行勾选:
等待安装完成即可:
2.2 配置环境变量
针对windows系统,由于新版本的miniforge在安装时不再提供自动创建相关环境变量的选项,因此需要我们手动将相关路径添加到系统PATH中,譬如,我的miniforge自定义安装在本机的C:\miniforge中,就至少需要添加C:\miniforge、C:\miniforge\Scripts、C:\miniforge\Library\bin这几个路径:
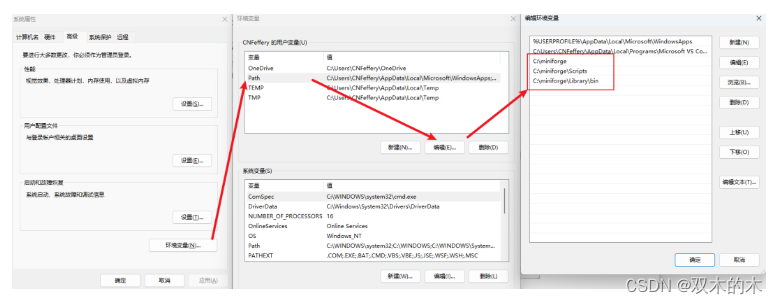
上述过程完成后,可以在本机终端中执行mamba -V查看相关版本信息(miniforge中包含了最小化的conda和mamba),检验上述配置是否完成:
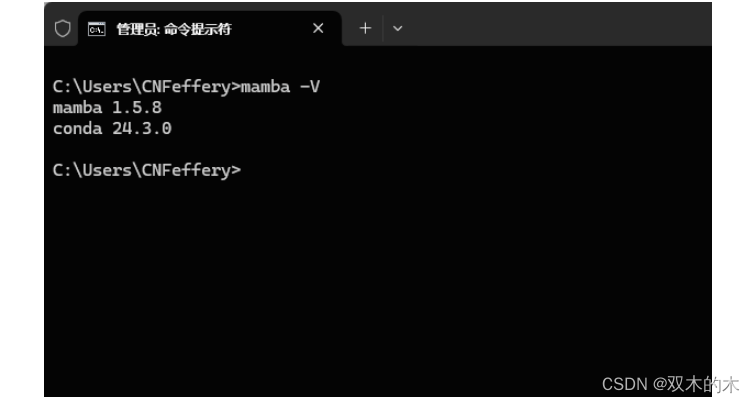
2.3 miniforge常用功能
上文提到过,miniforge中同时内置了包管理工具conda和mamba,其中mamba可「完全」作为conda功能的替代,且运行效率优于conda,我们只需要将平时熟悉的conda命令中的conda替换为mamba即可,譬如:
-
「查看已有虚拟环境」
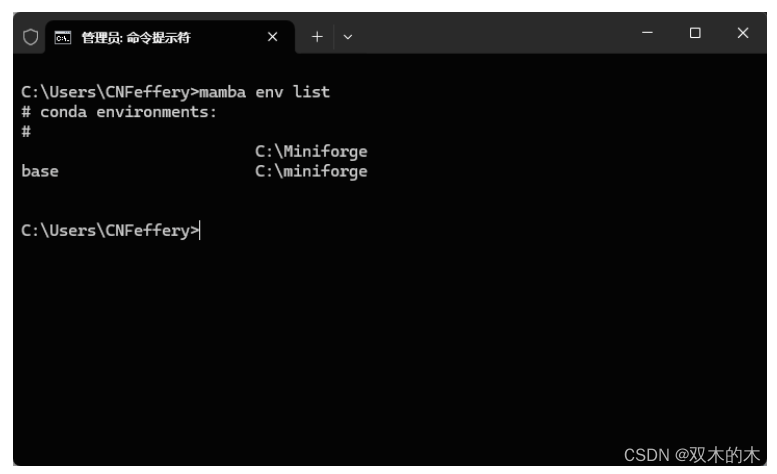
-
「激活指定虚拟环境」
注:如果初次执行activate命令失败,按照提示信息执行mamba init命令,再重新打开终端即可。

-
「创建新的虚拟环境」
注:miniforge默认将conda-forge作为下载源。
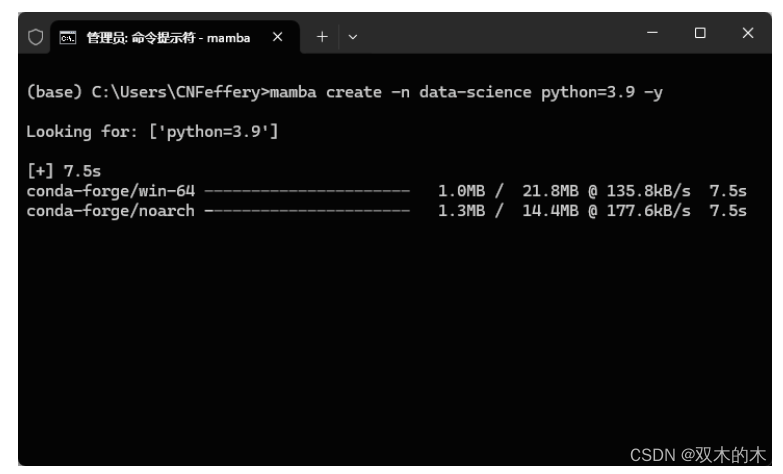
如果嫌默认的conda-forge网速太慢,可以像conda那样通过-c参数自定义镜像源,如下面的例子中使用到南方科技大学的main源,速度就快了许多:
mamba create -n data-science python=3.9 -c https://mirrors.sustech.edu.cn/anaconda/pkgs/main/ -y
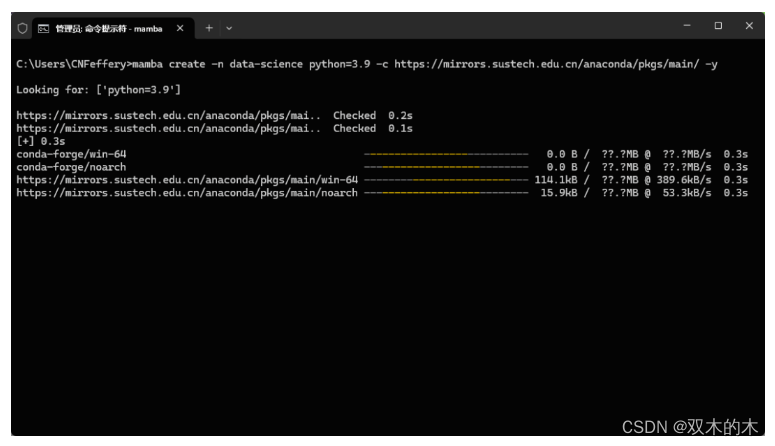
-
「安装指定库」
这里我们以依赖包众多的GIS分析库geopandas为例,mamba在短时间内完成初始化解析后,非常流畅地以并行的方式迅速完成了各依赖库的下载及安装过程(同样的操作,conda大概率会一直卡顿下去直至失败。。。):
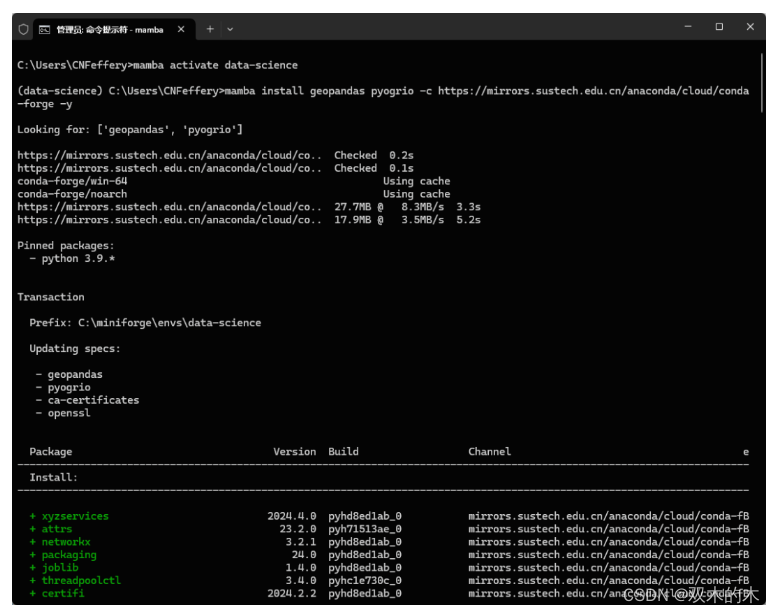
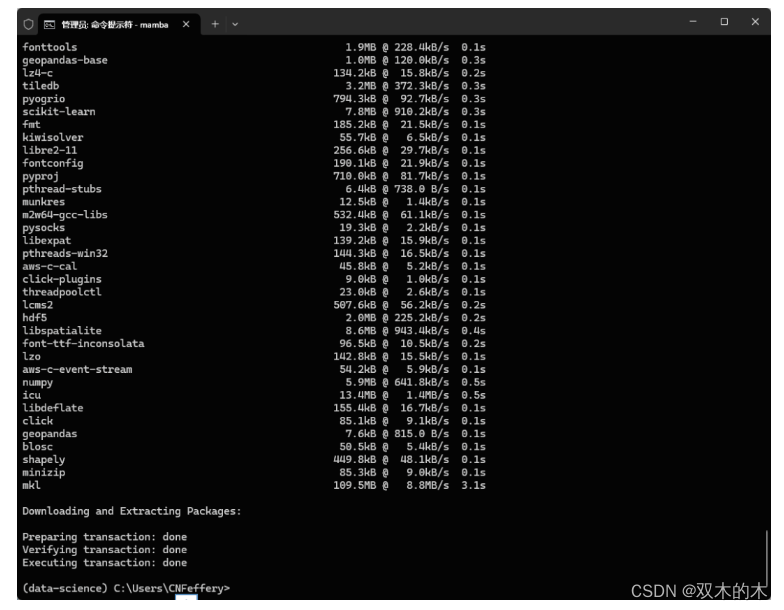
-
「移除指定虚拟环境」
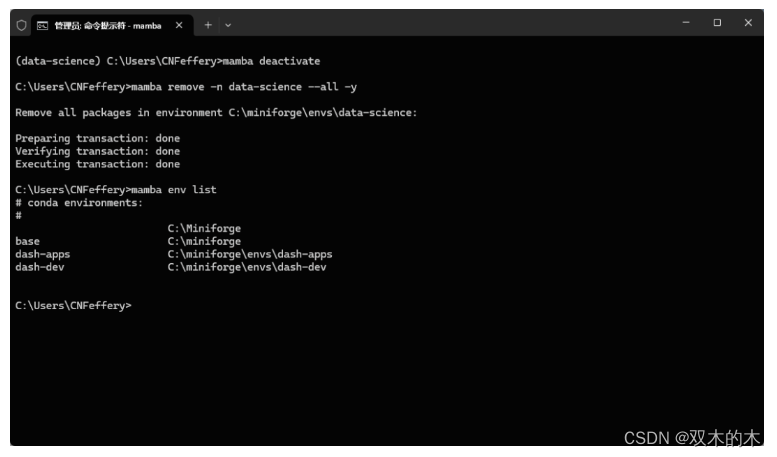
-
「清空本地缓存」

更多用法请移步mamba官方文档:https://mamba.readthedocs.io/
以上就是本文的全部内容, 欢迎在评论区与我们进行讨论~
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。
这篇关于Python数据科学 | 是时候跟Conda说再见了的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







