本文主要是介绍NetSuite Inventory Transfer Export Saved Search,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
用户之前有提出一个实际的需求,大致意思是想要导出Inventory Transfer的相关明细行信息,且要包含From Location,To Location,Quantity等信息。
我们知道From Location和To Location在IT Form中应该是在Main的部分,在Detail部分是没有Location的相关信息的;
另外,当我们用拉出的Location的字段信息时,结果会是一个Item占有两行,第一行Location对应“From Location”,对应Quantity显示为负数,第二行Location对应“To Location”,对应Quantity显示为正数,这样虽然可以得到需要的数据,但其实是不符合大众的查看习惯的,因此我们觉得可以尝试用Case When语句来实现该需求。具体设计如下:
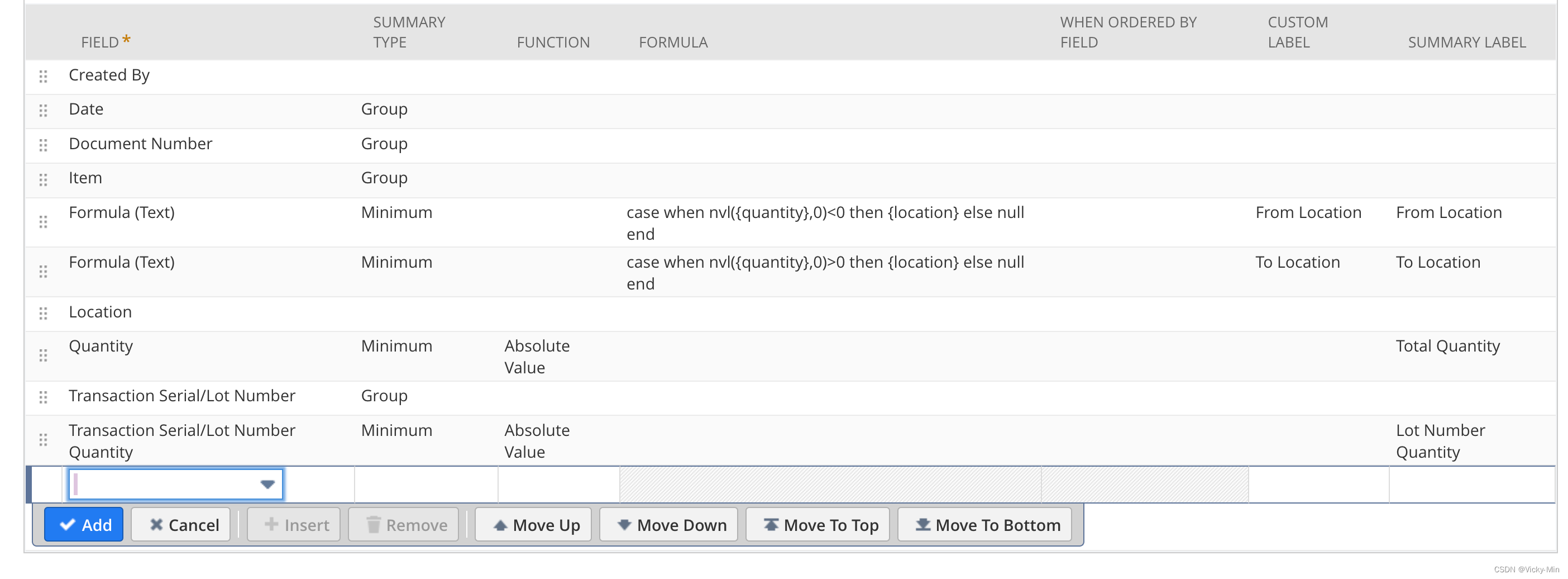
如上图所示,我们利用正负数的逻辑,From Location实际上对应的是小于0的负数,To Location实际上对应的是大于0的正数,Quantity与Lot Quantity(该Search中含有批次信息)我们则取了绝对值,这样一个Item我们就显示在了同一行中,比较直接地符合大家的使用习惯,最终呈现出的结果则如下所示:
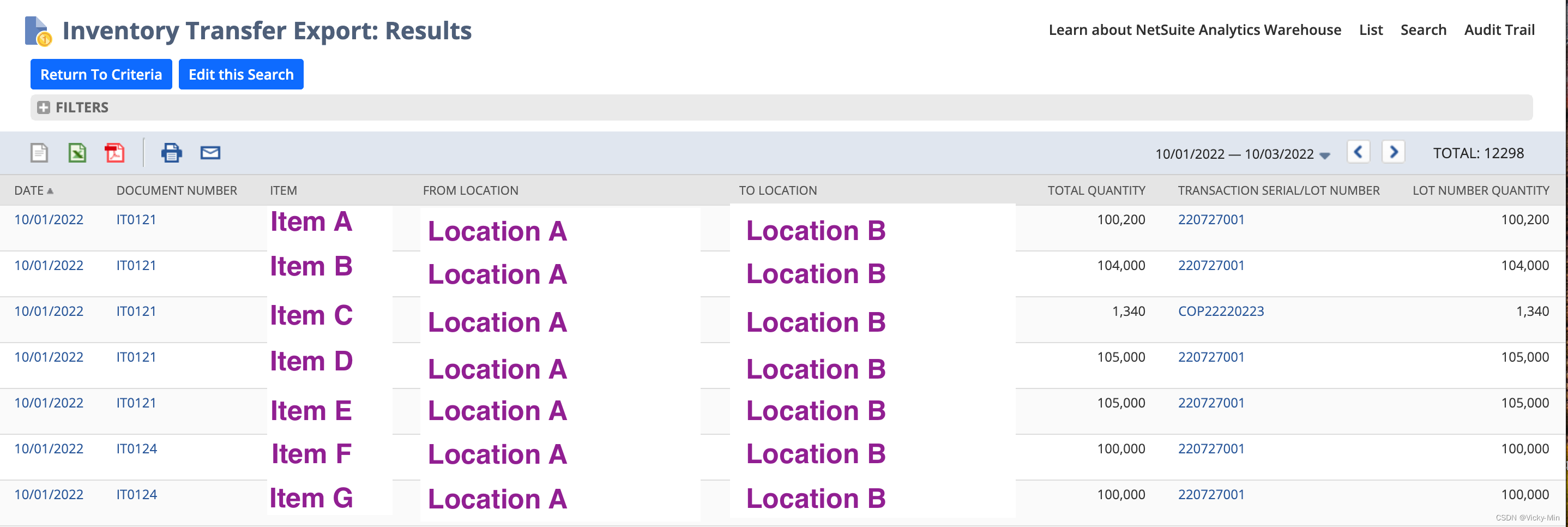
将Case When语句运用在Saved Search中,在一些特定的需求背景下它能大大帮助我们,大家可以进行实践~
这篇关于NetSuite Inventory Transfer Export Saved Search的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







