本文主要是介绍回归算法详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
回归算法详解
回归分析是一类重要的机器学习方法,主要用于预测连续变量。本文将详细讲解几种常见的回归算法,包括线性回归、岭回归、Lasso 回归、弹性网络回归、决策树回归和支持向量回归(SVR),并展示它们的特点、应用场景及其在 Python 中的实现。
一 什么是回归分析?
回归分析是一种统计方法,用于确定因变量(目标变量)和自变量(预测变量)之间的关系。回归分析的目标是建立一个模型,通过自变量预测因变量。
二 常见回归算法
1. 线性回归
线性回归是最基本的回归方法,假设因变量和自变量之间存在线性关系。线性回归的目标是找到一条直线,使得所有数据点到该直线的距离之和最小。
线性回归模型的方程为:
y = β 0 + β 1 x 1 + β 2 x 2 + … + β n x n + ϵ \ y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \ldots + \beta_n x_n + \epsilon \ y=β0+β1x1+β2x2+…+βnxn+ϵ
其中, β 0 \ \beta_0 β0 是截距, β i \ \beta_i βi 是自变量 x i \ x_i xi 的回归系数, ϵ \ \epsilon ϵ 是误差项。
损失函数
最小化均方误差(Mean Squared Error, MSE):
MSE = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 \ \text{MSE} = \frac{1}{n} \sum_{i=1}^n (y_i - \hat{y}_i)^2 \ MSE=n1i=1∑n(yi−y^i)2
特点
- 简单易懂:线性回归是最简单的回归模型,易于解释和实现。
- 计算速度快:适用于大规模数据集。
- 易于扩展:可以通过添加多项式项、交互项等扩展为更复杂的模型。
应用场景
线性回归适用于因变量和自变量之间存在线性关系的场景,例如经济学中的供求关系、工程中的温度与压力关系等。
2. 岭回归
岭回归(Ridge Regression)是一种线性回归的变种,通过在损失函数中加入 L 2 \ L2 L2 正则化项来防止过拟合。
岭回归的损失函数为:
Loss = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 + λ ∑ j = 1 n β j 2 \ \text{Loss} = \frac{1}{n} \sum_{i=1}^n (y_i - \hat{y}_i)^2 + \lambda \sum_{j=1}^n \beta_j^2 \ Loss=n1i=1∑n(yi−y^i)2+λj=1∑nβj2
其中, λ \lambda λ是正则化参数。
特点
- 防止过拟合:通过正则化项控制模型的复杂度,防止过拟合。
- 处理共线性:适用于自变量之间存在较强相关性的情况。
- 参数选择:需要调优正则化参数 λ \lambda λ。
应用场景
岭回归适用于高维数据集和自变量之间存在共线性的场景,如基因表达数据分析、文本数据分类等。
3. Lasso 回归
Lasso 回归(Least Absolute Shrinkage and Selection Operator Regression)通过加入 L 1 L1 L1 正则化项来防止过拟合,并能够进行特征选择。
Lasso 回归的损失函数为:
Loss = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 + λ ∑ j = 1 n ∣ β j ∣ \ \text{Loss} = \frac{1}{n} \sum_{i=1}^n (y_i - \hat{y}_i)^2 + \lambda \sum_{j=1}^n |\beta_j| \ Loss=n1i=1∑n(yi−y^i)2+λj=1∑n∣βj∣
特点
- 特征选择:通过 L 1 L1 L1 正则化,将不重要的特征系数收缩为零,从而实现特征选择。
- 防止过拟合:与岭回归类似,Lasso 回归也能够控制模型的复杂度。
- 参数选择:需要调优正则化参数 λ \lambda λ。
应用场景
Lasso 回归适用于高维数据和特征选择的场景,如基因数据分析、文本分类、图像处理等。
4. 弹性网络回归
弹性网络回归(Elastic Net Regression)结合了岭回归和 Lasso 回归的正则化项,能够同时进行特征选择和防止过拟合。
弹性网络回归的损失函数为:
Loss = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 + λ 1 ∑ j = 1 n ∣ β j ∣ + λ 2 ∑ j = 1 n β j 2 \ \text{Loss} = \frac{1}{n} \sum_{i=1}^n (y_i - \hat{y}_i)^2 + \lambda_1 \sum_{j=1}^n |\beta_j| + \lambda_2 \sum_{j=1}^n \beta_j^2 \ Loss=n1i=1∑n(yi−y^i)2+λ1j=1∑n∣βj∣+λ2j=1∑nβj2
特点
- 特征选择与防止过拟合:结合了 Lasso 和岭回归的优点,能够进行特征选择并防止过拟合。
- 适用于高维数据:在高维数据集上表现良好。
- 参数选择:需要调优两个正则化参数 λ 1 \lambda_1 λ1 和 λ 2 \lambda_2 λ2。
应用场景
弹性网络回归适用于高维数据和特征选择的场景,尤其是当自变量之间存在高度相关性时。
5. 决策树回归
决策树回归通过构建决策树来进行回归,能够捕捉非线性关系。
算法步骤
- 将数据集划分为若干子集。
- 对每个子集,选择一个特征及其取值进行划分,使得划分后的均方误差最小。
- 递归地对每个子集进行上述划分,直到满足停止条件。
特点
- 捕捉非线性关系:决策树能够处理非线性和交互效应。
- 易于解释:决策树的结构直观易懂,便于解释。
- 易受过拟合影响:需要剪枝等技术来防止过拟合。
应用场景
决策树回归适用于数据集特征和目标变量之间存在非线性关系的场景,如市场预测、医学诊断等。
6. 支持向量回归(SVR)
支持向量回归(Support Vector Regression, SVR)是支持向量机的扩展,用于回归分析。SVR 寻找一个函数,使得大多数数据点都在一个容忍范围内。
SVR 的优化目标为:
min w , b , ξ , ξ ∗ 1 2 ∥ w ∥ 2 + C ∑ i = 1 n ( ξ i + ξ i ∗ ) \ \min_{w,b,\xi,\xi^*} \frac{1}{2} \|w\|^2 + C \sum_{i=1}^n (\xi_i + \xi_i^*) \ w,b,ξ,ξ∗min21∥w∥2+Ci=1∑n(ξi+ξi∗)
约束条件为:
y i − ( w ⋅ x i + b ) ≤ ϵ + ξ i , ( w ⋅ x i + b ) − y i ≤ ϵ + ξ i ∗ ; ξ i , ξ i ∗ ≥ 0 \ y_i - (w \cdot x_i + b) \leq \epsilon + \xi_i \ , \ (w \cdot x_i + b) - y_i \leq \epsilon + \xi_i^* \ ; \ \xi_i, \xi_i^* \geq 0 yi−(w⋅xi+b)≤ϵ+ξi , (w⋅xi+b)−yi≤ϵ+ξi∗ ; ξi,ξi∗≥0
其中, ϵ \ \epsilon ϵ 是容忍范围, ξ i \ \xi_i ξi和 ξ i ∗ \ \xi_i^* ξi∗是松弛变量, C C C 是惩罚参数。
特点
- 处理非线性关系:通过核方法,SVR 能够处理复杂的非线性关系。
- 鲁棒性强:对噪声和异常值具有较强的鲁棒性。
- 参数选择复杂:需要调优核函数和惩罚参数 C C C。
应用场景
SVR 适用于处理复杂非线性数据的场景,如股票价格预测、能源消耗预测等。
三 回归算法的 Python 实现
下面通过 Python 代码实现上述回归算法,并以一个示例数据集展示其应用。
导入库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression, Ridge, Lasso, ElasticNet
from sklearn.tree import DecisionTreeRegressor
from sklearn.svm import SVR
from sklearn.metrics import mean_squared_errorplt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
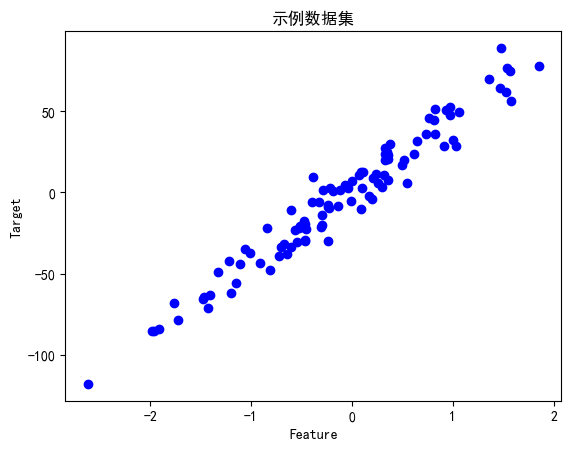
生成示例数据集
# 生成示例数据集
X, y = make_regression(n_samples=100, n_features=1, noise=10, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)plt.scatter(X, y, color='blue')
plt.title('Sample Data')
plt.xlabel('Feature')
plt.ylabel('Target')
plt.show()
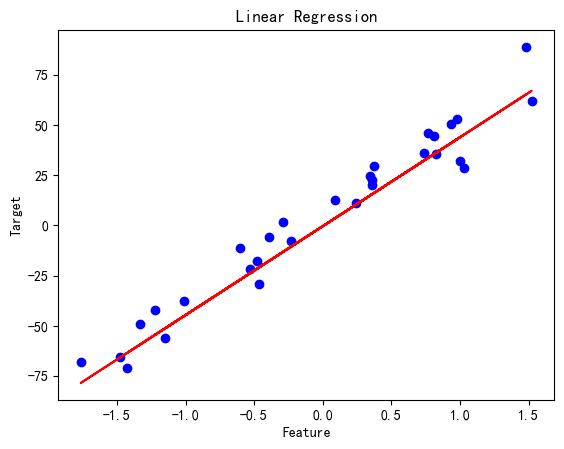
线性回归
# 线性回归
linear_reg = LinearRegression()
linear_reg.fit(X_train, y_train)
y_pred = linear_reg.predict(X_test)print('Linear Regression MSE:', mean_squared_error(y_test, y_pred))plt.scatter(X_test, y_test, color='blue')
plt.plot(X_test, y_pred, color='red')
plt.title('Linear Regression')
plt.xlabel('Feature')
plt.ylabel('Target')
plt.show()
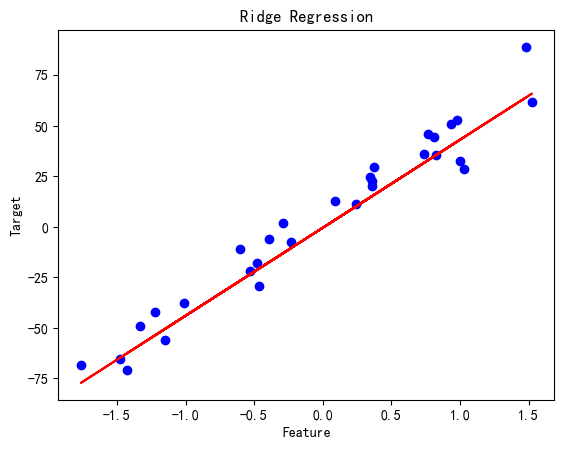
岭回归
# 岭回归
ridge_reg = Ridge(alpha=1.0)
ridge_reg.fit(X_train, y_train)
y_pred = ridge_reg.predict(X_test)print('Ridge Regression MSE:', mean_squared_error(y_test, y_pred))plt.scatter(X_test, y_test, color='blue')
plt.plot(X_test, y_pred, color='red')
plt.title('Ridge Regression')
plt.xlabel('Feature')
plt.ylabel('Target')
plt.show()
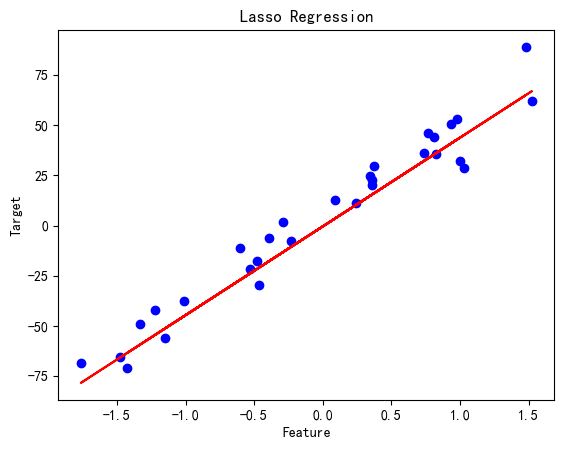
Lasso 回归
# Lasso 回归
lasso_reg = Lasso(alpha=0.1)
lasso_reg.fit(X_train, y_train)
y_pred = lasso_reg.predict(X_test)print('Lasso Regression MSE:', mean_squared_error(y_test, y_pred))plt.scatter(X_test, y_test, color='blue')
plt.plot(X_test, y_pred, color='red')
plt.title('Lasso Regression')
plt.xlabel('Feature')
plt.ylabel('Target')
plt.show()
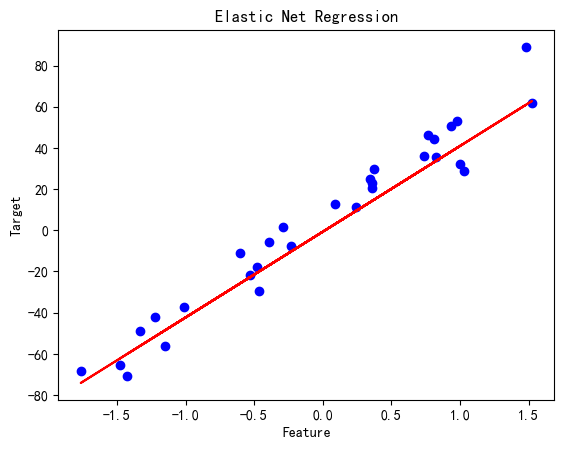
弹性网络回归
# 弹性网络回归
elastic_net_reg = ElasticNet(alpha=0.1, l1_ratio=0.5)
elastic_net_reg.fit(X_train, y_train)
y_pred = elastic_net_reg.predict(X_test)print('Elastic Net Regression MSE:', mean_squared_error(y_test, y_pred))plt.scatter(X_test, y_test, color='blue')
plt.plot(X_test, y_pred, color='red')
plt.title('Elastic Net Regression')
plt.xlabel('Feature')
plt.ylabel('Target')
plt.show()
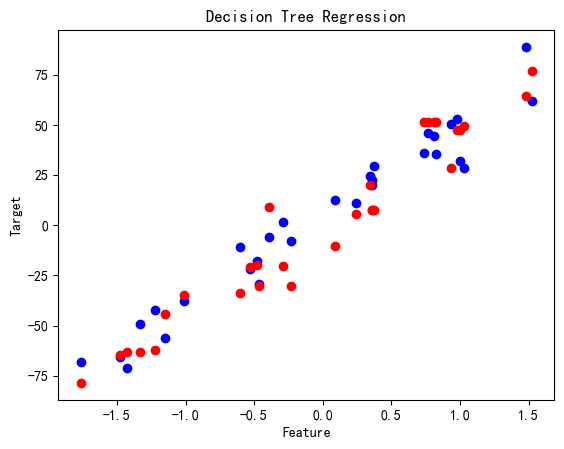
决策树回归
# 决策树回归
tree_reg = DecisionTreeRegressor()
tree_reg.fit(X_train, y_train)
y_pred = tree_reg.predict(X_test)print('Decision Tree Regression MSE:', mean_squared_error(y_test, y_pred))plt.scatter(X_test, y_test, color='blue')
plt.scatter(X_test, y_pred, color='red')
plt.title('Decision Tree Regression')
plt.xlabel('Feature')
plt.ylabel('Target')
plt.show()
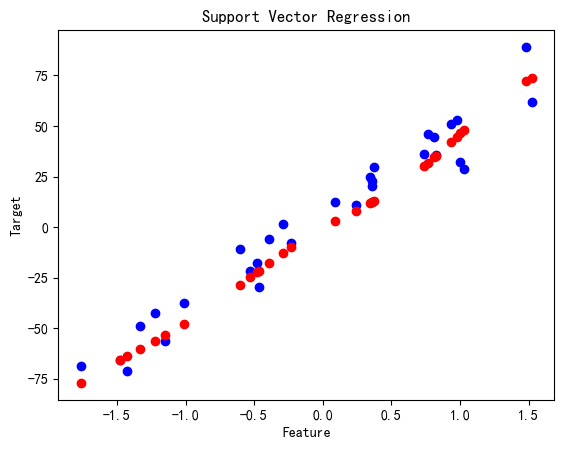
支持向量回归(SVR)
# 支持向量回归
svr_reg = SVR(kernel='rbf', C=100, epsilon=0.1)
svr_reg.fit(X_train, y_train)
y_pred = svr_reg.predict(X_test)print('SVR MSE:', mean_squared_error(y_test, y_pred))plt.scatter(X_test, y_test, color='blue')
plt.scatter(X_test, y_pred, color='red')
plt.title('Support Vector Regression')
plt.xlabel('Feature')
plt.ylabel('Target')
plt.show()
总结
回归分析是机器学习中的一类重要方法,用于预测连续变量。本文介绍了几种常见的回归算法,包括线性回归、岭回归、Lasso 回归、弹性网络回归、决策树回归和支持向量回归,并展示了它们的数学公式、特点、应用场景及其在 Python 中的实现。不同的回归算法适用于不同的应用场景,通过合理选择算法,可以在实际应用中取得良好的预测效果。希望本文能帮助你更好地理解和应用回归算法。
这篇关于回归算法详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!