本文主要是介绍Socket 原理和思考,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
众所周知Reactor是一种非常重要和应用广泛的网络编程模式,而Java NIO是Reactor模式的一个具体实现,在Netty和Redis都有对其的运用。而不管上层模式如何,底层都是走的Socket,对底层原理的了解会反哺于上层,避免空中楼阁现象。
所以本文对Socket原理及其中值得关注的点作再次梳理,最终目标还是为了理解Reactor及NIO。
Socket简介
- Socket用于网络进程间通信,当然单机上不同进程间也行。
- Socket位于五层网络模型中的应用层和传输层之间,是一种抽象层,也是一组接口,把复杂的TCP/IP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部,让Socket去组织数据,应用层也能更便捷在网络间进行数据传输。
本文对Socket基础原理不做过多介绍,可以参考: https://blog.csdn.net/qq_39208536/article/details/137589718 https://blog.csdn.net/qq_39208536/article/details/137589718
https://blog.csdn.net/qq_39208536/article/details/137589718
传统Socket编程
虽然现在几乎不用再涉及原生Socket编程,但这些代码对理解原理还是有用的。
Server端:
public class MySocketServer {private static ExecutorService executorService = Executors.newCachedThreadPool();public static void main(String[] args) throws IOException, InterruptedException {//服务端的主线程是用来循环监听客户端请求ServerSocket server = new ServerSocket(8686);//创建一个服务端且端口为8686Socket client = null;System.out.println("服务端启动");//循环监听while (true) {//服务端监听到一个客户端请求System.out.println("阻塞等待accept....");client = server.accept();System.out.println(client.getRemoteSocketAddress() + "地址的客户端连接成功!");//将该客户端请求通过线程池放入HandlMsg线程中进行处理executorService.submit(new HandleMsg(client));}}public static void handle(Socket client) {//创建字符缓存输入流BufferedReader bufferedReader = null;//创建字符写入流PrintWriter printWriter = null;try {//获取客户端的输入流bufferedReader = new BufferedReader(new InputStreamReader(client.getInputStream()));//获取客户端的输出流,true是随时刷新printWriter = new PrintWriter(client.getOutputStream(), true);String inputLine = null;long a = System.currentTimeMillis();Thread.sleep(1000);while ((inputLine = bufferedReader.readLine()) != null) {printWriter.println("hello " + inputLine);}long b = System.currentTimeMillis();System.out.println(Thread.currentThread().getName() + "线程结束,花费了:" + (b - a) + "ms");} catch (IOException | InterruptedException e) {e.printStackTrace();} finally {try {bufferedReader.close();printWriter.close();client.close();} catch (IOException e) {e.printStackTrace();}}}//一旦有新的客户端请求,创建这个线程进行处理private static class HandleMsg implements Runnable {//创建一个客户端Socket client;public HandleMsg(Socket client) {this.client = client;}@Overridepublic void run() {handle(client);}}
}Client端:
public class MySocketClient {public static void main(String[] args) throws IOException {for (int i = 0; i < 5; i++) {new Thread(new Runnable() {@SneakyThrows@Overridepublic void run() {callServer();}}).start();}}public static void callServer() throws IOException {Socket client = null;PrintWriter printWriter = null;BufferedReader bufferedReader = null;try {client = new Socket();// 连接超时client.connect(new InetSocketAddress("localhost", 8686), 100);// 读写超时
// client.setSoTimeout(10);printWriter = new PrintWriter(client.getOutputStream(), true);printWriter.println(Thread.currentThread().getName());printWriter.flush();System.out.println(Thread.currentThread().getName() + " " + "等待服务端消息...");bufferedReader = new BufferedReader(new InputStreamReader(client.getInputStream())); //读取服务器返回的信息并进行输出System.out.println(Thread.currentThread().getName() + " " + "来自服务器的信息是:" + bufferedReader.readLine());} catch (Exception e) {e.printStackTrace();} finally {printWriter.close();bufferedReader.close();client.close();}}
}创建Socket的时候操作系统创建了什么
- Unix/Linux基本哲学之一就是“一切皆文件”,都可以用“打开open –> 读写write/read –> 关闭close”模式来操作,Socket就是该模式的一个实现。Socket即是一种特殊的文件,一些Socket函数就是对其进行的操作。
- 客户端或服务端Socket创建后,操作系统为其会分配:
- 文件描述符(区别文件句柄),用于操作Socket,参考:https://blog.csdn.net/tjcwt2011/article/details/122685933 https://zhuanlan.zhihu.com/p/364617329https://zhuanlan.zhihu.com/p/364617329 https://blog.csdn.net/tjcwt2011/article/details/122685933
- 位于内核的发送缓冲区、接收缓冲区。
- 其他数据结构,暂不讨论。
-
Socket传输数据经历的过程
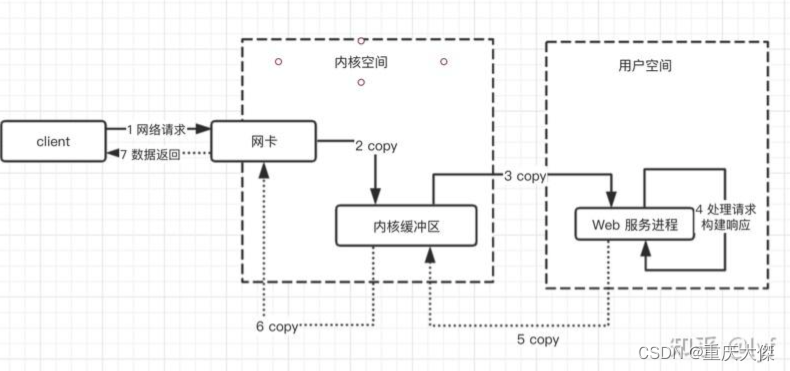
网卡也是有缓冲区的,暂不讨论。
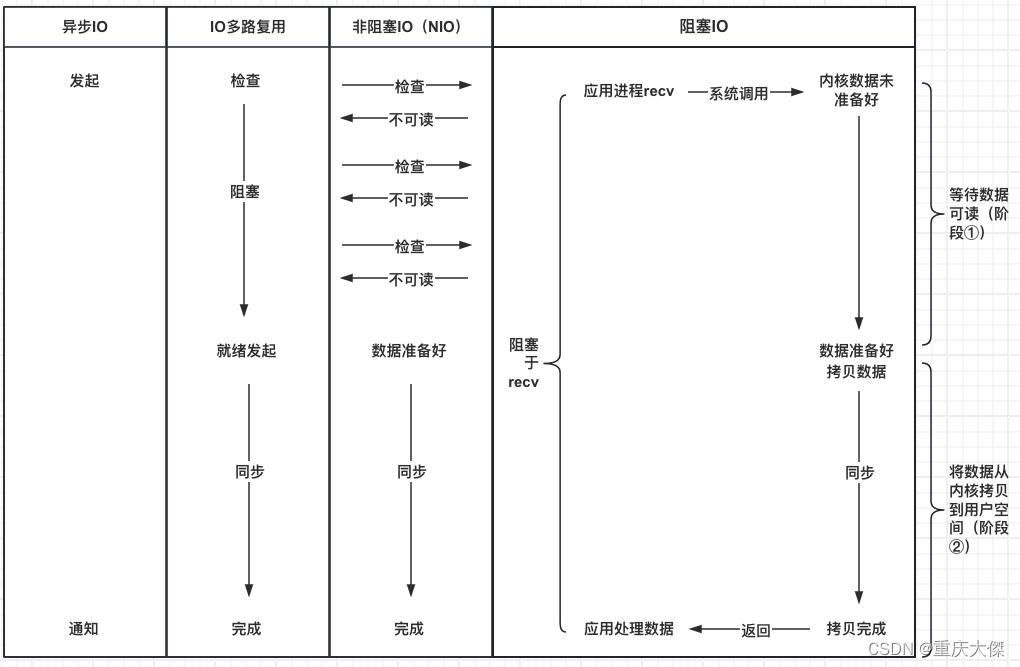
阻塞、非阻塞与同步、异步的关系
看了很多文章对这两组概念解释和对比,说的太复杂了,其实没必要,两句话就能说清楚。
首先,对于读数据recv或read(写数据同理,没写出来),分两个阶段:
- 等待数据可读。
- 系统调用讲数据从内核拷贝到用户空间。
然后,再对比那两组概念:
- 阻塞、非阻塞是对于等待数据可读、可写时,是否死等;
- 同步、异步是对于数据在用户空间和内核传递时,是否等待其完成;
结合这四种LinuxIO模型对比(一般讨论LinuxIO模型会有五种,其中信号驱动IO用得太少,暂不讨论。
可以得出结论: 阻塞IO、非阻塞IO、多路复用都属于同步IO!区别于异步IO。
注意:我们之前说的复习Socket还是为了进一步学习NIO和Reactor模式,这里有几点需要区分原生Socket和NIO:
- 原生Socket在创建的时候也可以指定为阻塞或非阻塞模式。原生非阻塞Socket编程较复杂,比如可能需要循环判断send和recv的数据量是否完整,故一般不会轻易挑战。
- 原生Socket也是可以直接编程实现多路复用的,参考: SOCKET编程与复用 | YuYoung's Blog
- NIO底层实现也是操作的原生Socket,可以看作是对以上两点的包装,使用NIO来操作非阻塞IO就方便多了。
发送缓冲区和接收缓冲区
1,send在本质上并不是向网络上发送数据,而是将应用层发送缓冲区的数据 拷贝到内核缓冲区 中,至于数据什么时候会从网卡缓冲区中真正的发到网络中,要根据TCP/IP协议栈的行为来确定。recv在本质上并不是从网络上收取数据,而是将 内核缓冲区中的数据拷贝到 应用程序的缓冲区中,也就是说从网络接收数据时,TCP/IP协议栈会把数据收下来放在内核的接收缓冲区内。
2,如果接收缓冲区一直满着堆积,没有recv读取,网卡缓冲区也满,网络发过来的数据怎么存?只有当接收网络报文的速度大于应用程序读取报文的速度时,可能使读缓存达到了上限,这时这个缓存使用上限才会起作用。所起作用为:丢弃掉新收到的报文,防止这个TCP连接消耗太多的服务器资源。同样,当应用程序发送报文的速度大于接收对方确认ACK报文的速度时,写缓存可能达到上限,从而使send方法阻塞或失败。
3,当待发送(拷贝)的数据的长度大于发送缓冲区的长度,是如何发送的?一次send调用,但TCP/IP协议栈可能会分多帧发送,参考:https://blog.csdn.net/aflyeaglenku/article/details/73614292
4,recv和send不一定是一一对应的,也就是说并不是send一次,就一定recv一次就接收完,有可能send一次,recv多次才接收完,也有可能send多次,一次recv就接收完了。
缓冲区可读、可写的判断条件
1,接收低水位和发送低水位
每个套接字有一个接收低水位和一个发送低水位。他们由select函数使用。
- 接收低水位标记:让select返回“可读”时接收缓冲区中所需的数据量。对于TCP默认值为1。
- 发送低水位标记:让select返回“可写”时发送缓冲区中所需的可用空间。对于TCP,其默认值常为2048。
2,引用《Unix网络编程》中的可读可写条件
当满足下列条件之一时,一个套接字准备好读:
- 该套接字接收缓冲区中的数据字节数大于等于套接字接收缓冲区低水位标记的当前大小。对这样的套接字执行读操作不会阻塞并将返回一个大于 0 的值(也就是返回准备好读入的数据)。我们可以使用
SO_RCVLOWAT套接字选项设置该套接字的低水位标记。对于 TCP 和 UDP 套接字而言,其默认值为 1。 - 该连接的读半部关闭(也就是接收了 FIN 的 TCP 连接)。对这样的套接字的读操作将不阻塞并返回 0 (也就是返回 EOF)。
- 该套接字是一个监听套接字且已完成的连接数不为 0。对这样的套接字的 accept 通常不会阻塞。
- 其上有一个套接字错误待处理。对这样的套接字的读操作将不阻塞并返回 -1(也就是返回一个错误),同时把
errno设置成确切的错误条件。这些待处理错误也可以通过指定SO_ERROR套接字选项调用getsockopt获取并清除。
当满足下列条件之一时,一个套接字准备好写:
- 该套接字发送缓冲区中的可用空间字节数大于等于套接字发送缓冲区低水位标记的当前大小,并且要求该套接字已连接(TCP)或者不需要连接(UDP)。这意味着如果我们把这样的套接字设置为非阻塞,写操作将不阻塞并返回一个正值(例如由传输层接收的字节数)。我们可以使用
SO_SNDLOWAT套接字选项来设置该套接字的低水位标记。对于 TCP 和 UDP 套接字而言,其默认值通常为 2048。 - 该连接的写半部关闭,对这样的套接字的写操作将产生
SIGPIPE信号。 - 使用非阻塞式
connect的套接字已建立连接,或者已经以失败告终。 - 其上有一个套接字错误待处理。对这样的套接字的写操作将不阻塞并返回 -1(也就是返回一个错误),同时把
errno设置成确切的错误条件。这些待处理的错误也可以通过指定SO_ERROR套接字选项调用getsockopt获取并清除。
当缓冲区满了时,发送或接收数据会怎样?

这篇关于Socket 原理和思考的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!