本文主要是介绍项目三OpenStack基础环境配置与API使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
任务一 了解OpenStack基础环境配置
1.1 •数据库服务器

1.2 •消息队列服务
•AMQP系统的组成


任务二 了解并使用OpenStack API
2.1 •什么是RESTful API
2.2 •OpenStack的RESTful API
(1)客户端通过HTTP发送请求,调用openstack server list命令。
(2)路由模块收到HTTP请求后,将这个请求分派给对应的控制器(Controller),并且绑定一个操作(Action)。
(3)每个控制器都对应一个RESTful资源,控制器是对应资源的操作集合。
GET /v3/users:获取所有用户的列表。
POST /v3/users:创建一个用户。
GET /v3/users/<UUID>:获取一个特定用户的详细信息。
PUT /v3/users/<UUID>:修改一个用户的详细信息。
DELETE /v3/users/<UUID>:删除一个用户。
对资源的操作
2.3 •OpenStack的认证与API请求流程
(1)为云管理员提供的身份端点请求一个认证令牌。
(2)如果请求成功,服务器会返回一个认证令牌。
(3)发送API请求,在X-Auth-Token头部需包含上一步返回的认证令牌。
(4)如果遇到未授权(401)的错误,则需重新请求另一个令牌。
2.4 •调用OpenStack API的方式
2.5 •获取OpenStack认证令牌
(1)导出环境变量
OS_PROJECT_NAME(项目名)
OS_PROJECT_DOMAIN_NAME(项目域名)
OS_USERNAME(用户名)
OS_PASSWORD(密码)
OS_USER_ DOMAIN_NAME(用户域名)
(2)运行cURL命令向OpenStack云平台请求一个令牌。
2.6 •向OpenStack云平台发送API请求
(1)导出环境变量OS_TOKEN,将其值设为令牌ID。
(2)导出环境变量OS_PROJECT_NAME。
export OS_PROJECT_NAME=demo
(3)导出环境变量OS_COMPUTE_API。
export OS_COMPUTE_API=http://192.168.199.31:8774/v2.1
(4)访问计算服务API,列出可用的实例类型。
[root@node-a ~(keystone_demo)]# curl -s -H "X-Auth-Token: $OS_TOKEN" $OS_COMPUTE_ API/servers | python -m json.tool
任务三 使用OpenStack命令行客户端
3.1 •为什么要使用命令行操作OpenStack
★★命令行操作不够直观,不适合为普通云用户提供服务,通常是云管理员使用命令行进行配置、管理和测试等工作。
3.2 •进一步了解OpenStack客户端
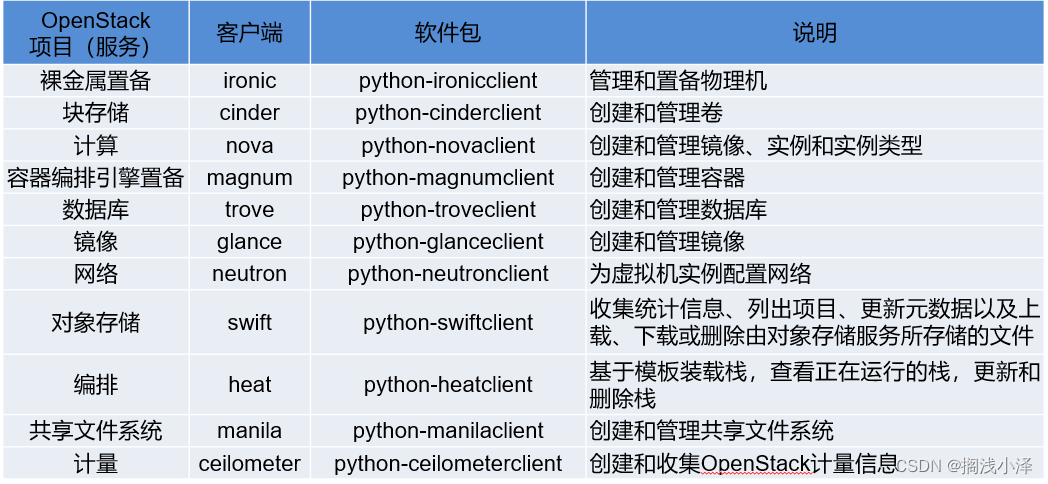
3.3 •openstack命令的语法
openstack [<全局选项>] <命令> [<命令参数>]
openstack --help
openstack help <命令>
openstack --os-identity-api-version 3 --help
3.4 •执行openstack命令所需的认证
export OS_AUTH_URL=<用于认证的URL地址>
export OS_PROJECT_NAME=<项目名>
export OS_USERNAME=<用户名>
export OS_PASSWORD=<密码
3.5 •云管理员通过openstack命令管理OpenStack云平台
(1)执行命令加载云管理员admin的环境脚本。
[root@node-a ~(keystone_demo)]# source keystonerc_admin
(2)通过openstack命令调用身份服务API来列出所有的项目。
[root@node-a ~(keystone_admin)]# openstack project list
(3)通过openstack命令调用身份服务API来查看services项目的详细信息。
[root@node-a ~(keystone_admin)]# openstack project show services
3.6 普通云用户通过openstack命令使用OpenStack云服务
(1)加载云用户demo的环境脚本。
[root@node-a ~]# source keystonerc_demo
(2)调用计算服务API,列出该用户所关联的项目和当前可用的镜像。
[root@node-a ~(keystone_demo)]# openstack image list
(3)列出可用的实例类型(flavors)。
[root@node-a ~(keystone_demo)]# openstack flavor list
(4)创建一个实例。
[root@node-a ~(keystone_demo)]# openstack server create --image cirros --flavor 1 Cirros_VM1
这篇关于项目三OpenStack基础环境配置与API使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









