本文主要是介绍麻省理工IOT教授撰写的1058页Python程序设计人工智能实践手册!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
为什么要学习Python?
Python简单易学,且提供了丰富的第三方库,可以用较少的代码完成较多的工作,使开发者能够专注于如何解决问题而只花较少的时间去考虑如何编程。此外,Python还具有免费开源、跨平台、面向对象、胶水语言等优点,在系统编程、图形界面开发、科学计算、Web开发、数据分析、人工智能等方面有广泛应用。尤其是在数据分析和人工智能方面,Python已成为最受开发者欢迎的编程语言之一,不仅大量计算机专业人员选择使用Python进行快速开发,许多非计算机专业人员也纷纷选择Python语言来解决专业问题。
由于Python应用广泛,关于Python的参考书目前已经有很多,但将Python编程与数据分析、人工智能等领域紧密结合的参考书尚不多见。这就导致开发者在学习Python编程时难以与实际应用结合,从而造成不知道如何应用Python去解决实际问题的状况。2019年,全球畅销的编程语言教材、专业图书作家Paul Deitel和Harvey Deitel出版了Python forProgrammers一书,书中将Python编程基础知识与数据分析、人工智能案例研究有效地结合在一起,在Python编程与数据科学、人工智能之间搭建起了桥梁。通过学习本书,开发者可结合理论和实践,快速掌握应用Python解决数据分析、人工智能问题的方法
👉【CSDN大礼包:《Python安装工具、全套学习资料》免费分享 安全链接,放心点击

第一部分:Python基础知识快速入门
- 第1章 Python及大数据概述
- 第2章 Python程序设计概述
- 第3章 控制语句
- 第4章 函数
- 第5章 序列:列表和元组
第1章Python及大数据概述
- 了解计算机领域令人兴奋的最新发展。
- 回顾面向对象编程的基础知识。
- 了解Python的优势。
- 了解将要在本书中使用的主要的Python库和数据科学库。
- 练习使用IPython解释器以交互模式执行Python代码。
- 执行一个制作动态柱状图的Python脚本。
- 使用基于Web浏览器的Jupyter Notebook创建并运行Python代码。
- 了解“大数据”到底有多大,以及它如何快速地变得越来越大。
- 阅读一个关于流行的移动导航APP的大数据案例研究。
- 认识人工智能—一个计算机科学和数据科学的交叉学科。



👉【CSDN大礼包:《Python安装工具、全套学习资料》免费分享 安全链接,放心点击
第2章Python程序设计概述
- 继续使用IPython交互模式输入代码段并立即查看执行结果。
- 编写简单的Python语句和脚本。
- 掌握创建变量来存储数据的方法。
- 熟悉内置数据类型。
- 学会使用算术运算符和比较运算符,了解它们的优先级。
- 学会使用单引号、双引号和三引号字符串。
- 学会使用内置函数print显示文本。
- 学会使用内置函数input提示用户在键盘上输入数据、获取输入的数据,以及在程序中使用这些数据。
- 学会使用内置函数int将文本转换为整型数。
- 学会使用比较运算符和if语句来决定是否执行一条语句或一组语句。
- 了解Python中的对象和动态类型。
- 学会使用内置函数type获取对象的类型。


第3章控制语句
- 使用if、if...else和if...elif...else语句进行决策。
- 使用while和for重复执行语句。
- 使用增强赋值运算符缩短赋值表达式。
- 使用for语句和内置的range函数重复一系列针对值的操作。
- 使用while执行边界值控制的迭代。
- 使用布尔运算符and、or和not创建复合条件。
- 使用break停止循环。
- 使用continue强制执行循环的下一次迭代。
- 利用函数式编程的特点编写更简洁、更清晰、更易于调试和更易于并行化的脚本。


第4章函数
- 创建自定义函数。
- 导入并使用Python标准库模块,如random和math模块,重用代码以避免重复工作。
- 在函数间传递数据。
- 生成一系列随机数。
- 通过随机数生成器了解模拟技术。
- 利用种子控制随机数生成器,保证可重复性。
- 将值打包进元组和解包元组中的值。
- 通过元组从函数返回多个值。
- 理解标识符的作用域如何决定在程序中可以使用它的位置。
- 创建带默认参数的函数。
- 使用关键字参数调用函数。
- 创建可以接收不定长参数的函数。
- 使用对象的方法。
- 编写并使用递归函数


第5章序列:列表和元组
- 创建和初始化列表和元组。
- 访问列表、元组和字符串的元素。
- 对列表排序和搜索,以及搜索元组。
- 在函数和方法中使用列表和元组。
- 使用列表来完成常见操作,例如搜索项目、排序列表、插入项目和删除项目。
- 使用Python其他的函数式编程功能,包括lambda表达式、函数式编程操作过滤器、映射和归约。
- 使用函数式列表推导可以轻松快速地创建列表,并且可以使用生成器表达式按需生成值。
- 使用二维列表。
- 使用Seaborn和Matplotlib可视化库,增强数据分析和演示技巧。
- 这些概念之间的联系不是非常紧密,读者可以有选择性地阅读自己感兴趣的概念

第二部分Python数据结构、字符串和文件
第6章字典和集合
- 使用字典表示键-值对的无序合集。
- 使用集合来表示不重复值的无序合集。
- 创建、初始化、引用字典和集合的元素。
- 遍历字典的键、值和键-值对。
- 添加、删除、更新字典的键-值对。
- 使用字典和集合的比较运算符。
- 用集合运算符和方法来组合集合。
- 使用运算符in和not in确定字典是否包含某个键或值。
- 使用可变集合操作来修改集合的内容。
- 使用推导式快速方便地创建词典和集合。
- 了解如何构建动态可视化内容。
- 增强读者对可变类型和不变类型的理解。


第7章使用NumPy进行面向数组的编程
- 了解数组与列表的不同之处。
- 使用numpy模块的高性能ndarray。
- 用IPython的%timeit魔术命令比较列表和ndarray的性能。
- 使用ndarray有效地存储和检索数据。
- 创建和初始化ndarray。
- 引用单个的ndarray元素。
- 通过ndarray进行迭代。
- 创建和操作多维ndarray。
- 执行普通的ndarray操作。
- 创建和操作pandas一维Series对象和二维DataFrame结构。
- 自定义Series对象和DataFrame结构的索引。
- 在一个Series对象和一个DataFrame结构中计算基本的描述性统计数据。
- 自定义pandas库输出格式中的浮点数精度

第8章字符串:深入讨论
- 理解文本处理。
- 字符串方法的使用。
- 格式化字符串内容。
- 拼接以及重复字符串。
- 去除字符串结尾的空白字符。
- 改变字母的大小写。
- 使用比较运算符对字符串进行比较。
- 在字符串中查找和替换子串。
- 字符串拆分。
- 依据指定的分隔符拼接一组字符串得到单个新字符串。
- 创建并使用正则表达式来匹配字符串中的模式,替换子字符串并验证数据。
- 使用正则表达式的元字符、量词、字符类和分组。
- 了解字符串操作对自然语言处理的重要性。
- 理解数据科学术语—数据整理、数据规整和数据清理。使用正则表
- 达式将数据整理为需要的格式。

第9章文件和异常
- 理解文件和持久数据的概念。
- 读、写和更新文件。
- 读、写CSV文件。CSV是机器学习数据集常用的一种格式。
- 将对象序列化为JSON,或将JSON反序列化为对象。JSON是
- Internet中传输数据时广泛使用的一种数据交换格式。
- 使用with语句确保资源能够正确释放,避免“资源泄露”。
- 使用try语句分隔可能发生异常的代码,并使用关联的except子句处理这些异常。
- 使用try语句的else子句执行代码。只有在try子句的语句序列中没
- 有发生任何异常时else子句中的代码才会执行。
- 使用try语句的finally子句执行代码。无论try子句的语句序列中是否发生异常,finally子句中的代码都会执行。
- 引发异常以指示运行时问题。
- 理解导致异常的函数和方法的回溯。
- 使用pandas加载CSV文件数据到DataFrame中,并进行泰坦尼克号灾难数据集的处理。

第三部分Python高级主题
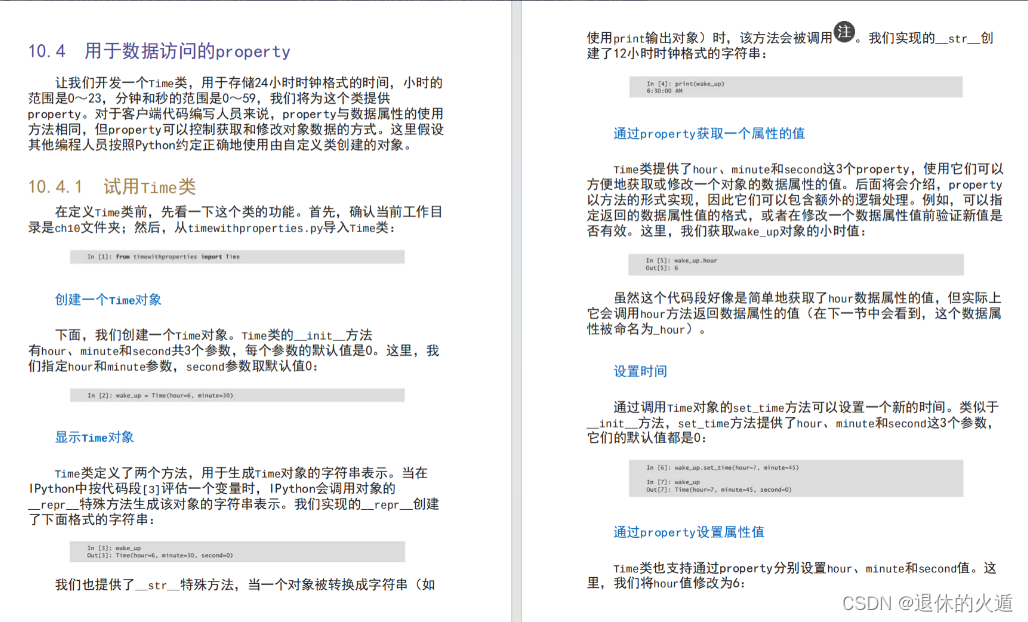
第10章面向对象编程
- 创建自定义类和类对象。
- 理解创建有价值的类的作用。
- 掌握属性的访问控制。
- 理解面向对象的优点。
- 使用Python特殊方法__repr__、__str__和__format__得到对象的字符串表示。
- 使用Python特殊方法重载(重定义)用于新类对象的运算符。
- 从已有类中继承方法和属性到新类中,然后再自定义新类。
- 理解基类(父类)和派生类(子类)的继承概念。
- 理解用于实现“一般化编程”的鸭子类型和多态性。
- 理解所有类继承基本功能的object类。
- 比较组合和继承。
- 将测试用例构建到文档字符串中,并使用doctest运行这些测试。
- 理解命名空间以及它们如何影响作用域。
第四部分人工智能、云和大数据案例研究
第11章自然语言处理

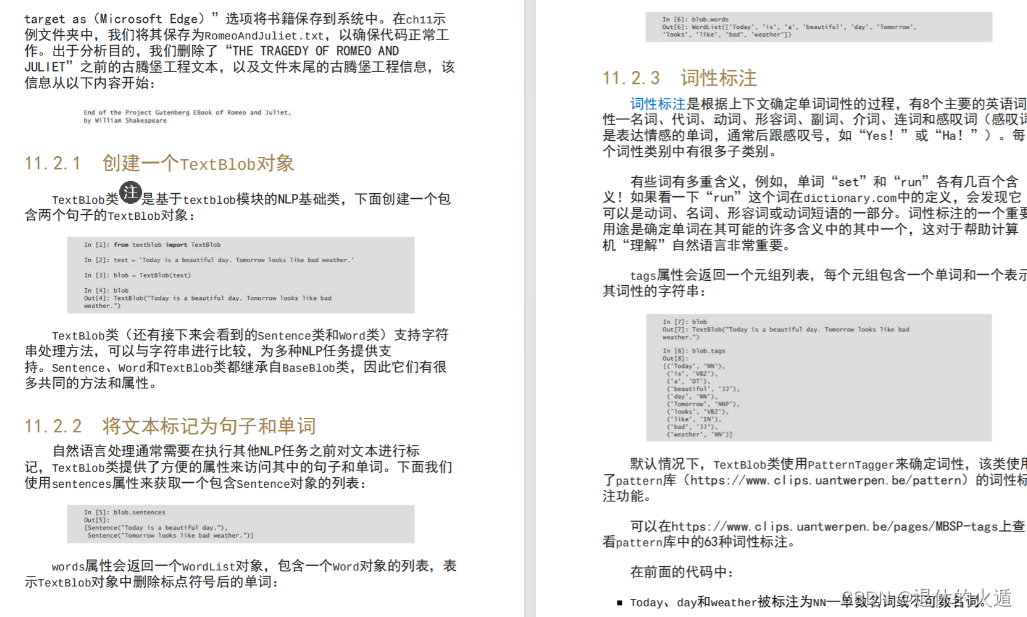
第12章Twitter数据挖掘


第13章IBM Watson和认知计算


第14章机器学习:分类、回归和聚类


第15章深度学习


 第16章大数据:Hadoop、Spark、NoSQL和IoT
第16章大数据:Hadoop、Spark、NoSQL和IoT
- 了解与大数据及其增长速度有关的概念。
- 使用结构化查询语言(SQL)操作SQLite关系数据库。
- 了解NoSQL数据库的四种主要类型。
- 将推文存储在MongoDB NoSQL JSON文档数据库中,并在Folium地图上进行可视化。
- 了解Apache Hadoop及其在大数据批处理应用程序中的使用方法。
- 在Microsoft的Azure HDInsight云服务上构建Hadoop MapReduce应用程序。
- 了解Apache Spark及其在高性能、实时大数据应用程序中的使用方法。
- 使用Spark流处理小批量数据。
- 了解物联网(IoT)和发布/订阅模型。
- 发布来自模拟互联网连接设备的消息,并在仪表板中进行消息可视化。
- 订阅PubNub的实时Twitter和IoT流并进行数据可视化。
👉【CSDN大礼包:《Python安装工具、全套学习资料》免费分享 安全链接,放心点击


这篇关于麻省理工IOT教授撰写的1058页Python程序设计人工智能实践手册!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




