本文主要是介绍CUDA系列-Mem-9,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这里写目录标题
- Static Architecture
- .Abstractions provided by CUSW_UNIT_MEM_MANAGER
- Memory Object (CUmemobj)
- Memory Descriptor(CUmemdesc)
- Memory Block(CUmemblock)
- Memory Bins
- Suballocations in Memory Block
- Functional description
- Memory Manager
你可能觉得奇怪,这些不是cuda programming model中的内容啊,其实这是cuda runtimes ,还记得那份泄漏出来的代码吗?
This section describes static aspects of the CUSW_UNIT_MEM_MANAGER unit’s architecture.
Static Architecture
The CUSW_UNIT_MEM_MANAGER provides abstractions for allocating memory by other units of CUDA driver or from user space applications through CUSW_UNIT_CUDART. It also provides abstractions to share the memory allocated in the Host with the Device.
CUDA driver sees memory allocations in the form of “Memory objects”. A Memory object represents the chunk of memory allocated. It abstracts all layers involved in the memory management and provides APIs to other units of CUDA driver to allocate/free and map/unmap memory along with other auxiliary functionalities.
To avoid fragmentation of memory, the memory objects are allocated from a bigger fixed size “Memory Block”. Each Memory block has a “Memory Descriptor” which contains all the memory attributes associated with a memory block. The “Memory Manager” maintains all the memory blocks which are allocated in a given CUDA context.
The diagram below shows how CUSW_UNIT_MEM_MANAGER interfaces with different units of CUDA driver. Since memory management needs support from the underlying drivers, CUSW_UNIT_MEM_MANAGER depends on the NVRM driver to accomplish its tasks in memory management. In line with the top-level architectural philosophy (refer to the CUDA Architecture document), the unit also contains parts of Hardware Abstraction Layer (HAL) and Driver Model Abstraction layer (DMAL), which it uses internally.
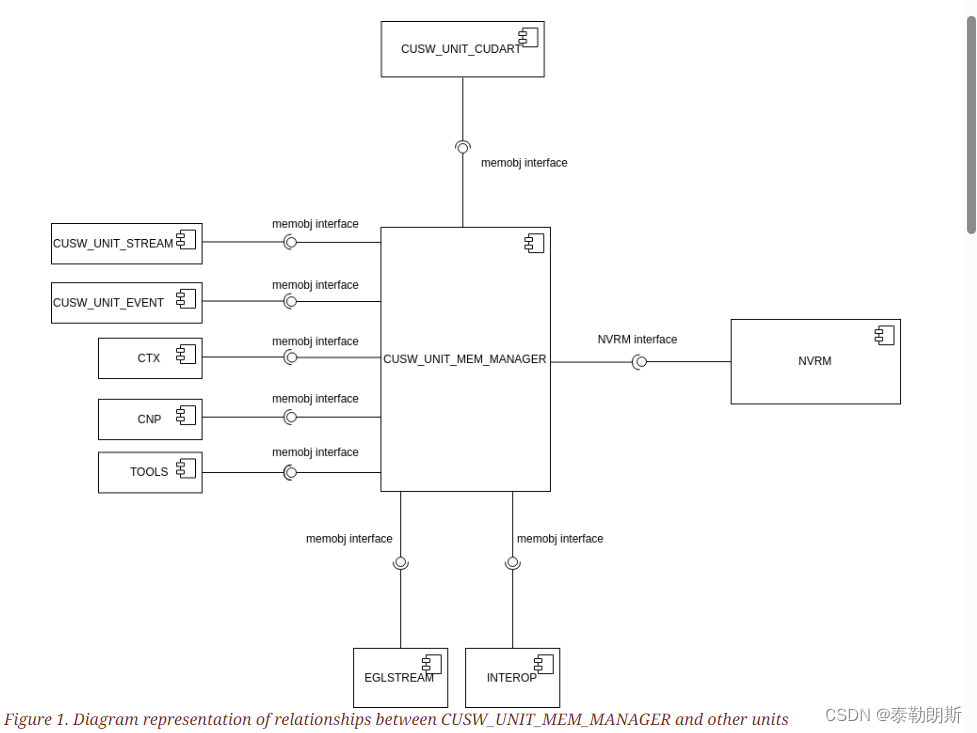
.Abstractions provided by CUSW_UNIT_MEM_MANAGER
CUSW_UNIT_MEM_MANAGER primarily consists of three types of abstractions. The Memory object, Memory Descriptor and the Memory Manager. This section describes each abstraction in detail.
Memory Object (CUmemobj)
A memory object represents a memory allocation. It contains the size, device virtual address, host virtual address and other related information about a memory allocation. It is also possible for one context to share memory with other, in which case the memory object also contains the sharing information. Memory object abstracts all underlying implementation and is the only way for other units in the CUDA driver to interface with CUSW_UNIT_MEM_MANAGER.
Functional description
Memory Object abstraction provides functionalities to
Map/unmap an existing memory object to host memory.
Get parent block’s CUmemflags/CUmemdesc for a given memory object.
To get the data needed to share given memory object with another context.
To get the absolute device virtual address of memory object.
To get the memory object for a given Virtual Address or Range.
To get the user-visible device pointer/host pointer for a given memory object and vice versa.
To get the logical byte size of a given memory object.
To get the context of a given memory object.
To get the shared instance of a given memory object.
To check if the memory allocated in host/device and its associated cache attributes.
To check if the memory allocated is pinned/managed memory.
To execute the given cache operation on cpu side on the memory region pointed by given memory object.
To Mark/Unmark the given memory object to ensure that synchronous memory operations on the given memory object are always fully synchronous.
Memory Descriptor(CUmemdesc)
Memory descriptor contains memory attributes associated with a memory allocation.
While requesting for memory, the other units of CUDA driver can provide specific attributes for the memory allocation request. To get/set the attributes for a memory allocation, other units of the CUDA driver can use the interfaces provided by the Memory object.
Memory Block(CUmemblock)
Memory block is a superblock which encapsulates the physical allocation.
Each Memory Block is associated with a Memory Descriptor as explained above which describes the attributes of the memory block. It contains a OS specific structure(dmal) to hold OS driver specific handles and data. The size of a particular memory block is based on specified memory type(like pushbuffer, generic etc) and arch specific requirements for the MMU. Generally the size of a memory block is the size of HUGE Page supported by the Device. Memory block can be created with shared allocation from another context.
Memory Bins
An effective method of avoiding fragmentation of memory is by grouping similar sized allocations together. Since the size of the memory block is big, sub-allocations can be made inside a memory block. Memory bins try to achieve that by creating bins of varying size and associating each memory block with it. For example, 5 bins are created with size 1KB, 4KB, 16KB, 64KB and 256KB during initialization of memory manager. During a memory allocation request when a new memblock is created, based on the allocation request size one of the above memory bin is assigned to the memblock. Future similar sized allocations requests are serviced by suballocating from that memblock.
Suballocations in Memory Block
During a memory allocation request, efforts are made to find an already existing suitable Memory Block which has the same memory attributes(in the form of Memory descriptor) as that of the incoming request and has free area in which the requested size worth of memory can be safely allocated. If such a memory block is found and it belongs to the same memory bin as that of requested size then memory will be sub allocated in that block and a memory object is created to represent the same and returned, otherwise new block is created.
Functional description
Memory Block abstraction provides some functionalities which are used internally and not exposed to components outside CUDA memory manager.
Alloc/Free memblock
Allocate UVA for a given memblock
Map/Unmap given memblock to host
Map/Unmap given memblock to device
To get memory range based on the kind of device mapping chosen
To get the UVA address for a given memblock
Memory Manager
Memory allocations happen within a CUDA Context. So each CUDA context has an instance of Memory Manager which has data structures to track all memory allocations done in a given CUDA context. It also provides synchronization primitives to protect the common data structures from concurrent access.
CUSW_UNIT_MEM_MANAGER maintains different Virtual Address regions within which the VA is assigned for a particular memory allocation request. The choice of the VA region depends mainly on page size and the requested memory type.
The available memory ranges are
Dptr32 - It is the 32 bit device pointer range to which memory is mapped for special allocations that need 32 bit addresses due to some H/W unit requirements
Function Memory - Function memory range for CUDA GPU function code
Small Page Region - If the requested page size is 4KB then allocations are made in this region
Big Page Region - If the requested page size is device specific page size (64KB or 128KB depending on device architecture) then allocations are made in this region.
The class diagram below depicts the relationship between various data types involved in memory management in cuda driver.

这篇关于CUDA系列-Mem-9的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









