本文主要是介绍基于EasyAnimate模型的视频生成最佳实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
EasyAnimate是阿里云PAI平台自主研发的DiT的视频生成框架,它提供了完整的高清长视频生成解决方案,包括视频数据预处理、VAE训练、DiT训练、模型推理和模型评测等。本文为您介绍如何在PAI平台集成EasyAnimate并一键完成模型推理、微调及部署的实践流程。
背景信息
本文为您介绍以下两种视频生成的方式:
- 方式一:使用DSW
DSW是为算法开发者量身打造的一站式AI开发平台,集成了JupyterLab、WebIDE、Terminal多种云端开发环境,其中,Gallery提供了丰富的案例和解决方案,帮助您快速熟悉研发流程。您可以打开DSW Gallery中的案例教程,实现一键式运行Notebook,完成基于EasyAnimate的视频生成模型的推理和训练任务,也可以进行模型推理和微调等二次开发操作。
- 方式二:使用快速开始
快速开始集成了众多AI开源社区中优质的预训练模型,并且基于开源模型支持零代码实现从训练到部署再到推理的全部过程,您可以通过快速开始一键部署EasyAnimate模型并生成视频,享受更快、更高效、更便捷的AI应用体验。
费用说明
- 如果您的账号为DSW或EAS的新用户,可以免费试用相应产品。关于免费试用的额度、领取方式及注意事项等详细信息,请参见新用户免费试用。
说明:在本教程中,仅支持使用DSW免费资源类型ecs.gn7i-c8g1.2xlarge。
- 如果您的账号非新用户,使用DSW和EAS会产生相应费用。更多计费详情,请参见交互式建模(DSW)计费说明、模型在线服务(EAS)计费说明、快速开始(QuickStart)计费说明。
前提条件
- 创建PAI工作空间。具体操作,请参见开通PAI并创建默认工作空间。
- (可选)开通OSS或NAS。具体操作,请参见开始使用OSS、NAS入门概述。
方式一:使用DSW
步骤一:创建DSW实例
- 进入DSW页面。
- 登录PAI控制台。
- 在概览页面选择目标地域。
- 在左侧导航栏单击工作空间列表,在工作空间列表页面中单击目标工作空间名称,进入对应工作空间内。
- 在工作空间页面的左侧导航栏选择模型开发与训练>交互式建模(DSW),进入DSW页面。
- 单击创建实例。
- 在配置实例向导页面,配置以下关键参数,其他参数保持默认即可。
| 参数 | 说明 |
|---|---|
| 实例名称 | 本教程使用的示例值为:AIGC_test_01 |
| 资源规格 | 选择GPU规格下的ecs.gn7i-c8g1.2xlarge,或其他A10、GU100规格。 |
| 镜像 | 选择官方镜像的easyanimate:1.1.4-pytorch2.2.0-gpu-py310-cu118-ubuntu22.04。 |
| 挂载配置(可选) | 单击添加,单击创建数据集,创建OSS或NAS数据集。 |
- 单击确定。
步骤二:安装EasyAnimate模型
- 打开DSW实例。
- 登录PAI控制台。
- 在左侧导航栏单击工作空间列表,在工作空间列表页面中单击目标工作空间,进入对应工作空间。
- 在页面左上方,选择使用服务的地域。
- 在左侧导航栏,选择模型开发与训练>交互式建模(DSW)。
- 单击目标DSW实例操作列下的打开,进入DSW实例的开发环境。
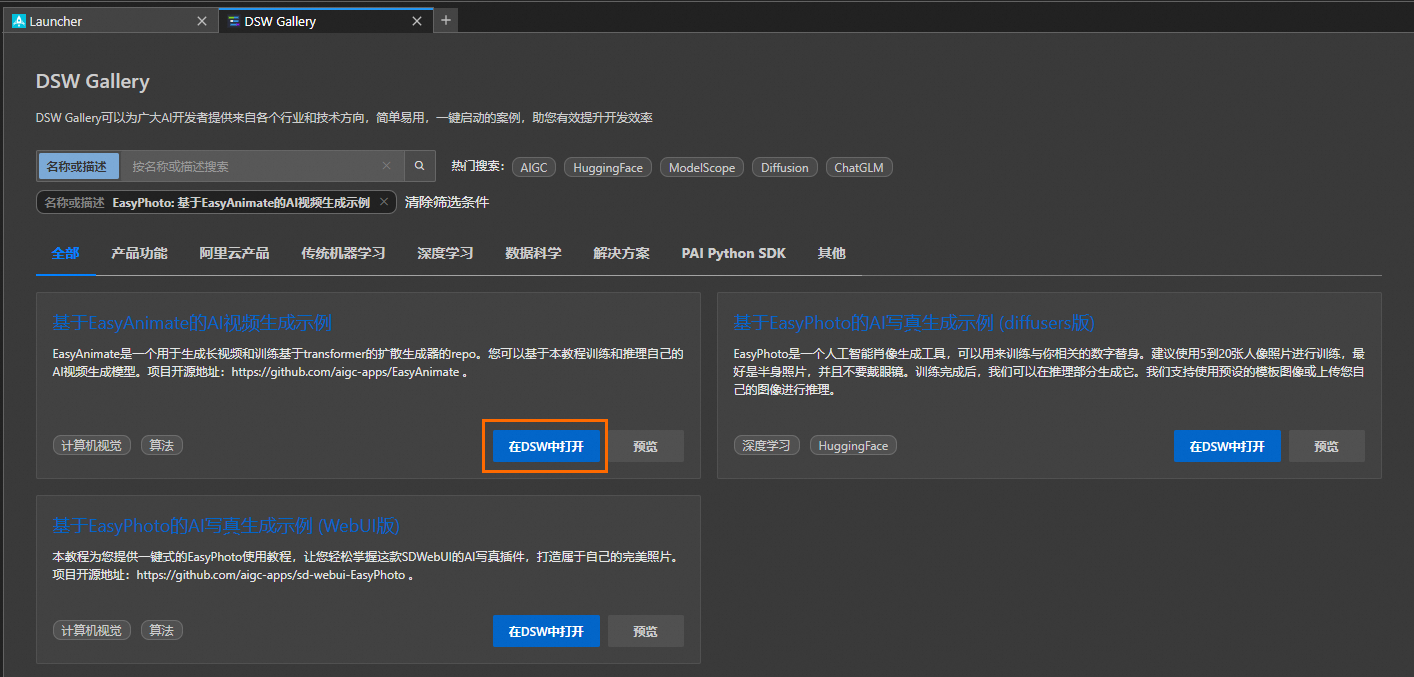
- 在Notebook页签的Launcher页面,单击快速开始区域Tool下的DSW Gallery,打开DSW Gallery页面。
- 在DSW Gallery页面中,搜索EasyPhoto: 基于EasyAnimate的AI视频生成示例,单击在DSW中打开,即可自动将本教程所需的资源和教程文件下载至DSW实例中,并在下载完成后自动打开教程文件。
- 下载EasyAnimate相关代码和模型并进行安装。
在教程文件easyanimate.ipynb中,单击 运行环境安装节点命令,包括定义函数、下载代码和下载模型。当成功运行一个步骤命令后,再顺次运行下个步骤的命令。
运行环境安装节点命令,包括定义函数、下载代码和下载模型。当成功运行一个步骤命令后,再顺次运行下个步骤的命令。
步骤三:推理模型
方式一:使用代码进行推理
单击 运行模型推理>使用代码进行推理节点的命令进行模型推理。您可在**/mnt/workspace/demos/easyanimate/EasyAnimate/samples/easyanimate-videos**目录中查看生成结果。
运行模型推理>使用代码进行推理节点的命令进行模型推理。您可在**/mnt/workspace/demos/easyanimate/EasyAnimate/samples/easyanimate-videos**目录中查看生成结果。
您可以修改不同的参数来达到不同的效果,参数说明:
| 参数名 | 说明 | 类型 |
|---|---|---|
| prompt | 用户输入的正向提示词。 | string |
| negative_prompt | 用户输入的负向提示词。 | string |
| num_inference_steps | 用户输入的步数。 | int |
| guidance_scale | 引导系数。 | int |
| sampler_name | 采样器类型。在生成风景类animation时,采样器 (sampler_name) 推荐使用DPM++和Euler A。在生成人像类animation时,采样器推荐使用Euler A和Euler。 | string |
| width | 生成视频宽度。 | int |
| height | 生成视频高度。 | int |
| video_length | 生成视频帧数。 | int |
| fps | 保存的视频帧率。 | int |
| save_dir | 保存视频文件夹 (相对路径)。 | string |
| seed | 随机种子。 | int |
| lora_weight | LoRA模型参数的权重。 | float |
| lora_path | 额外的LoRA模型路径。用于生成人物视频可以修改为预置的模型路径:models/Personalized_Model/easyanimate_portrait_lora.safetensors | string |
| transformer_path | transformer模型路径。用于生成人物视频可以修改为预置的模型路径:models/Personalized_Model/easyanimate_portrait.safetensors | string |
| motion_module_path | motion_module模型路径。 | string |
方式二:使用WebUI进行推理
- 单击
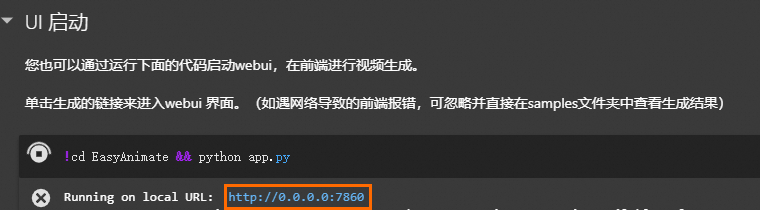
 运行模型推理>UI启动节点的命令,进行模型推理。
运行模型推理>UI启动节点的命令,进行模型推理。 - 单击生成的链接,进入WebUI界面。
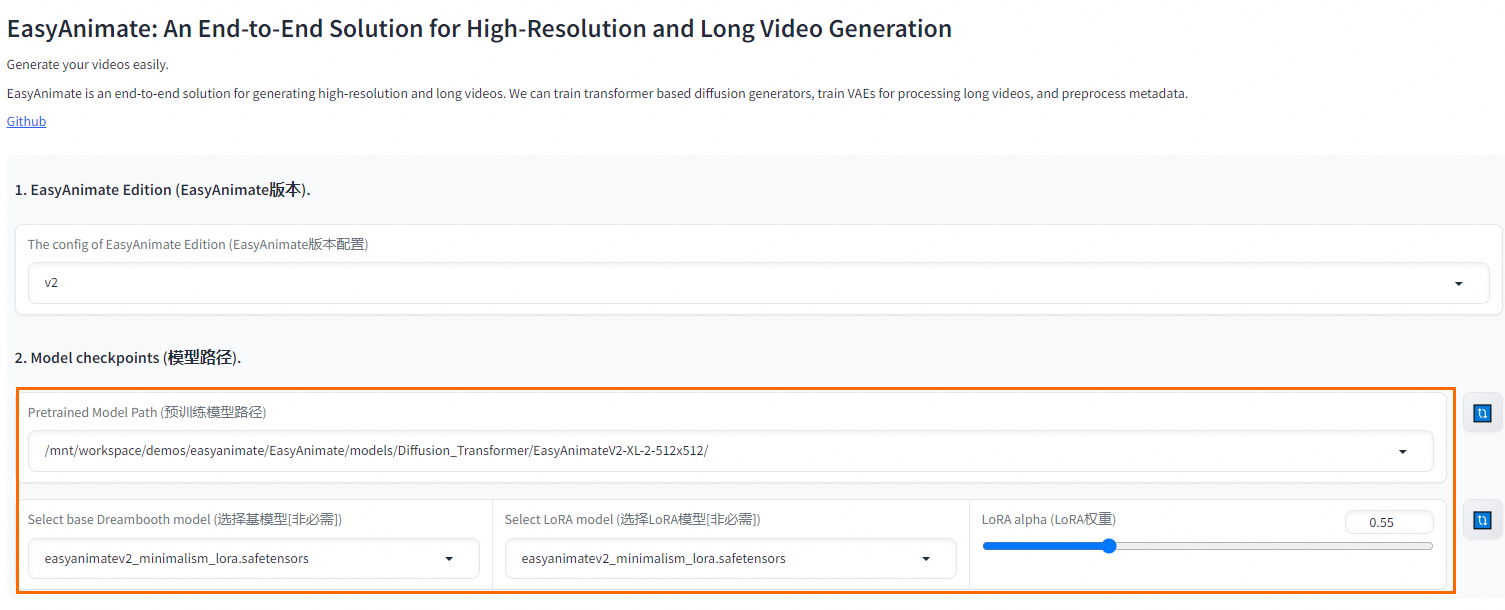
- 在WebUI界面选择预训练的模型路径、微调后的基模型和LoRA模型,设置LoRA权重,其它参数按需配置即可。
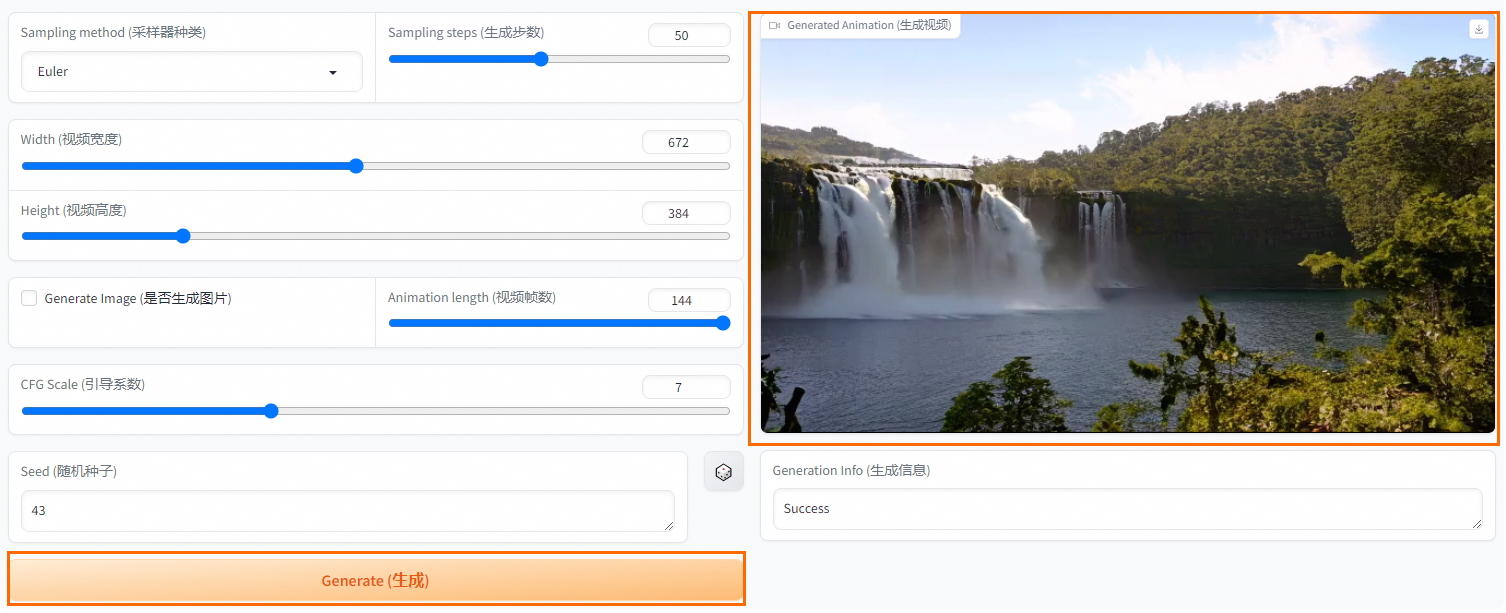
- 单击Generate(生成),等待一段时间后,即可在右侧查看或下载生成的视频。
步骤四:微调LoRA
EasyAnimate提供了丰富的模型训练方式,包括DiT模型的训练(LoRA微调和基模型的全量微调)和VAE的训练。关于Gallery中内置的LoRA微调部分,更多信息,请参见EasyAnimate。
准备数据
单击 执行模型训练>数据准备节点的命令,即可下载示例数据,用于模型训练。您也可以按照如下格式要求自行准备数据文件。
执行模型训练>数据准备节点的命令,即可下载示例数据,用于模型训练。您也可以按照如下格式要求自行准备数据文件。
文件数据格式如下。
project/
├── datasets/
│ ├── internal_datasets/
│ ├── videos/
│ │ ├── 00000001.mp4
│ │ ├── 00000002.mp4
│ │ └── .....
│ └── json_of_internal_datasets.json其中,JSON文件数据格式和参数说明如下。
[{"file_path": "videos/00000001.mp4","text": "A group of young men in suits and sunglasses are walking down a city street.","type": "video"},{"file_path": "videos/00000002.mp4","text": "A notepad with a drawing of a woman on it.","type": "video"}.....
]
| 参数 | 说明 |
|---|---|
| file_path | 视频/图片数据的存放位置(相对路径)。 |
| text | 数据的文本描述。 |
| type | 视频为video,图片为image。 |
训练模型
- 将对应的训练脚本中的DATASET_NAME及DATASET_META_NAME设置为训练数据所在目录及训练文件地址。
export DATASET_NAME=“” # 训练数据所在目录
export DATASET_META_NAME=“datasets/Minimalism/metadata_add_width_height.json” # 训练文件地址
- 单击
 执行启动训练>LoRA训练节点的命令。
执行启动训练>LoRA训练节点的命令。 - 训练完成后,将生成的模型移动至models/Personalized_model文件夹,即可在UI界面中选择,或单击
 执行LoRA模型推理节点的命令,指定lora_path进行视频生成。
执行LoRA模型推理节点的命令,指定lora_path进行视频生成。
方式二:使用快速开始
步骤一:部署模型
- 进入快速开始页面。
- 登录PAI控制台。
- 在左侧导航栏单击工作空间列表,在工作空间列表页面单击目标工作空间名称,进入对应工作空间内。
- 在左侧导航栏单击快速开始,进入快速开始页面。
- 在快速开始页面,搜索EasyAnimate 高清长视频生成,然后单击部署,配置相关参数。
EasyAnimate目前仅支持使用bf16进行推理,请选择A10及其以上的显卡。
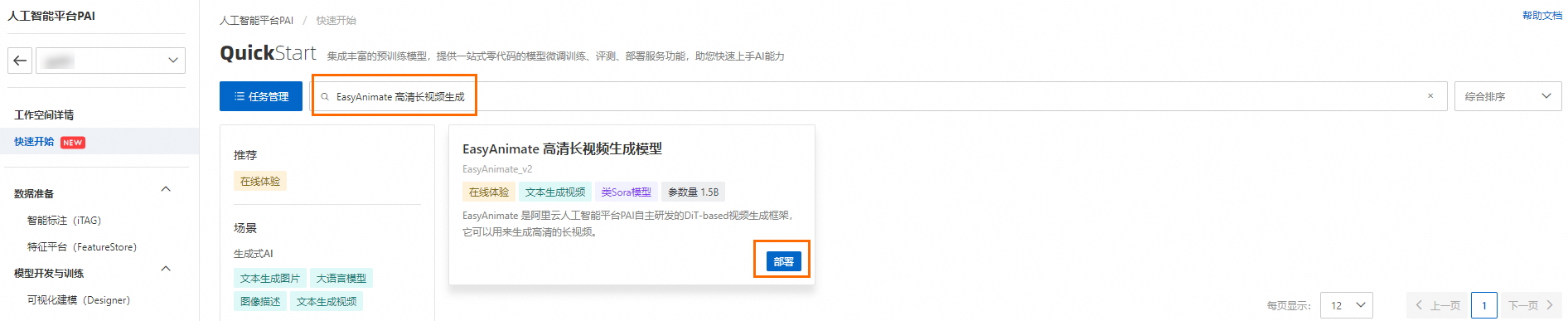
- 单击部署,在弹出的计费提醒对话框中,单击确定,页面将自动跳转到服务详情页面。
当状态变为运行中时,即表示模型部署成功。
步骤二:使用模型
模型部署完成后,您可以使用WebUI及API两种方式调用服务来生成视频。
WebUI方式
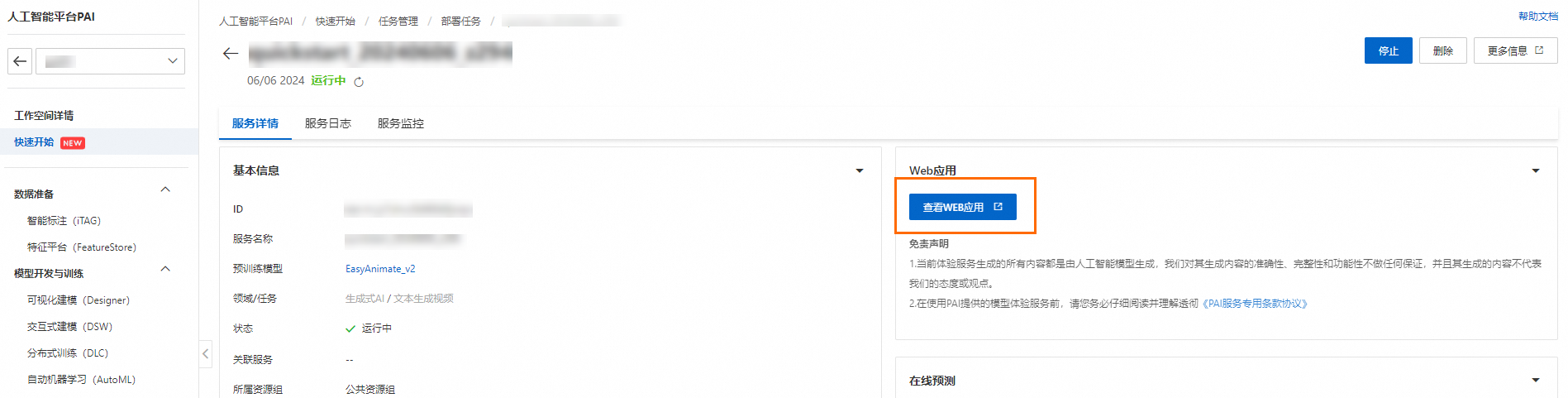
- 在服务详情页面,单击查看WEB应用。
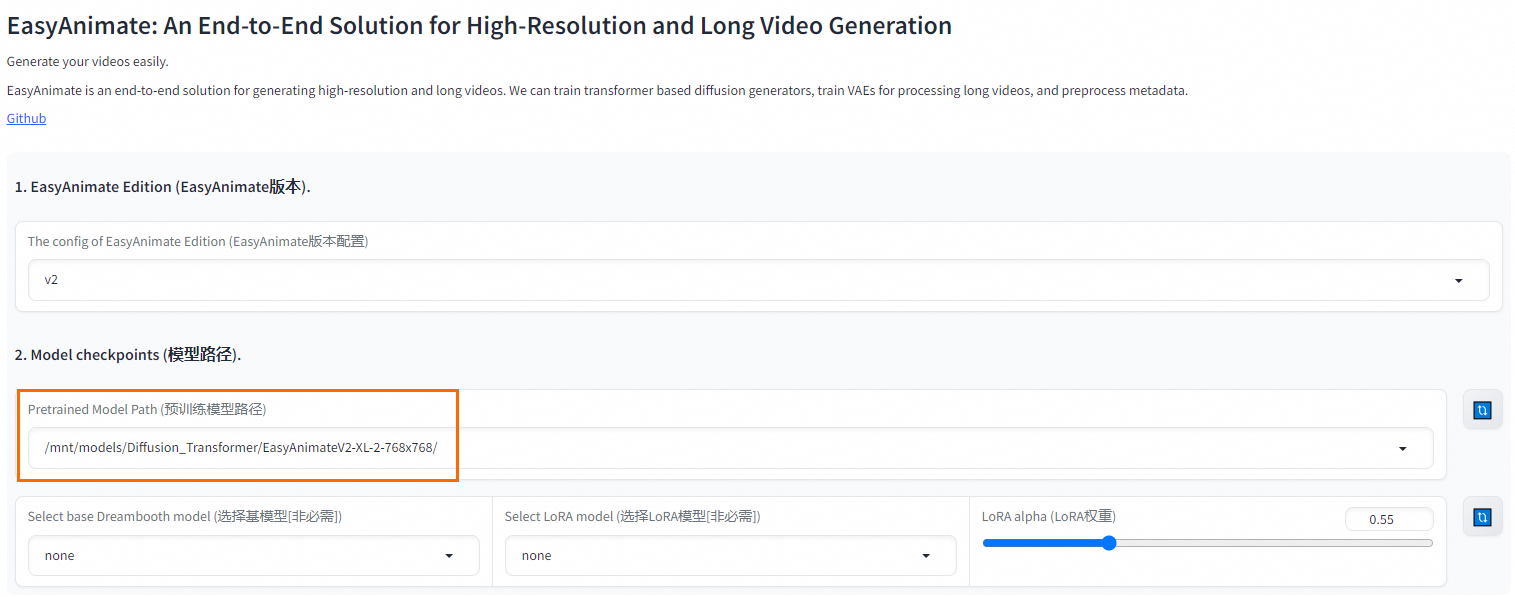
- 在WebUI界面选择预训练的模型路径,其它参数按需配置即可。
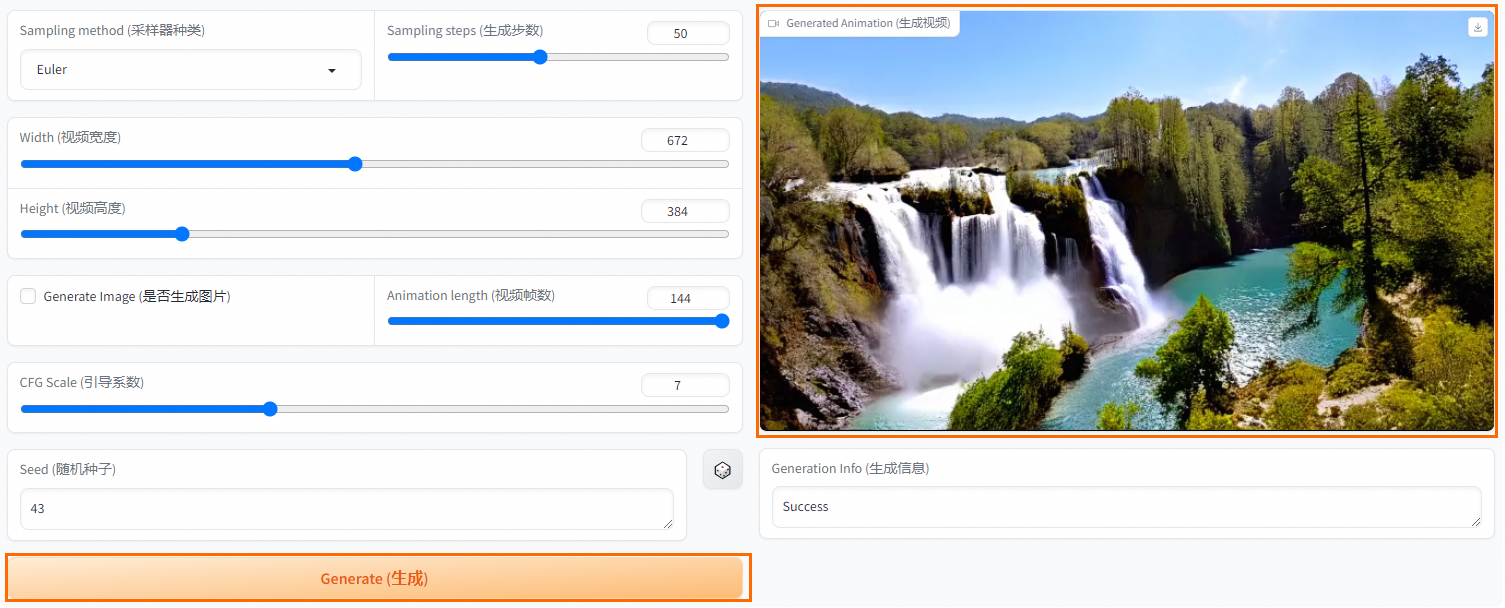
- 单击Generate(生成),等待一段时间后,即可在右侧查看或下载生成的视频。
API方式
- 在服务详情页面的资源详情区域,单击查看调用信息,获取调用服务所需的信息。
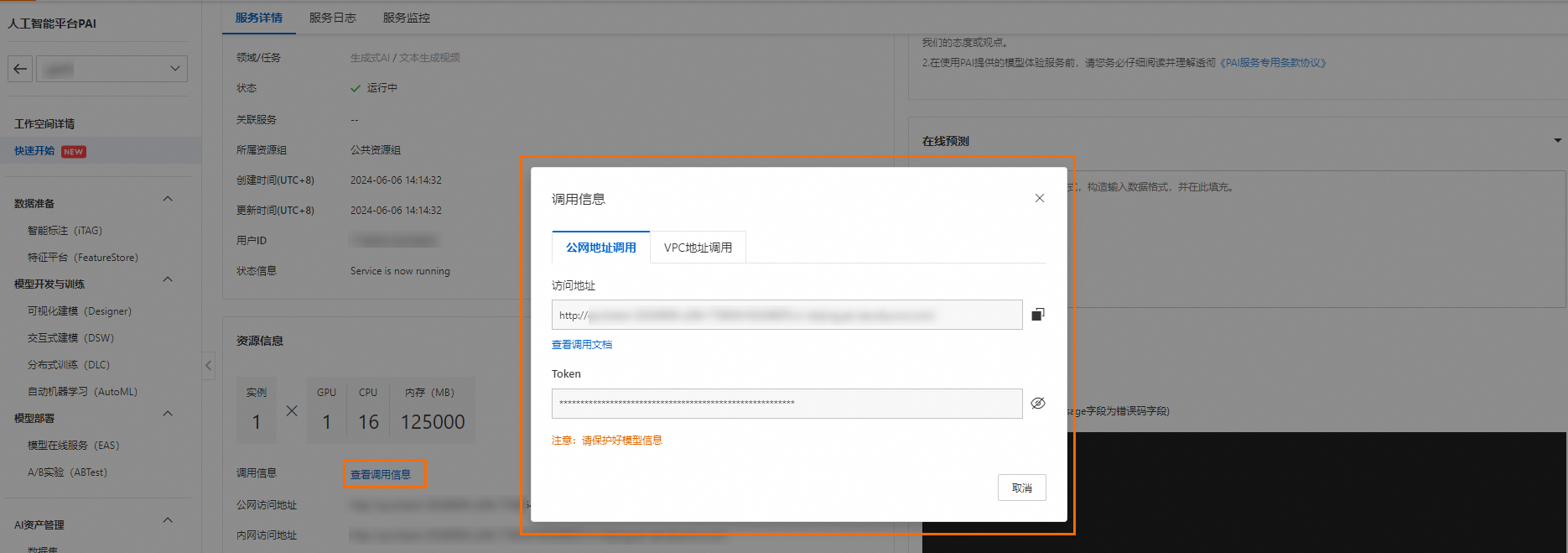
- 通过接口更新Transformer模型,可在DSW实例或本地Python环境中执行。
如果已经在WebUI中选择模型,则无需发送请求重复调用。如遇请求超时,请在EAS日志中确认模型已加载完毕。加载完成,日志中将提示Update diffusion transformer done。
Python请求示例如下。
import json
import requestsdef post_diffusion_transformer(diffusion_transformer_path, url='http://127.0.0.1:7860', token=None):datas = json.dumps({"diffusion_transformer_path": diffusion_transformer_path})head = {'Authorization': token}r = requests.post(f'{url}/easyanimate/update_diffusion_transformer', data=datas, headers=head, timeout=15000)data = r.content.decode('utf-8')return datadef post_update_edition(edition, url='http://0.0.0.0:7860',token=None):head = {'Authorization': token}datas = json.dumps({"edition": edition})r = requests.post(f'{url}/easyanimate/update_edition', data=datas, headers=head)data = r.content.decode('utf-8')return dataif __name__ == '__main__':url = '<eas-service-url>'token = '<eas-service-token>'# -------------------------- ## Step 1: update edition# -------------------------- #edition = "v2"outputs = post_update_edition(edition,url = url,token=token)print('Output update edition: ', outputs)# -------------------------- ## Step 2: update edition# -------------------------- ## 默认路径不可修改diffusion_transformer_path = "/mnt/models/Diffusion_Transformer/EasyAnimateV2-XL-2-512x512"outputs = post_diffusion_transformer(diffusion_transformer_path, url = url, token=token)print('Output update edition: ', outputs)
其中:
- :替换为步骤1中查询到的服务访问地址。
- :替换为步骤1中查询到的服务Token。
- 调用服务,生成视频或图片。
- 服务输入参数说明
| 参数名 | 说明 | 类型 | 默认值 |
|---|---|---|---|
| prompt_textbox | 用户输入的正向提示词。 | string | 必填。无默认值 |
| negative_prompt_textbox | 用户输入的负向提示词。 | string | “The video is not of a high quality, it has a low resolution, and the audio quality is not clear. Strange motion trajectory, a poor composition and deformed video, low resolution, duplicate and ugly, strange body structure, long and strange neck, bad teeth, bad eyes, bad limbs, bad hands, rotating camera, blurry camera, shaking camera. Deformation, low-resolution, blurry, ugly, distortion.” |
| sample_step_slider | 用户输入的步数。 | int | 30 |
| cfg_scale_slider | 引导系数。 | int | 6 |
| sampler_dropdown | 采样器类型。 | string | Eluer |
| 在 [Eluer, EluerA, DPM++, PNDM, DDIM] 中选择 | |||
| width_slider | 生成视频宽度。 | int | 672 |
| height_slider | 生成视频高度。 | int | 384 |
| length_slider | 生成视频帧数。 | int | 144 |
| is_image | 是否是图片。 | bool | FALSE |
| lora_alpha_slider | LoRA模型参数的权重。 | float | 0.55 |
| seed_textbox | 随机种子。 | int | 43 |
| lora_model_path | 额外的LoRA 模型路径。 | string | none |
| 若有,则会在请求时带上lora。在当次请求后移除。 | |||
| base_model_path | 需要更新的transformer模型路径。 | string | none |
| motion_module_path | 需要更新的motion_module模型路径。 | string | none |
- Python请求示例
服务返回base64_encoding,为base64结果。
您可以在**/mnt/workspace/demos/easyanimate/**目录中查看生成结果。
import base64
import json
import sys
import time
from datetime import datetime
from io import BytesIOimport cv2
import requests
import base64def post_infer(is_image, length_slider, url='http://127.0.0.1:7860',token=None):head = {'Authorization': token}datas = json.dumps({"base_model_path": "none","motion_module_path": "none","lora_model_path": "none", "lora_alpha_slider": 0.55, "prompt_textbox": "This video shows Mount saint helens, washington - the stunning scenery of a rocky mountains during golden hours - wide shot. A soaring drone footage captures the majestic beauty of a coastal cliff, its red and yellow stratified rock faces rich in color and against the vibrant turquoise of the sea.", "negative_prompt_textbox": "Strange motion trajectory, a poor composition and deformed video, worst quality, normal quality, low quality, low resolution, duplicate and ugly, strange body structure, long and strange neck, bad teeth, bad eyes, bad limbs, bad hands, rotating camera, blurry camera, shaking camera", "sampler_dropdown": "Euler", "sample_step_slider": 30, "width_slider": 672, "height_slider": 384, "is_image": is_image,"length_slider": length_slider,"cfg_scale_slider": 6,"seed_textbox": 43,})r = requests.post(f'{url}/easyanimate/infer_forward', data=datas, headers=head,timeout=1500)data = r.content.decode('utf-8')return dataif __name__ == '__main__':# initiate timenow_date = datetime.now()time_start = time.time() url = '<eas-service-url>'token = '<eas-service-token>'# -------------------------- ## Step 3: infer# -------------------------- #is_image = Falselength_slider = 27outputs = post_infer(is_image, length_slider, url = url, token=token)# Get decoded dataoutputs = json.loads(outputs)base64_encoding = outputs["base64_encoding"]decoded_data = base64.b64decode(base64_encoding)if is_image or length_slider == 1:file_path = "1.png"else:file_path = "1.mp4"with open(file_path, "wb") as file:file.write(decoded_data)# End of record timetime_end = time.time() time_sum = (time_end - time_start) % 60 print('# --------------------------------------------------------- #')print(f'# Total expenditure: {time_sum}s')print('# --------------------------------------------------------- #')
其中:
- < eas-service-url>:替换为步骤1中查询到的服务访问地址。
- < eas-service-token>:替换为步骤1中查询到的服务Token。
这篇关于基于EasyAnimate模型的视频生成最佳实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







