本文主要是介绍解决pyechart模块绘制地图无数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
解决pyechart模块绘制地图无数据
在绘制地图发现没有数据
错误原因:
传入数据中的省份名称不规范
例如:
data = [("北京", 99),("上海", 199),("湖南", 299),("台湾", 399),("广东", 499)
]
解决办法:
使用此函数,把传入地图的数据传入此函数进行处理(返回规范后的数据)
函数使用语法:data=norm_province(data)
data为存放地图的数据,传入nrom_province变量中返回处理后的数据
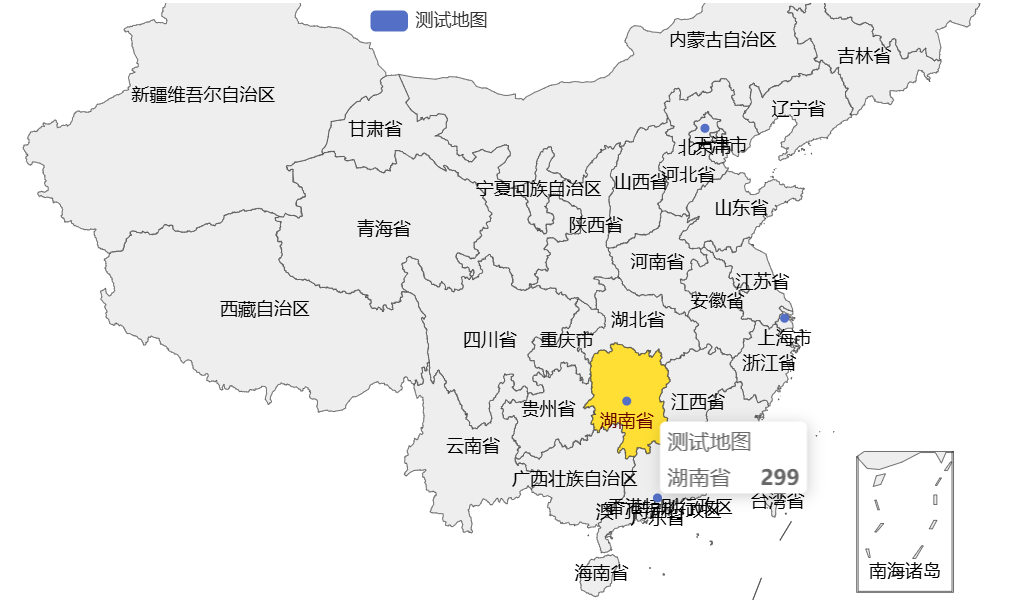
def norm_province(data):""":param data: 传入pyecharts地图模块中的data数据:return: 返回校正后的data数据"""province = ("新疆维吾尔自治区", "西藏自治区", "宁夏回族自治区", "广西壮族自治区", "内蒙古自治区", "澳门特别行政区","香港特别行政区", "重庆市", "北京市", "天津市", "上海市", "甘肃省", "青海省", "四川省", "云南省","贵州省", "陕西省", "湖南省", "湖北省", "河南省", "山西省", "河北省", "辽宁省", "吉林省", "黑龙江省","山东省", "江苏省", "安徽省", "浙江省", "江西省", "福建省", "台湾省", "广东省", "海南省")norm_data = []for x in data:x=list(x)for area in province:if x[0] in area:x[0]=areax=tuple(x)norm_data.append(x)return norm_data成功截图:
这篇关于解决pyechart模块绘制地图无数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





