本文主要是介绍JCR一区 | Matlab实现GAF-PCNN、GASF-CNN、GADF-CNN的多特征输入数据分类预测/故障诊断,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
JJCR一区 | Matlab实现GAF-PCNN、GASF-CNN、GADF-CNN的多特征输入数据分类预测/故障诊断
目录
- JJCR一区 | Matlab实现GAF-PCNN、GASF-CNN、GADF-CNN的多特征输入数据分类预测/故障诊断
- 分类效果
- 格拉姆矩阵图
- GAF-PCNN
- GASF-CNN
- GADF-CNN
- 基本介绍
- 程序设计
- 参考资料
分类效果
格拉姆矩阵图

GAF-PCNN








GASF-CNN






GADF-CNN






基本介绍
1.Matlab实现GAF-PCNN、GASF-CNN、GADF-CNN的多特征输入数据分类预测/故障诊断,三个模型对比,运行环境matlab2023b;
2.先运行格拉姆矩阵变换进行数据转换,然后运行分别GAF_PCNN.mGADF_CNN.m,GASF_CNN.m完成多特征输入数据分类预测/故障诊断;
GADF_CNN.m,是只用到了格拉姆矩阵的GADF矩阵,将GADF矩阵送入CNN进行故障诊断。
GASF_CNN.m,是只用到了格拉姆矩阵的GASF矩阵,将GASF矩阵送入CNN进行故障诊断。
GAF_PCNN.m,是将GASF 图与GADF 图同时送入两条并行CNN 中,经过卷积-池化后,两条CNN网络各输出一组一维向量;然后,将所输出两组一维向量进行拼接融合;通过全连接层后,最终将融合特征送入到Softmax 分类器中。
参考文献

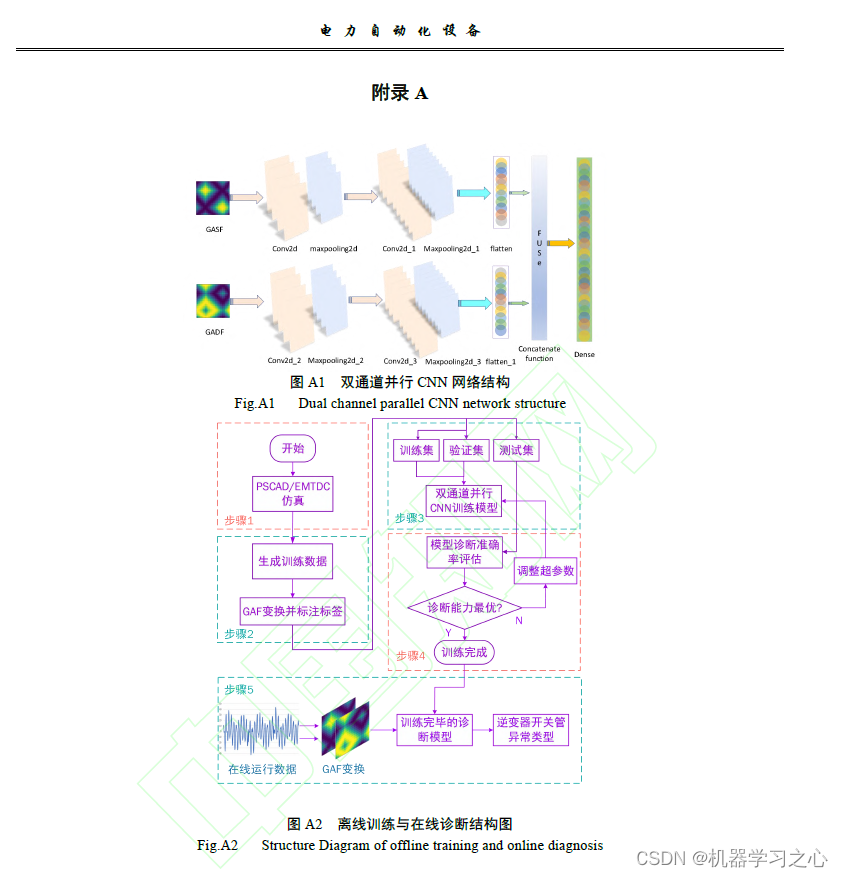
- PCNN结构

- CNN结构

程序设计
- 完整程序和数据获取方式私信博主回复Matlab实现GAF-PCNN、GASF-CNN、GADF-CNN的多特征输入数据分类预测/故障诊断。
fullyConnectedLayer(classnum,'Name','fc12')softmaxLayer('Name','softmax')classificationLayer('Name','classOutput')];lgraph = layerGraph(layers1);layers2 = [imageInputLayer([size(input2,1) size(input2,2)],'Name','vinput') flattenLayer(Name='flatten2')bilstmLayer(15,'Outputmode','last','name','bilstm') dropoutLayer(0.1) % Dropout层,以概率为0.2丢弃输入reluLayer('Name','relu_2')selfAttentionLayer(2,2,"Name","mutilhead-attention") %Attention机制fullyConnectedLayer(10,'Name','fc21')];
lgraph = addLayers(lgraph,layers2);
lgraph = connectLayers(lgraph,'fc21','add/in2');plot(lgraph)%% Set the hyper parameters for unet training
options = trainingOptions('adam', ... % 优化算法Adam'MaxEpochs', 1000, ... % 最大训练次数'GradientThreshold', 1, ... % 梯度阈值'InitialLearnRate', 0.001, ... % 初始学习率'LearnRateSchedule', 'piecewise', ... % 学习率调整'LearnRateDropPeriod',700, ... % 训练100次后开始调整学习率'LearnRateDropFactor',0.01, ... % 学习率调整因子'L2Regularization', 0.001, ... % 正则化参数'ExecutionEnvironment', 'cpu',... % 训练环境'Verbose', 1, ... % 关闭优化过程'Plots', 'none'); % 画出曲线
%Code introduction
if nargin<2error('You have to supply all required input paremeters, which are ActualLabel, PredictedLabel')
end
if nargin < 3isPlot = true;
end%plotting the widest polygon
A1=1;
A2=1;
A3=1;
A4=1;
A5=1;
A6=1;a=[-A1 -A2/2 A3/2 A4 A5/2 -A6/2 -A1];
b=[0 -(A2*sqrt(3))/2 -(A3*sqrt(3))/2 0 (A5*sqrt(3))/2 (A6*sqrt(3))/2 0];if isPlotfigure plot(a, b, '--bo','LineWidth',1.3)axis([-1.5 1.5 -1.5 1.5]);set(gca,'FontName','Times New Roman','FontSize',12);hold on%grid
end% Calculating the True positive (TP), False Negative (FN), False Positive...
% (FP),True Negative (TN), Classification Accuracy (CA), Sensitivity (SE), Specificity (SP),...
% Kappa (K) and F measure (F_M) metrics
PositiveClass=max(ActualLabel);
NegativeClass=min(ActualLabel);
cp=classperf(ActualLabel,PredictedLabel,'Positive',PositiveClass,'Negative',NegativeClass);CM=cp.DiagnosticTable;TP=CM(1,1);FN=CM(2,1);FP=CM(1,2);TN=CM(2,2);CA=cp.CorrectRate;SE=cp.Sensitivity; %TP/(TP+FN)SP=cp.Specificity; %TN/(TN+FP)Pr=TP/(TP+FP);Re=TP/(TP+FN);F_M=2*Pr*Re/(Pr+Re);FPR=FP/(TN+FP);TPR=TP/(TP+FN);K=TP/(TP+FP+FN);[X1,Y1,T1,AUC] = perfcurve(ActualLabel,PredictedLabel,PositiveClass); %ActualLabel(1) means that the first class is assigned as positive class%plotting the calculated CA, SE, SP, AUC, K and F_M on polygon
x=[-CA -SE/2 SP/2 AUC K/2 -F_M/2 -CA];
y=[0 -(SE*sqrt(3))/2 -(SP*sqrt(3))/2 0 (K*sqrt(3))/2 (F_M*sqrt(3))/2 0];if isPlotplot(x, y, '-ko','LineWidth',1)set(gca,'FontName','Times New Roman','FontSize',12);
% shadowFill(x,y,pi/4,80)fill(x, y,[0.8706 0.9216 0.9804])
end%calculating the PAM value
% Get the number of vertices
n = length(x);
% Initialize the area
p_area = 0;
% Apply the formula
for i = 1 : n-1p_area = p_area + (x(i) + x(i+1)) * (y(i) - y(i+1));
end
p_area = abs(p_area)/2;%Normalization of the polygon area to one.
PA=p_area/2.59807;if isPlot%Plotting the Polygonplot(0,0,'r+')plot([0 -A1],[0 0] ,'--ko')text(-A1-0.3, 0,'CA','FontWeight','bold','FontName','Times New Roman')plot([0 -A2/2],[0 -(A2*sqrt(3))/2] ,'--ko')text(-0.59,-1.05,'SE','FontWeight','bold','FontName','Times New Roman')plot([0 A3/2],[0 -(A3*sqrt(3))/2] ,'--ko')text(0.5, -1.05,'SP','FontWeight','bold','FontName','Times New Roman')plot([0 A4],[0 0] ,'--ko')text(A4+0.08, 0,'AUC','FontWeight','bold','FontName','Times New Roman')plot([0 A5/2],[0 (A5*sqrt(3))/2] ,'--ko')text(0.5, 1.05,'J','FontWeight','bold','FontName','Times New Roman')daspect([1 1 1])
end
Metrics.PA=PA;
Metrics.CA=CA;
Metrics.SE=SE;
Metrics.SP=SP;
Metrics.AUC=AUC;
Metrics.K=K;
Metrics.F_M=F_M;printVar(:,1)=categories;
printVar(:,2)={PA, CA, SE, SP, AUC, K, F_M};
disp('预测结果打印:')
for i=1:length(categories)fprintf('%23s: %.2f \n', printVar{i,1}, printVar{i,2})
end
参考资料
[1] https://blog.csdn.net/kjm13182345320/category_11799242.html?spm=1001.2014.3001.5482
[2] https://blog.csdn.net/kjm13182345320/article/details/124571691
这篇关于JCR一区 | Matlab实现GAF-PCNN、GASF-CNN、GADF-CNN的多特征输入数据分类预测/故障诊断的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





