本文主要是介绍fastsam-pytorch基于YOLACT方法的实例分割分支的目标检测器模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
FastSAM
论文
Fast Segment Anything
模型结构
以yolov8-seg的instance segmentation为基础,检测时集成instance segmentation分支,主要分为两步全实例分割(all instance Segmentation)和基于prompt的mask输出(Prompt-guided Selection),仅使用了2%的SA-1B数据集便得到了差不多的精度但快几十倍的速度。
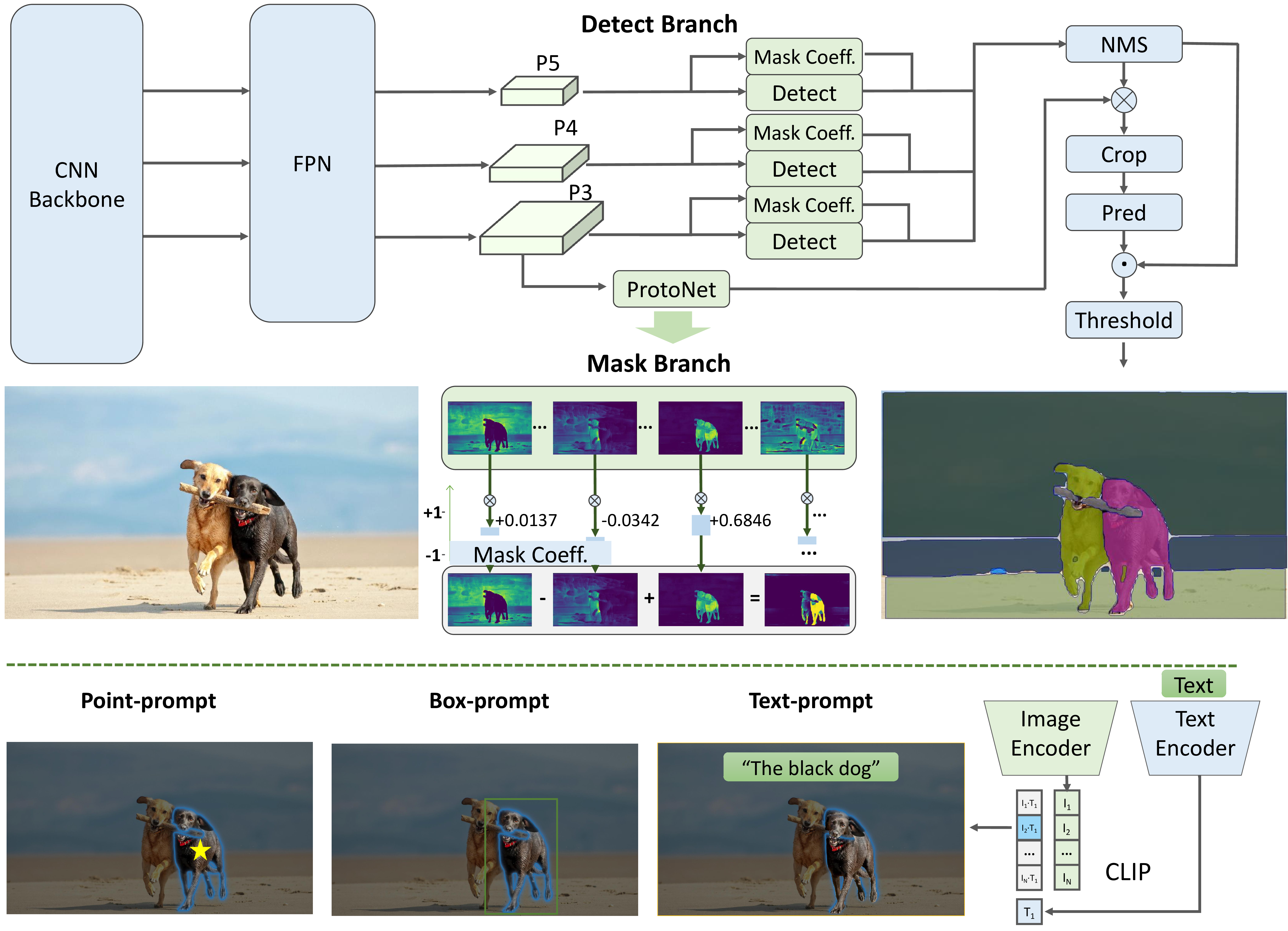
算法原理
该算法采用yolov8-seg的instance segmentation为基础,检测时集成instance segmentation分支实现。
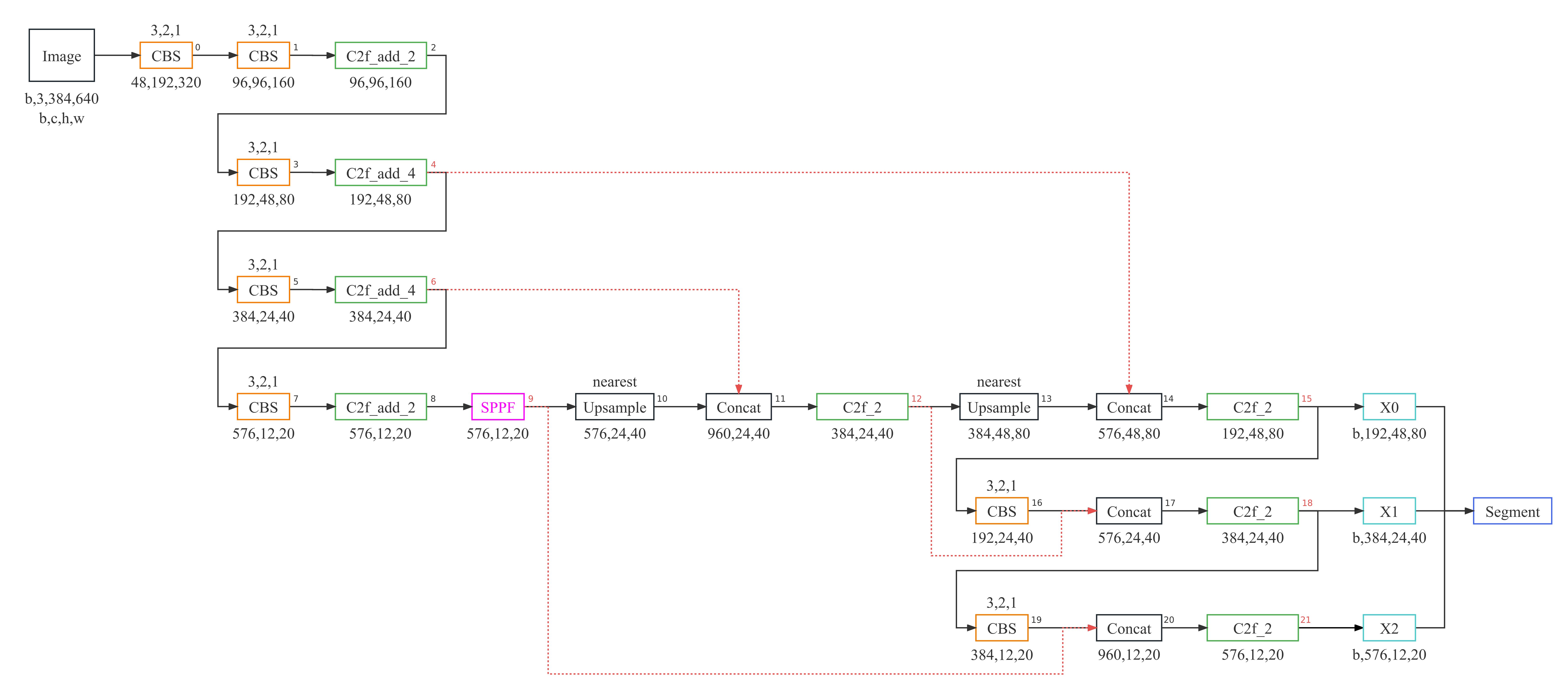
环境配置
Docker (方法一)
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:1.13.1-centos7.6-dtk23.10-py38
# <your IMAGE ID>为以上拉取的docker的镜像ID替换
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal:/opt/hyhal --shm-size=32G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
cd /path/workspace/
pip3 install -r requirements.txt
pip3 install git+https://github.com/openai/CLIP.git
Dockerfile (方法二)
cd ./docker
docker build --no-cache -t fastsam_pytorch:last .
# <your IMAGE ID>为以上拉取的docker的镜像ID替换
docker run -it -v /path/your_code_data/:/path/your_code_data/ -v /opt/hyhal:/opt/hyhal --shm-size=32G --privileged=true --device=/dev/kfd --device=/dev/dri/ --group-add video --name docker_name imageID bash
Anaconda (方法三)
1、关于本项目DCU显卡所需的特殊深度学习库可从光合开发者社区下载安装: https://developer.hpccube.com/tool/
DTK软件栈:dtk23.10
python:python3.8
pytorch:1.13.1
torchvision:0.14.1
Tips:以上dtk软件栈、python、pytorch等DCU相关工具版本需要严格一一对应
2、其他非特殊库直接按照requirements.txt安装
pip3 install -r requirements.txt
pip3 install git+https://github.com/openai/CLIP.git
数据集
训练数据集为SA-1B的2%左右的数据量,由于数据量过大,且官方并未放出2%的具体数据集,以下数据集为SA-1B原始数据集,训练仅供参考。
训练数据
推理
单卡推理
权重下载地址
HIP_VISIBLE_DEVICES=1 python Inference.py --model_path ./weights/FastSAM_X.pt --img_path ./images/dogs.jpg
result
此处以Fast-SAM-x模型进行推理测试
| 输入 | 输出 |
|---|---|
|
|
|


精度
Instance Segmentation On COCO 2017
| method | AP | APS | APM | APL |
|---|---|---|---|---|
| ViTDet-H | .510 | .320 | .543 | .689 |
| SAM | .465 | .308 | .510 | .617 |
| FastSAM | .379 | .239 | .434 | .500 |
应用场景
算法分类
图像分割
热点应用行业
制造,广媒,能源,医疗,家居,教育
源码仓库及问题反馈
ModelZoo / FastSAM_pytorch · GitLab
参考资料
FastSAM基于YOLACT方法的实例分割分支的目标检测器YOLOv8-seg,通过仅在SA-1B数据集的2%(1/50)上直接训练该CNN检测器,它实现了与SAM相当的性能。
这篇关于fastsam-pytorch基于YOLACT方法的实例分割分支的目标检测器模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





