本文主要是介绍介绍并改造一个作用于Anki笔记浏览器的插件,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在Anki的笔记浏览器窗口中,作为主体部分的表格在对获取到的笔记进行排序时,最多只能有一个排序字段,在设定笔记的排序字段后,没法将表格中的笔记按其他字段进行排序。要满足这个需求,可以使用Advanced Browser插件(安装ID:874215009)。这个插件在浏览器窗口的右键文菜单中添加了额外的菜单项,从而支持在浏览器窗口的表格控件上添加以笔记中非排序字段作为列标题的列,如下图:
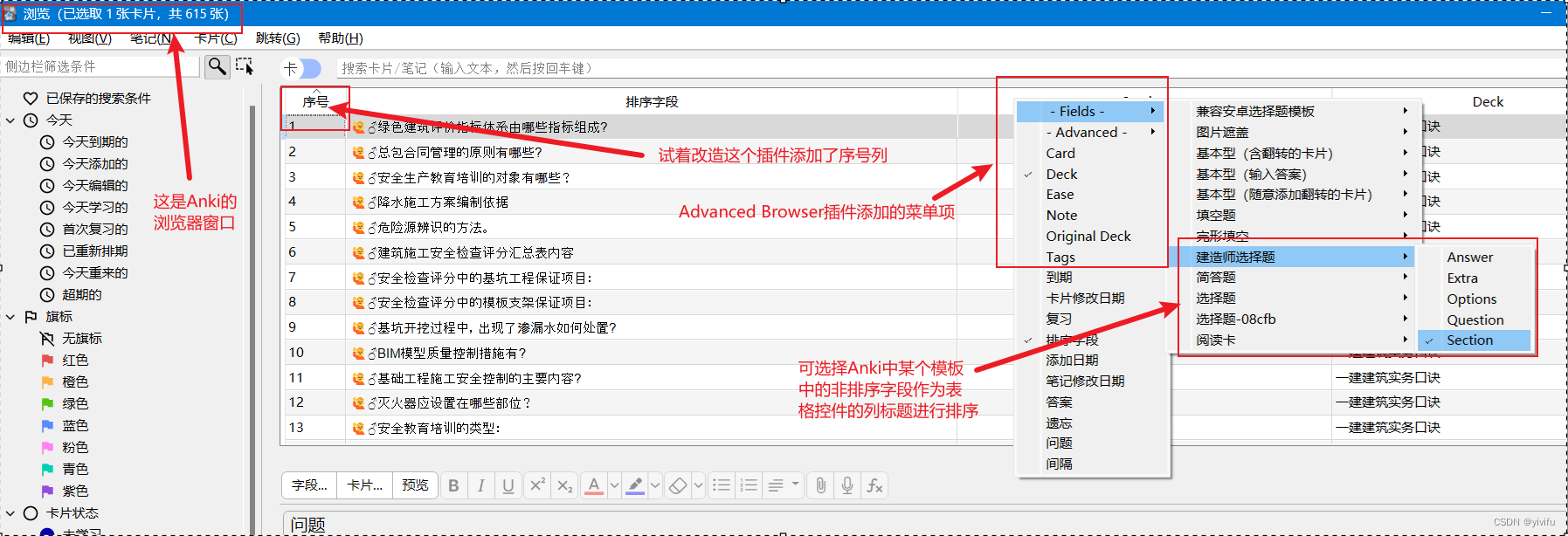
在使用这个插件的时候,发现它没有提供在表格控件中增加一个序号列并填充序号的功能。作为一个强迫症患者,实在想增加这个列,于是对这个插件进行了一番改造。
必须说有关Anki插件开发的文档实在太少了,自己写插件找Anki中相关对象的文档都要费很多时间还不一定能找到,我甚至求助AI,结果被忽悠了一轮,它煞有介事给出的回答完全没用——所以AI取代程序员的可能暂时应该不大。因此,稍微分析下这个插件的代码并进行改造未尝不是探索Anki插件编程的一个好方法。要说明的是,我对这个插件改造后增加的功能实际上没有什么作用,因为表格控件中有多少条笔记以及选择了多少条笔记在窗口标题处都有了,我添加的这个序号并不是笔记模型中的字段,所以意义不大,而且改造后其实动作也不完全符合我的预期,只有等以后有时间了再深入探索,这里权且算个阶段性笔记。
Advanced Browser插件添加的子菜单组“-Advanced-”添加了一序列菜单项,每个菜单项可以在表格控件中添加一列。因此,很容易想到改写这个文件的源码来添加自己的“序号”菜单项。要让它生成序号,需要在表格控件显示数据时从1开始计数并显示在笔记所在行。所以,需要保存一个变量用于保存当前的计数。此外,这个计数在表格控件中的笔记条目发生变化时还应该恢复到初始值,这就需要挂一个处理表格控件中显示条目变化的钩子。以下就是我对插件源文件所增添的内容:
# 给类添加构造函数,保存一个用于计数的变量,放在类AdvancedFields中def __init__(self):self.sn = 0# 参照源文件中其他菜单项的写法,增加一个序号菜单项,放在类AdvancedFields中# Sequential numberdef cCout(c, n, t):self.sn += 1return self.sncc = advBrowser.newCustomColumn(type='Count',name='序号',onData=cCout)self.customColumns.append(cc)# ------------------------------- ## 增加一个回复计数变量的钩子函数,放在类AdvancedFields中def initSn(self, browser):self.sn = 0# 最后,增加一个钩子。当然,要先在导入包的地方加上from aqt import gui_hooks# 添加在原文件最后gui_hooks.browser_did_search.append(af.initSn)从最上面的截图可以看到确实添加了一个序号列。但是这个没有排序功能,里面的序号数字经常乱掉,乱掉后只有在光标定位在表格控件第一行且重新筛选笔记时才会重新从1往下顺序排列。这应该是没有钩全引起表格控件重新显示的钩子。不过用半天时间也算对Anki插件编程有了个大致了解了,暂时就这样了。
这篇关于介绍并改造一个作用于Anki笔记浏览器的插件的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



