本文主要是介绍基于相关向量机RVM的回归预测算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
基于相关向量机RVM的回归预测算法
文章目录
- 基于相关向量机RVM的回归预测算法
- 1.RVM原理
- 2.算法实验与结果
- 3.参考文献:
- 4.MATLAB代码
摘要:本文主要介绍相关向量机RVM的基本原理,以及在预测问题中的应用。
1.RVM原理
RVM算法是一种基于贝叶斯框架的机器学习模型 ,通过最大化边际似然得到相关向量和权重。
设 { x } u = 1 N \{x\}_{u=1}^N {x}u=1N和 { t } u = 1 N \{t\}_{u=1}^N {t}u=1N分别是输入向量和输出向量,目标 t t t可采用如式(1)所示的回归模型获得:
t = y ( x ) + ξ n (1) t =y(x)+\xi_n \tag{1} t=y(x)+ξn(1)
式中: ξ n \xi_n ξn为零均值、方差 σ 2 σ^2 σ2的噪声, y ( x ) y(x) y(x) 定义为:
y ( x ) = ∑ u = 1 N w u K ( x , x u ) + w 0 (2) y(x)=\sum_{u=1}^Nw_uK(x,x_u)+w_0 \tag{2} y(x)=u=1∑NwuK(x,xu)+w0(2)
式中: K ( x , x u ) K(x,x_u) K(x,xu) 是核函数, w u w_u wu 是权重向量, w 0 w_0 w0是偏差。设 t t t是独立的,其概率定义为:
p ( t ∣ w , σ 2 ) = ( 2 π σ 2 ) − N / 2 e x p ( − ∣ ∣ t − w φ ∣ ∣ 2 2 σ 2 ) (3) p(t|w,\sigma^2)=(2\pi\sigma^2)^{-N/2}exp(-\frac{||t-w\varphi||^2}{2\sigma^2})\tag{3} p(t∣w,σ2)=(2πσ2)−N/2exp(−2σ2∣∣t−wφ∣∣2)(3)
式中: t = ( t 1 , t 2 , . . . , t N ) T , w = ( w 0 , w 1 , . . . , w n ) T t=(t_1,t_2,...,t_N)^T,w=(w_0,w_1,...,w_n)^T t=(t1,t2,...,tN)T,w=(w0,w1,...,wn)T, φ \varphi φ是 N ( N + 1 ) N(N+1) N(N+1)的矩阵。
式(3)中的 w w w 和 σ σ σ最大似然估计会导致过拟合,为约束参数,定义一个零均值高斯先验概率分布:
p ( w ∣ α ) = ∏ u = 0 N N ( w u ∣ 0 , α u − 1 ) (4) p(w|\alpha)=\prod_{u=0}^NN(w_u|0,\alpha_u^{-1})\tag{4} p(w∣α)=u=0∏NN(wu∣0,αu−1)(4)
式中: α α α 是 N + 1 N +1 N+1 维的超参数向量。
依据贝叶斯公式,未知参数的后验概率为:
p ( w , α , σ 2 ∣ t ) = p ( w ∣ α , σ 2 , t ) p ( α , σ 2 ∣ t ) (5) p(w,\alpha,\sigma^2|t)=p(w|\alpha,\sigma^2,t)p(\alpha,\sigma^2|t)\tag{5} p(w,α,σ2∣t)=p(w∣α,σ2,t)p(α,σ2∣t)(5)
后验分布的权重被描述为:
p ( w ∣ t , α , σ 2 ) = ( 2 π ) − ( N + 1 ) / 2 ∣ Σ ∣ − 1 / N e x p ( − 1 2 ( w − u ) T Σ − 1 ( w − u ) ) (6) p(w|t,\alpha,\sigma^2)=(2\pi)^{-(N+1)/2}|\Sigma|^{-1/N}exp(-\frac{1}{2}(w-u)^T\Sigma ^{-1}(w-u))\tag{6} p(w∣t,α,σ2)=(2π)−(N+1)/2∣Σ∣−1/Nexp(−21(w−u)TΣ−1(w−u))(6)
式中:后验均值 u = σ − 2 Σ φ T t u=\sigma^{-2}\Sigma\varphi^Tt u=σ−2ΣφTt,协方差 Σ = ( σ − 2 φ T φ + A ) − 1 \Sigma=(\sigma^{-2}\varphi^T\varphi+A)^{-1} Σ=(σ−2φTφ+A)−1, A = d i a g ( α 0 , α 1 , . . . , α N ) A=diag(\alpha_0,\alpha_1,...,\alpha_N) A=diag(α0,α1,...,αN)。
为了实现统一的超参数,做出如下定义:
p ( t ∣ α , σ 2 ) = ∫ p ( t ∣ w , σ 2 ) p ( w , α ) d w = ( 2 π ) − N / 2 ∣ σ 2 I + φ A − 1 φ T ∣ e x p ( − 1 2 t T ( σ 2 I + φ A − 1 φ T ) − 1 t ) (7) p(t|\alpha,\sigma^2)=\int p(t|w,\sigma^2)p(w,\alpha)dw =(2\pi)^{-N/2}|\sigma^2I+\varphi A^{-1}\varphi^T|exp(-\frac{1}{2}t^T(\sigma^2I + \varphi A^{-1}\varphi^T)^{-1}t)\tag{7} p(t∣α,σ2)=∫p(t∣w,σ2)p(w,α)dw=(2π)−N/2∣σ2I+φA−1φT∣exp(−21tT(σ2I+φA−1φT)−1t)(7)
高斯径向基函数具有较强的非线性处理能力,被用作核函数,其定义如下:
K ( x , x u ) = e x p ( − ( x − x u ) 2 2 γ 2 ) (7) K(x,x_u)=exp(-\frac{(x-x_u)^2}{2\gamma^2})\tag{7} K(x,xu)=exp(−2γ2(x−xu)2)(7)
式中: γ γ γ 为宽度因子,对模型的精度有极大的影响,需要预先设定。
2.算法实验与结果
本文算法数据数量一共为250组数据。其中前200组数据用训练,后50组数据用作测试数据。数据的输入维度为2维,输出维度为1维。
| 数据类别 | 数据量 |
|---|---|
| 训练数据 | 200 |
| 测试数据 | 50 |
设置RVM的核函数为高斯径向基函数,核宽度为3。得到的结果如下图所示:
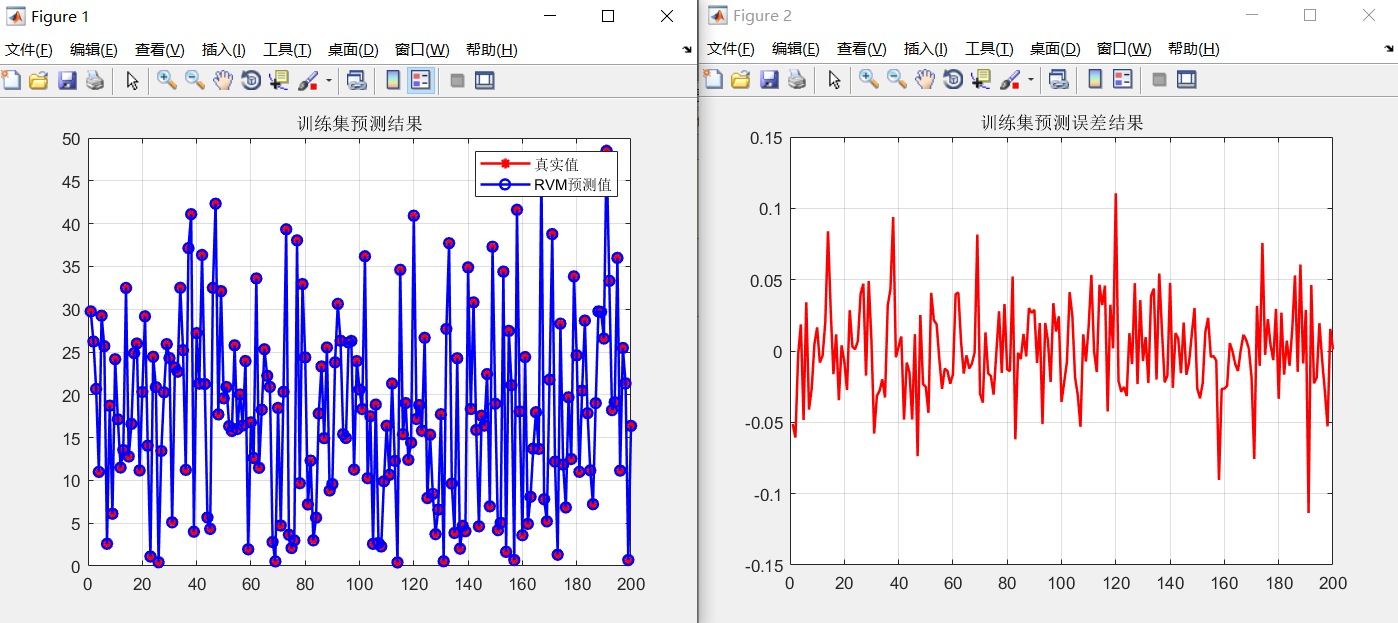
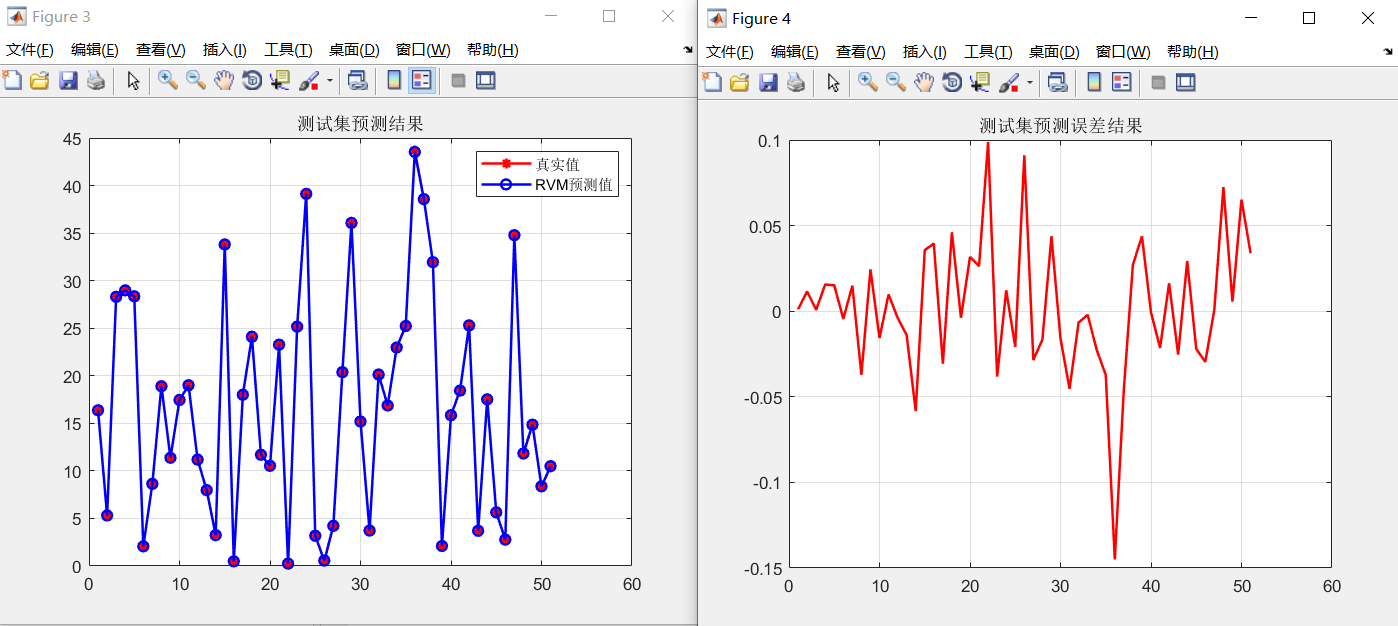
训练集MSE:0.0010558
测试集MSE:0.0016036
从结果曲线,和训练集MSE以及测试集MSE来看,RVM在回归预测问题上表现了较好的结果。
3.参考文献:
[1] TIPPPING M E. Sparse Bayesian learning and the relevance vector machine[J]. The journal of machine learning research,2001,1: 211-244.
4.MATLAB代码

这篇关于基于相关向量机RVM的回归预测算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






