本文主要是介绍作者推荐 | 探索分析从起源到现今的巅峰之旅(MySQL存储模型),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
探索分析从起源到现今的巅峰之旅
- 背景介绍
- MySQL内部组织与结构
- MySQL的数据层次和关系
- InnoDB的数据存储模型
- 数据记录的基本单元 — 行
- 页目录(Page Directory)
- 文件头(File Header)决定页面间的关联方式
- 数据页头(Page Header)的页面层级的关键
- 索引的优化路径
- 索引检索能力实现
- 先定位页目录+顺序搜索
- 聚集索引性能搜索
- 非聚集索引实现搜索
- 二级索引
- 联合索引
- 总结介绍
背景介绍
在深入研究MySQL的存储架构之后,本文详细解读了索引设计的历史演变和当前趋势,着重突出了索引在业务系统中的不可或缺性和其重要性。然而,值得注意的是,高并发场景下的数据库性能调优是一个多维度的挑战,索引优化只是其中的一环。本文的核心目标在于阐明索引优化的核心原理与策略,旨在为数据库性能调优的全方位实践提供坚实的理论支撑。
MySQL内部组织与结构
从InnoDB存储引擎的核心设计理念出发,我们对MySQL的数据存储管理机制进行了详尽的探究,从而揭示了其高效结构和内部工作机制的奥秘。
通过观察上图,不难发现记录头部分不仅包含了行号(堆中的位置信息),还含有一个指向下一条记录的标识next_record。正是这个标识,使得我们能够以单向链表的形式将各条记录相互连接起来。这种结构特性意味着,在记录链中搜索特定记录时,我们只能按照顺序逐一遍历,从而限制了数据链的长度不会过长。
考虑到InnoDB引擎每一页默认大小为16K,并考虑到行溢出等因素,单页最多可以容纳7992条记录。面对如此大量的记录,我们是否仍需顺序遍历呢?我们来看下面的下面的MYSQL数据低层的结构以及数据模型关系。
MySQL的数据层次和关系
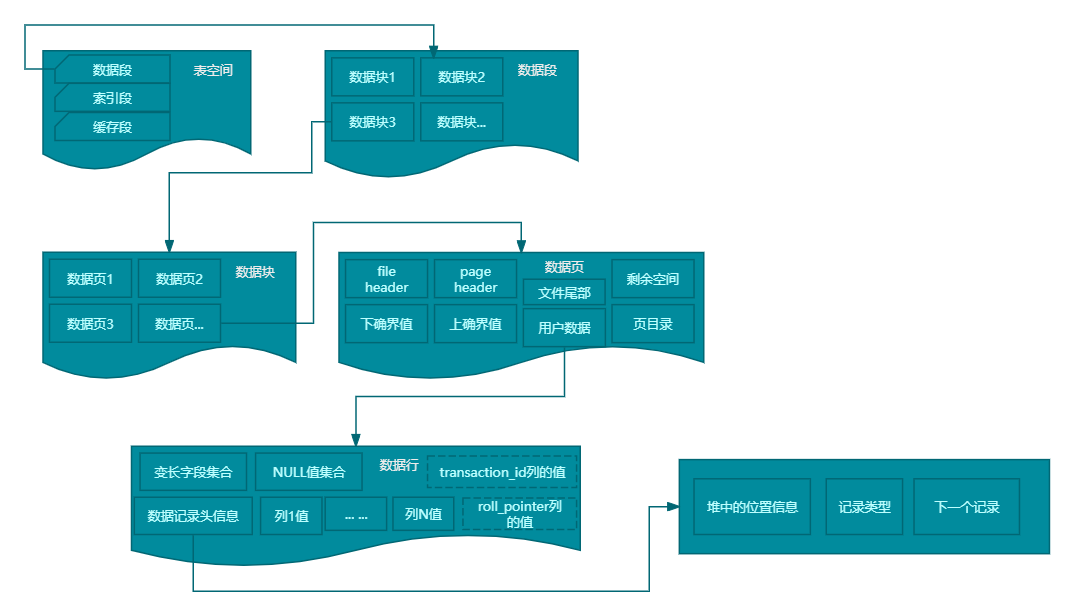
数据的逻辑架构呈现出一种多层次的结构,这些层次从最基本的行数据开始,逐步向上扩展至页、区块,并最终汇集到更为宏观的段和表空间,形成了一套完整的数据组织体系。如下图所示:

这些层级的划分(即段和区块)并非随机设置,而是经过精心设计,旨在最大化资源利用效率,特别是为了确保与操作系统的I/O操作高效协同(如,磁盘与内存间的数据传输常基于区块单位)。通过这种逻辑上的精心布局,我们得以显著提升数据的读写效率。
InnoDB的数据存储模型
在InnoDB存储引擎中,表是按照索引组织的(即数据即索引,索引即数据),这些数据和索引结构都维护在B+树上。具体来说,数据段对应的是B+树的叶子节点,而索引段则对应于非叶子节点。
页(Page)是与磁盘交互的最小单位。从页到行的定位,以及页如何聚合形成区块、段,并最终构成表空间,这些过程都体现了InnoDB对数据管理的精细控制。
数据记录的基本单元 — 行
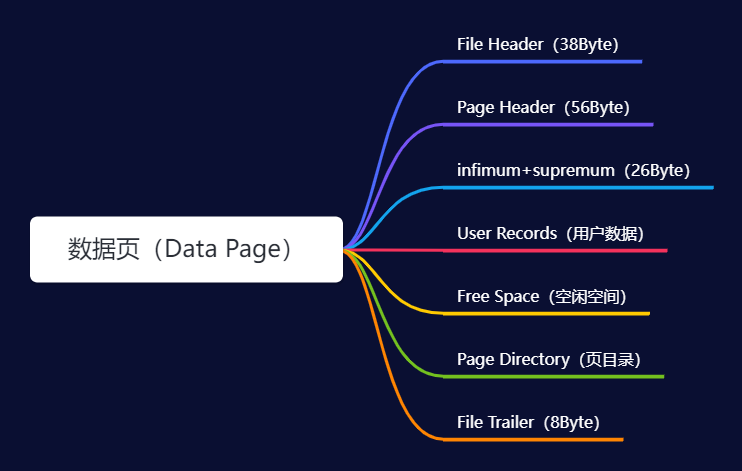
在数据库与磁盘的交互中,页(page)扮演着至关重要的角色,作为最小的数据交换单位。其不仅包含实际的数据内容,还涵盖其他类型的页,如索引目录页,这些特殊页旨在提高查询效率。接下来,我们将聚焦几个核心字段参数进行详述:
页目录(Page Directory)
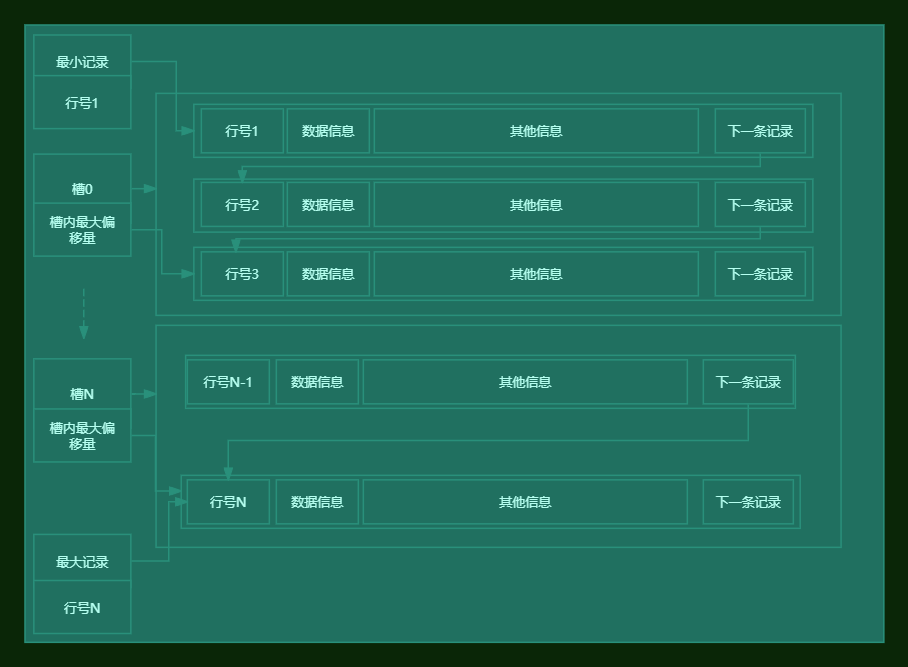
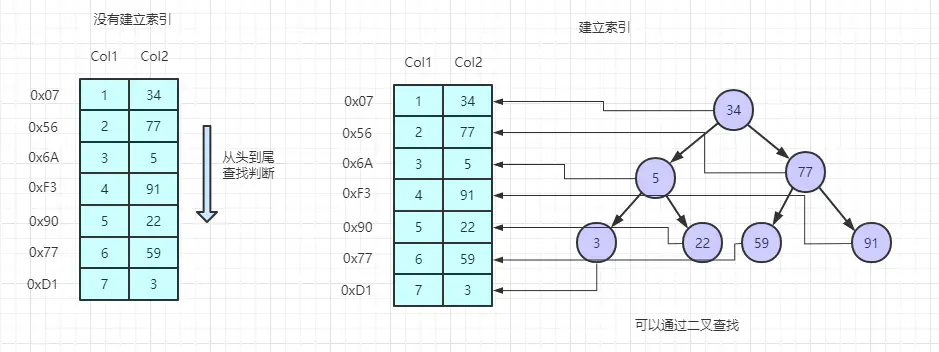
页目录(Page Directory)对于优化页内记录项的查询速度具有至关重要的影响。
为了提高查询速度,页目录存储了当前页的数据目录(槽位),其中包含了最小和最大记录的标识,以及分组数据链中最大记录的偏移量。这一设计使得通过二分查找法能够迅速定位数据,无需从最小值开始逐一遍历,如图所示:
文件头(File Header)决定页面间的关联方式
File Header记录数据页的一些基本信息,涵盖了诸如当前页码、前一页和后一页的链接、页面类型以及所属的表空间等核心数据。
可以凭借页码迅速定位到特定的数据页,而借助前后页的链接,这些页面能够像双向链表一样紧密相连。此外,通过查看页面类型,我们可以轻松区分该页是索引页还是数据页,从而实现高效的数据检索和管理。
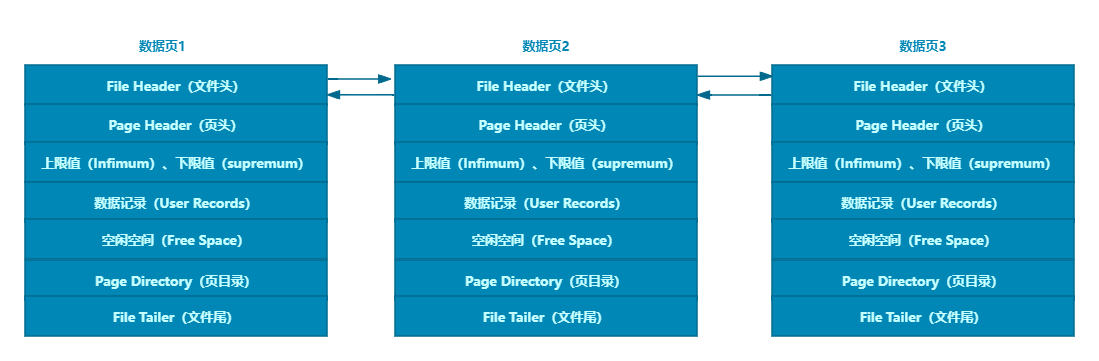
根据上图所示,我们可以清晰地看到,File Header字段在页与页之间的关联中起到了至关重要的作用。通过这些属性,页面能够轻松地进行相互连接,从而实现便捷的数据访问与操作。File Header的设计使得页面关联变得简单高效,大大提升了数据处理的灵活性和效率。
数据页头(Page Header)的页面层级的关键
Page Header,作为索引页所独有的结构,稳定占用56个字节的空间,其中详细记载了与索引页内记录状态息息相关的信息。
| 名称 | 字节数 | 描述 |
|---|---|---|
| PAGE_N_DlR_SLOTS | 2字节 | 页目录中的槽数量 |
| PAGE_HEAP_TOP | 2字节 | 未使用的空间最小地址,User Records和Free Space分界点 |
| PAGE_N_HEAP | 2字节 | 本页中的记录的数量(包括虚拟记录和删除记录) |
| PAGE_FREE | 2字节 | 第一个删除的记录地址,后续删除的记录会形成链表 |
| PAGE_GARBAGE | 2字节 | 已删除记录占用的字节数 |
| PAGE_LAST_INSERT | 2字节 | 最后插入记录的位置 |
| PAGE_DIRECTION | 2字节 | 记录插入的方向 |
| PAGE_N_DIRECTION | 2字节 | 同一个方向连续插入的记录数量 |
| PAGE_N_RECS | 2字节 | 该页中记录的数量(不包括虚拟记录和删除记录) |
| PAGE_MAX_TRX_ID | 8字节 | 修改当前页的最大事务ID,仅在二级索引中使用 |
| PAGE_LEVEL | 2字节 | 当前页在B+树中所处的层级 |
| PAGE_INDEX_ID | 8字节 | 索引ID,表示当前页属于哪个索引 |
| PAGE_BTR_SEG_LEAF | 10字节 | B+树叶子段的头部信息,仅在B+树的Root页定义 |
| PAGE_BTR_SEG_TOP | 10字节 | B+树非叶子段的头部信息,仅在B+树的Root页定义 |
从上述表格可见,Page Header包含了极为丰富的数据信息,其中包括记录数量、B+树层级、索引归属ID、数据插入方向,以及最大事务ID等重要细节,每一项都承载着关键的信息。
索引的优化路径
既然我们已经对页面的数据组织结构有了基本的认识,接下来的问题是:我们如何利用这些经过深思熟虑的结构设计,以达到迅速检索数据的目的呢?
索引检索能力实现
从上述数据组织的相关知识中,我们可以观察到行记录之间以单向链表的形式相互连接,它们按照分组的方式有序地分布在每一页的最小记录和最大记录之间。
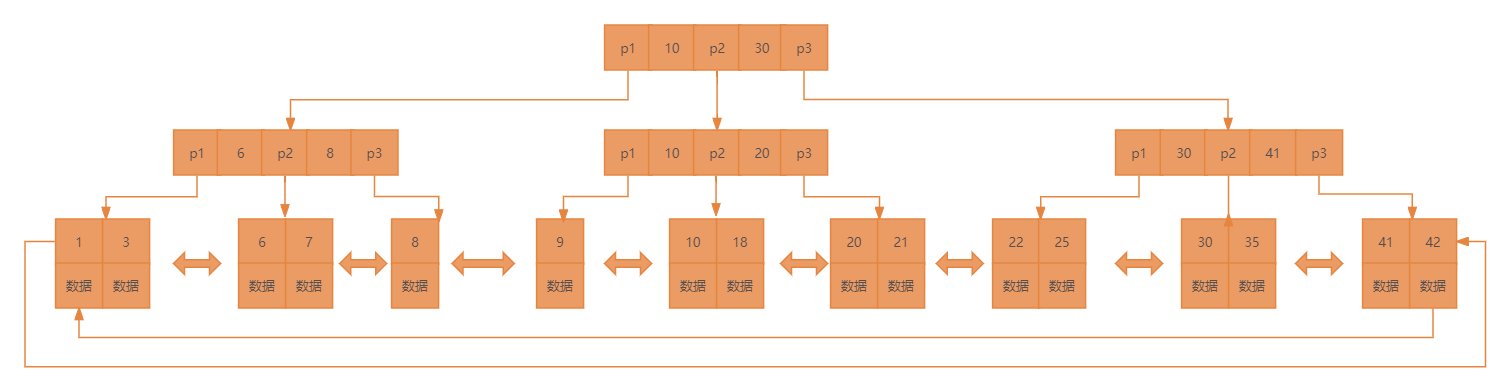
而各个页面之间,则通过上一页和下一页的指针相互串联,形成了一个双向链表的结构。这种组织方式使得数据在磁盘上的存储更加有序和高效,其具体结构可参考下图:
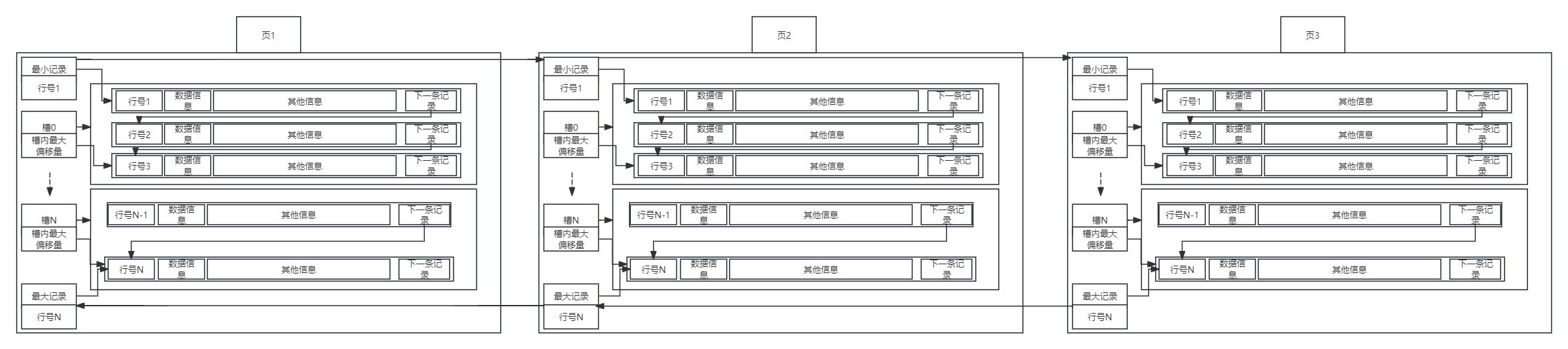
根据上图所展示的数据串联模式,我们自然可以想到一种查询方法:按照主键的顺序,依次遍历每个页面以及页面中的记录行。然而,这种查询方法除了在页面内部可以通过二分法进行优化外,整体效率并不高。那么,我们该如何改进呢?
先定位页目录+顺序搜索
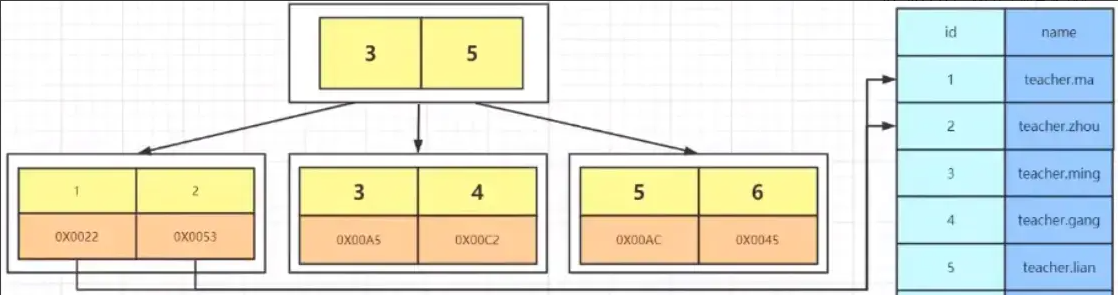
为了提升查询效率,我们可以将数据页进行聚合,构建一个页号目录。通过先在目录中定位,再进入对应页面进行查找,这样的方法远比简单的顺序查找高效。
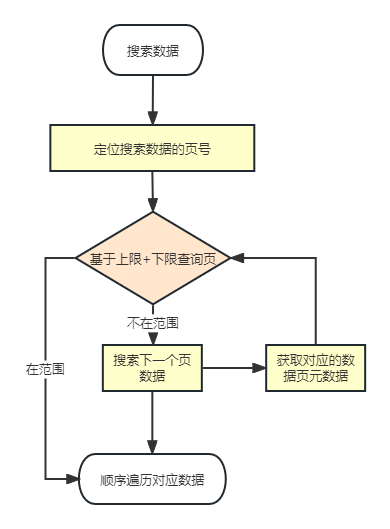
弊端:这种方法也存在一些问题。它需要大量的连续空间来存储目录,并且随着数据的变动,目录也需要频繁地更新。这引发了我们进一步的思考:如何解决这些问题并寻求更好的改进方案呢?
聚集索引性能搜索
在我们探讨行记录结构时,不难发现数据行中除了包含实际的业务数据外,还预留了不少额外空间。例如,record_type字段就用于指示该记录是数据类型还是索引类型。
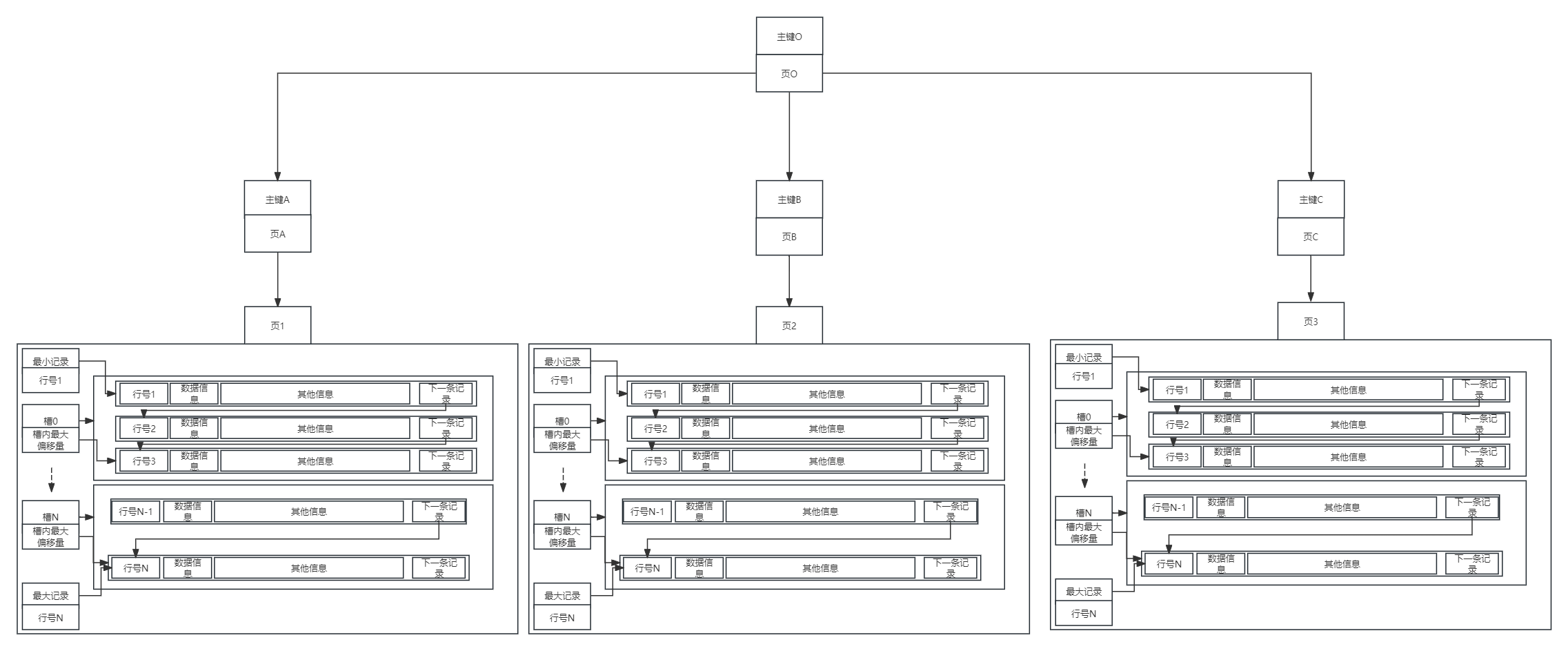
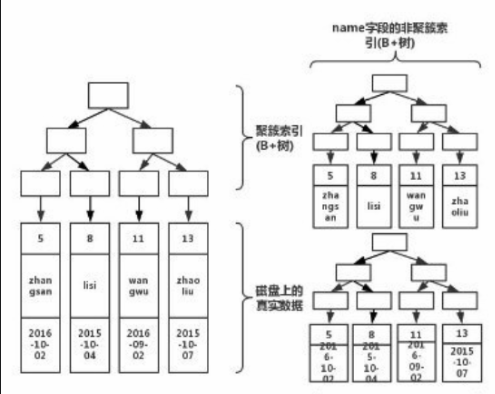
这就是目前MySQL常用的B+树索引结构,其中页节点具有明确的层级划分,而行记录则根据类型进行区分。所有的业务数据都被存储在叶子节点中,而目录数据则分布在其他非叶子节点里。
因此,它能够在相对较少的层级中容纳大量的数据项(这可以通过简单估算每页数据项的大小来预测)。这种索引方式通常被称为聚簇索引,它依据主键值对记录和页面进行排序,且所有的用户数据都存储在叶子节点中。
非聚集索引实现搜索
二级索引
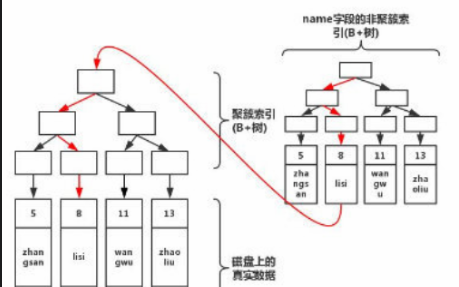
若用户需要基于特定列的值来进行数据检索,我们可以专门为此列创建一个新的B+树索引。这个新索引与聚簇索引的区别在于,它的目录结构是根据值来构建的,同时,其叶子节点中仅存储某一列的值和与之相关联的主键。
当用户需要查询除索引列之外的更多数据时,他们需要利用这个主键ID重新访问聚簇索引以获取所需信息,这一过程在数据库术语中被称为“回表”。
联合索引
二级索引指的是基于除主键外的单一列构建的索引,而联合索引则是根据多个列的值进行共同排序的索引。如果用户需要根据年龄、性别和地址这三列进行有序查询,那么查询的逻辑是:首先按照年龄列的值进行排序,对于年龄相同的记录,再根据性别的值进行排序,以此类推,直至考虑到地址列。这样的排序逻辑确保了查询结果的有序性。
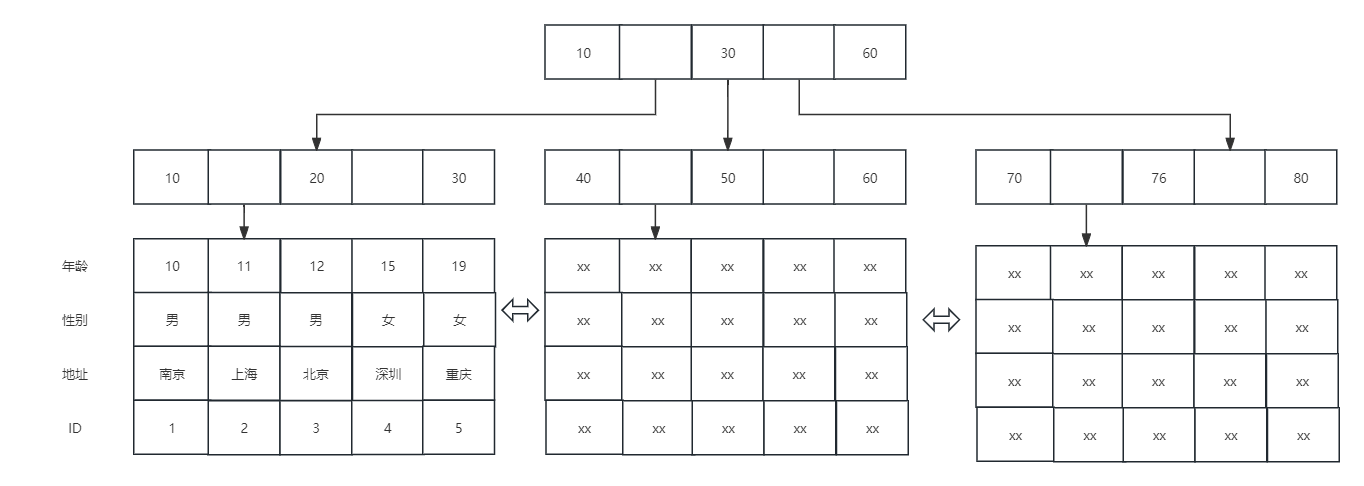
与二级索引相似,InnoDB会再创建一棵B+树来满足用户的查询需求。这棵树的目录项按照年龄和性别的顺序进行排序和串联,而其叶子节点的数据项则仅包含年龄、性别、地址以及主键ID这四个值。
总结介绍
-
InnoDB数据库以页作为数据存取的基础单元,其默认大小为16KB。为了满足不同的需求,InnoDB设计了多种类型的页,所有类型的页都共享一个通用的结构,即页的首尾部分包含File Header和File Trailer,这两部分记录了页面的通用状态信息,并利用Checksum来确保页面的完整性。
-
索引页则具有其特有的Page Header结构,该结构存储了与用户记录相关的状态信息。用户记录实际存储在User Records区域。此外,考虑到页面内可能包含大量的记录,为了提高检索效率,InnoDB在索引页中引入了Page Directory。
-
数据目录通过将记录分组,并记录每组中最大记录的地址偏移量来形成槽位,从而构成Page Directory。在检索数据时,通过二分法迅速定位到相应的槽位组,有效避免了全面遍历记录组的需求。
这篇关于作者推荐 | 探索分析从起源到现今的巅峰之旅(MySQL存储模型)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





