本文主要是介绍Tensorflow-GPU工具包了解和详细安装方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
基础知识信息了解
显卡算力
CUDA兼容
Tensorflow gpu安装
CUDA/cuDNN匹配和下载
查看Conda driver的版本
下载CUDA工具包
查看对应cuDNN版本
下载cuDNN加速库
CUDA/cuDNN安装
CUDA安装方法
cuDNN加速库安装
配置CUDA/cuDNN环境变量
配置环境变量
核验是否安装成功
Tensorflow-gpu安装
命令安装
报错处理
核验安装结果
直通车:人工智能发展历程和工具搭建学习-CSDN博客
通过之前的文章学习,我们已经安装好了Anaconda和Tensorflow2.4,但是在后期的学习中,会涉及到神经网络的学习等数据量较大的操作,普通的tensorflow-cpu版本处理速度较慢,所以我们再安装一个更加强大的tensorflow-gpu版本,它可以调用conda的接口实现gpu运算的平台,利用显卡帮助我们运算程序,以提高后期学习中的程序处理速度,提高学习效率。
基础知识信息了解
显卡算力
在这个之前,我们首先要确保自己的电脑是英伟达显卡,并且运算能力在3.5以上,大家可以根据下面的网址查看自己电脑显卡的运算能力,然后还需要下载conda工具包和对应的gpu加速库cuDNN。
直通车:CUDA GPUs - Compute Capability | NVIDIA Developer
后期安装CUDA通过deviceQuery.exe也可以看到当前显卡的算力。
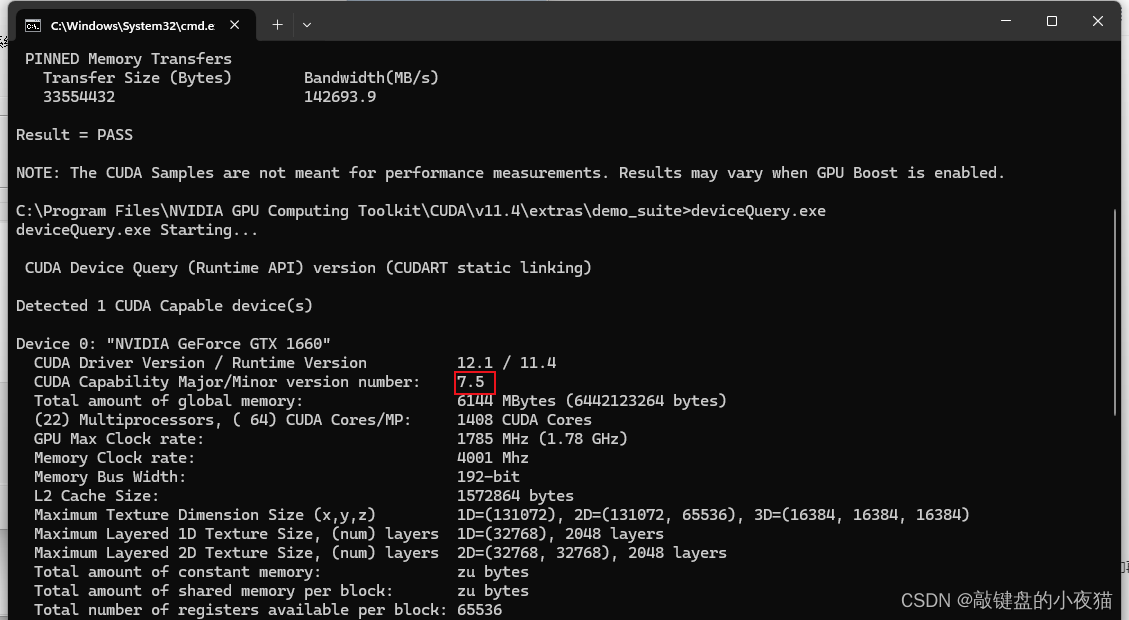
CUDA兼容
这里CUDA12.1是支持的最高版本的CUDA,可以向下兼容,且可以安装多个版本的CUDA,你可以通过更改环境变量来更改为你需要用到的CUDA版本。

Tensorflow gpu安装
CUDA/cuDNN匹配和下载
查看Conda driver的版本
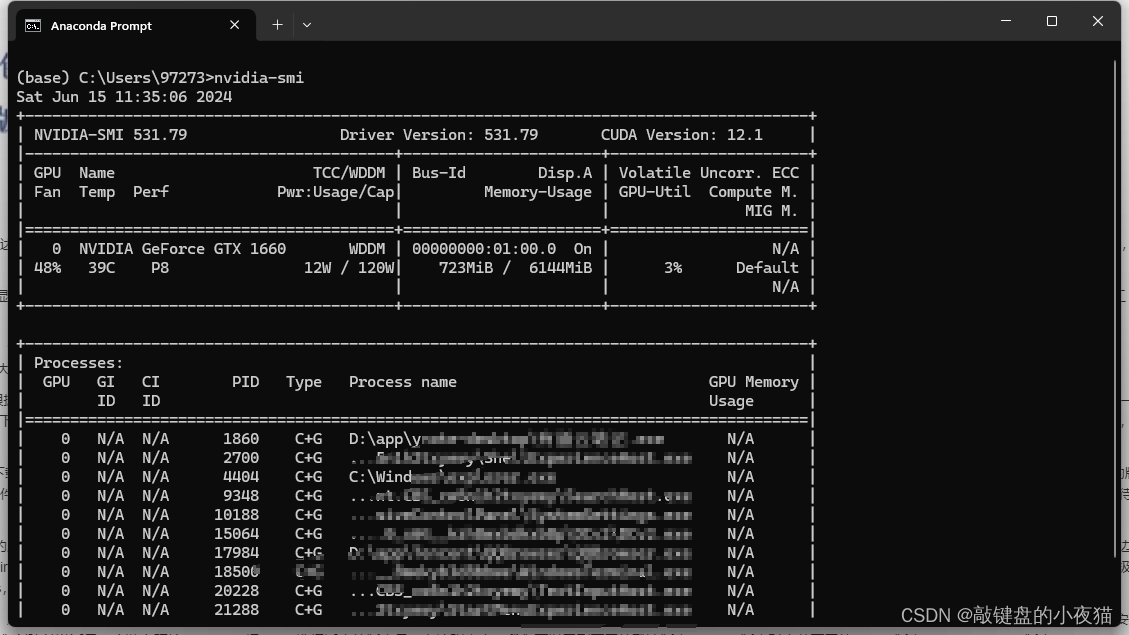
我们打开命令行窗口cmd,输入nvidia-smi,这里显示的是显卡的版本信息,这里显示的是conda driver的版本信息。
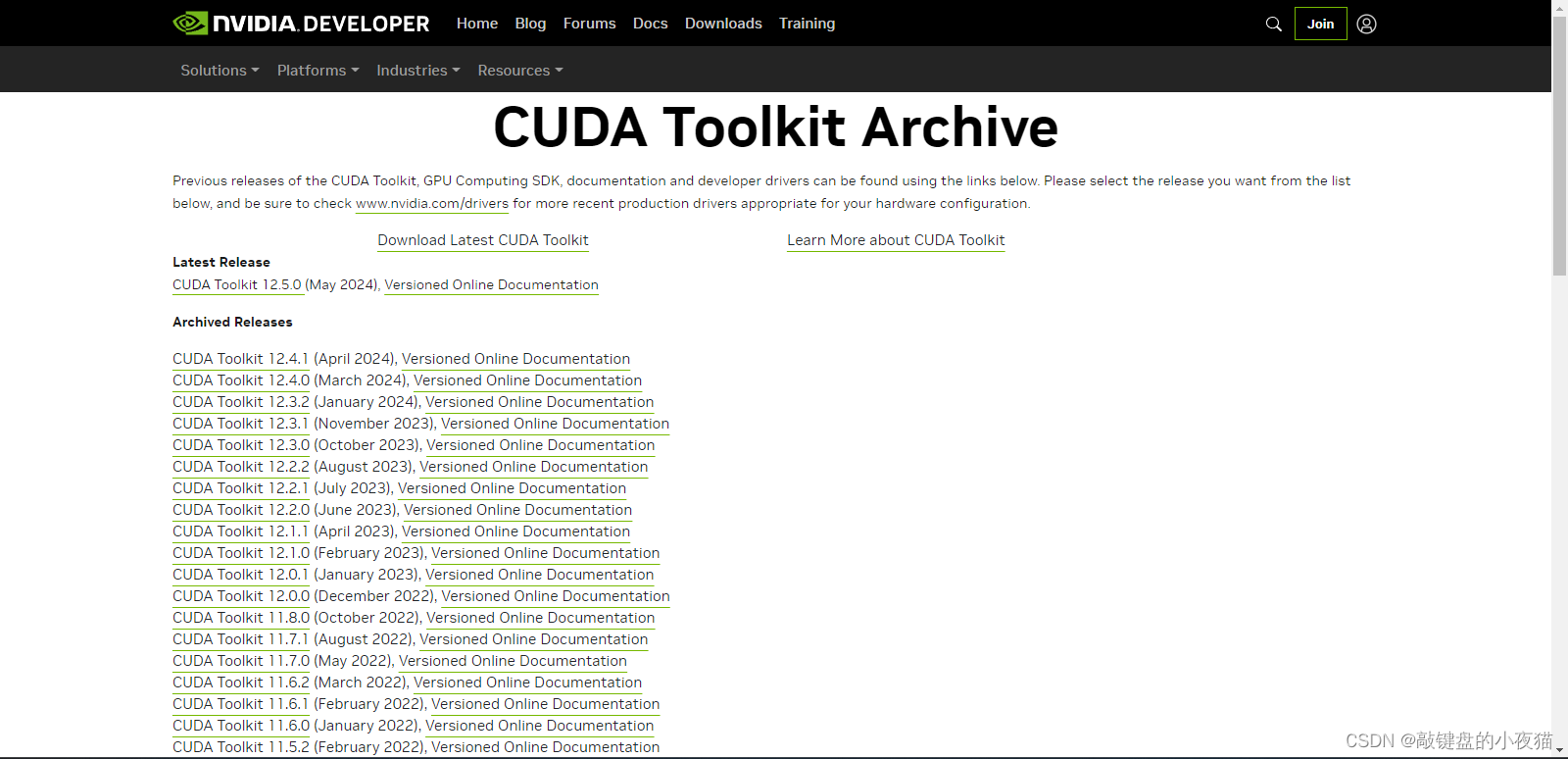
下载CUDA工具包
直通车:CUDA Toolkit Archive | NVIDIA Developer
我们去conda下载官网,下载CUDA工具包。根据刚刚我们查到的CUDA版本信息,此处我的CUDA版本为12.x,根据CUDA可以向下兼容的特性,我们可以对应下载CUDA11.4的工具包。
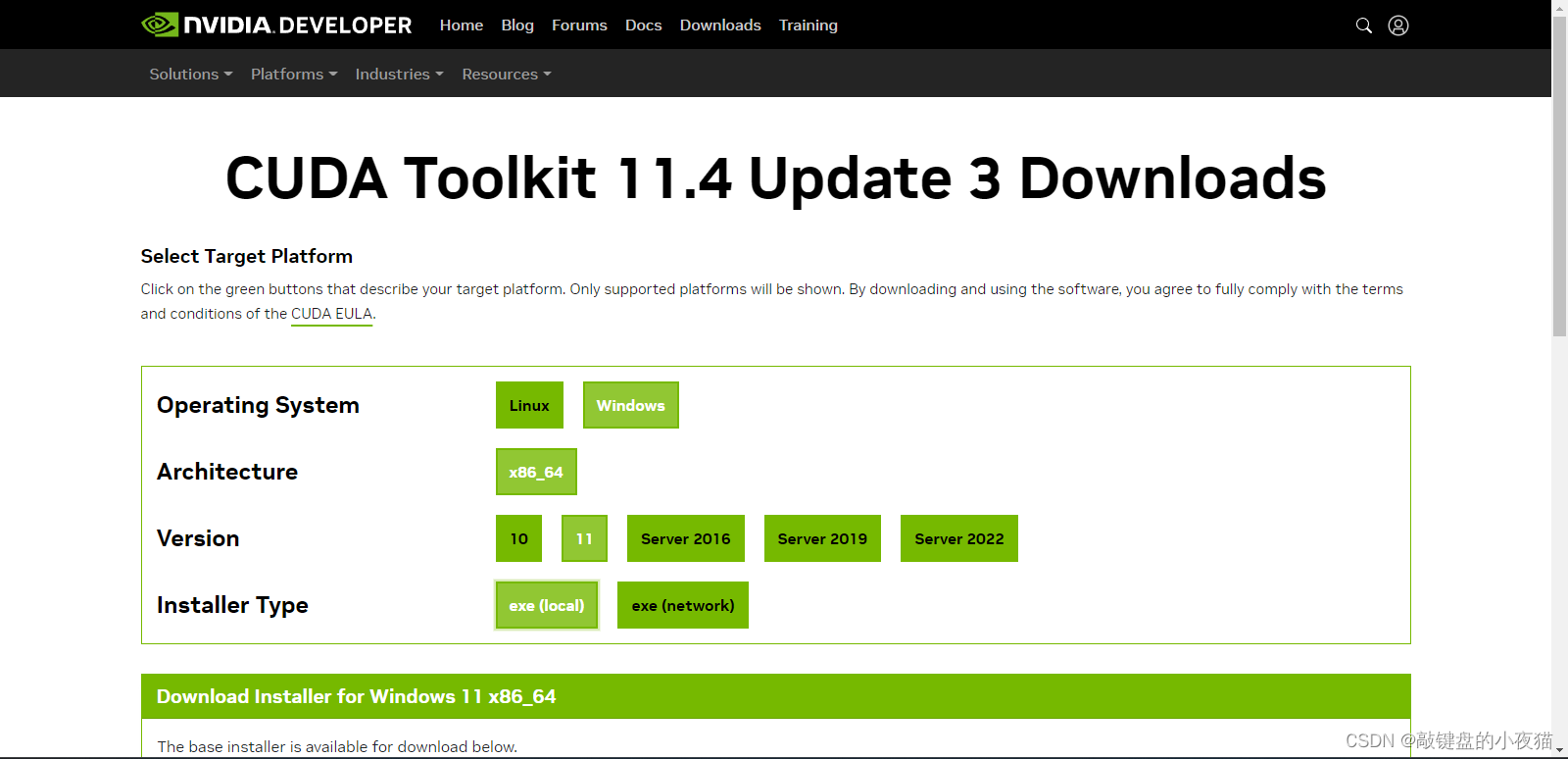
在这个界面,由于我的电脑是Windows11 64位,所以我选择的是这些选项,大家要根据自己的电脑系统类型选择合适的版本进行下载。
查看对应cuDNN版本
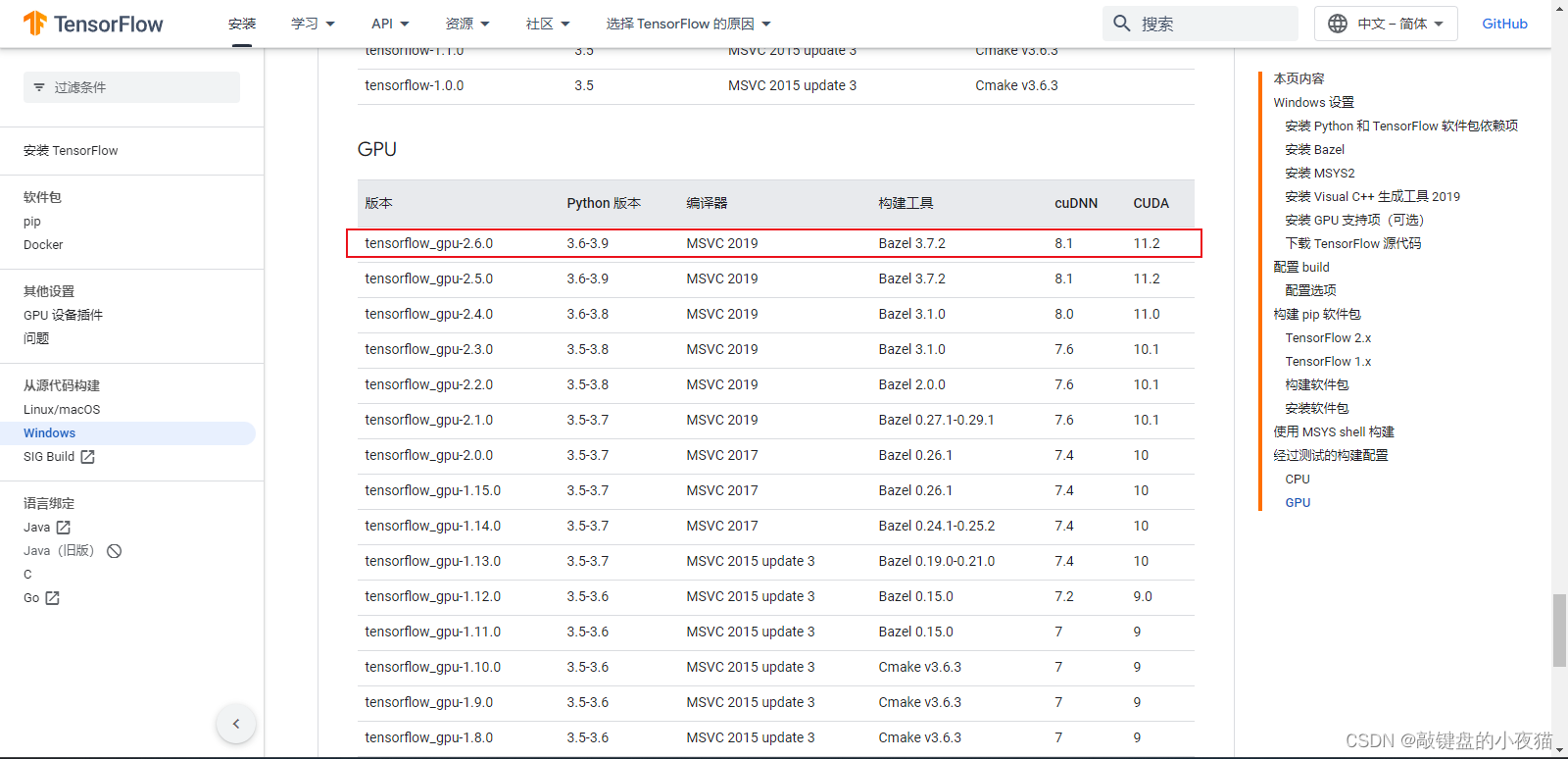
下面查找对应的cuDNN版本,可以在Tensorflows官网中查看tensorflow-gpu跟cuda cudnn的版本对应信息.
在 Windows 环境中从源代码构建 | TensorFlow
下载cuDNN加速库
接下来我们打开cuDNN下载地址:
直通车:https://developer.nvidia.com/rdp/cudnn-archive
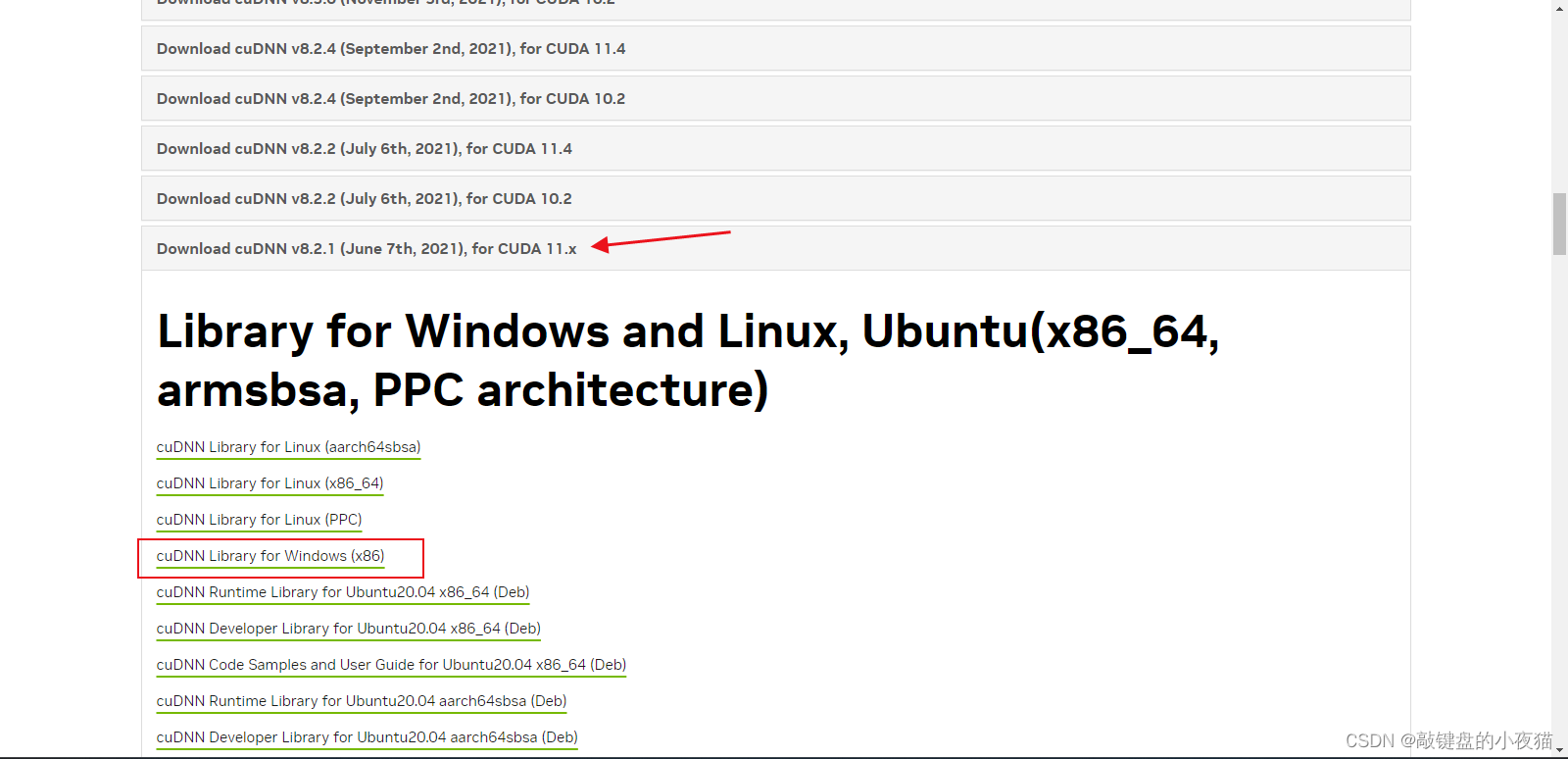
由于我们CUDA是11的版本 对应的是cuDNN8的版本,这些版本的对应,小伙伴们一定要注意!现在我们打开cuDNN下载官网,在这里,根据刚刚查看到的cuda版本,选择适当的cuDNN版本,我刚下载的是CUDA11.4的版本,也就是CUDA11.x的版本,所以我选择的是cuDNN8.x的版本,这里我下载版本为8.2.1,然后选择windows x86的选项进行下载。
注意:在这里点击下载的时候会跳转到注册登录页面,由于在这里我已经登录,所以没有跳转,等待安装包下载完成,我们就准备好了Tensorflow-gpu所需要的工具包,这就是已经下载好的工具包。
如果各位小伙伴在这里遇到问题无法解决,可以在评论区进行求助。
CUDA/cuDNN安装
CUDA安装方法
接下来我们开始安装CUDA,双击打开下载的安装包,并等待进度条加载完毕。
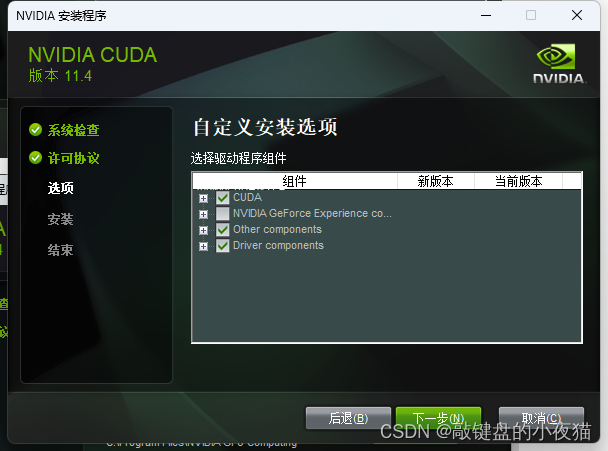
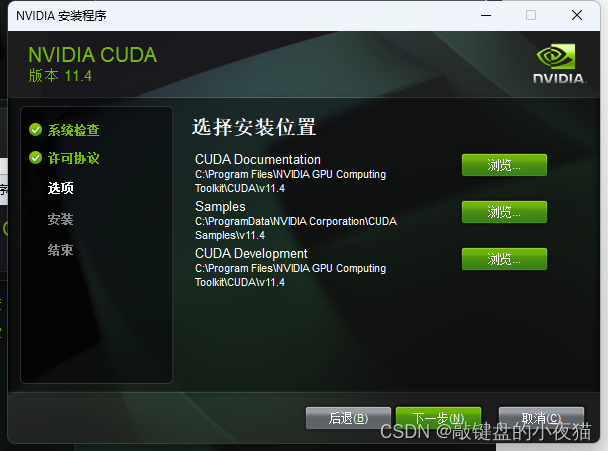
点击同意并继续选择自定义,然后点击下一步。在这个界面显示的是将要安装的组件名称、版本号和电脑中该组件的版本号,当前版本号为空,则说明电脑中没有该组件。
我们取消NVIDIA GeForce Experience这一项,然后点击下一步。这里的安装路径一般选择默认就好,也可以更改,但是文件目录一定要记清楚,后面配置环境的时候会用到。
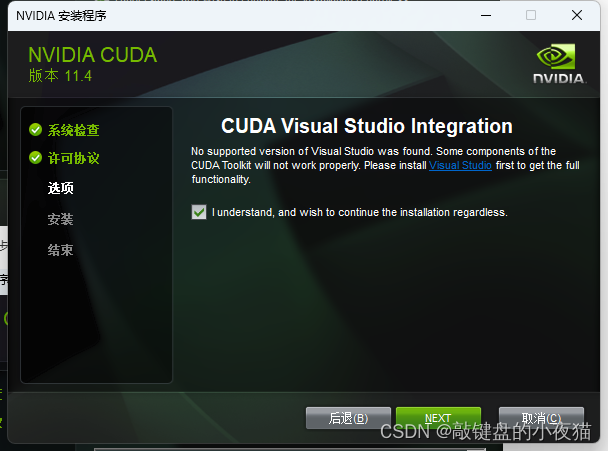
然后点击下一步,点击next,等待安装完成。
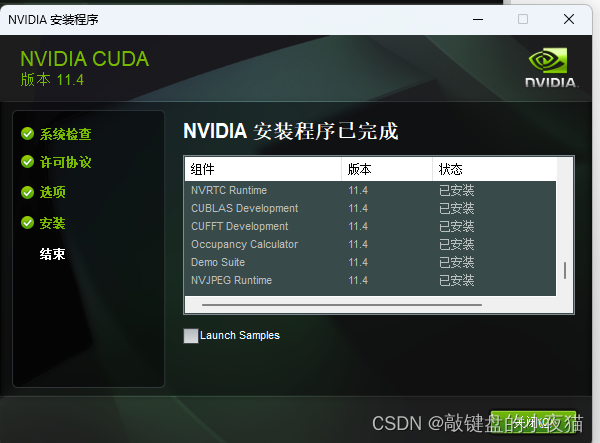
然后点击下一步,这里显示的是已经安装的所有组件的状态,然后点击关闭。
cuDNN加速库安装
下面开始安装Gpu加速库cuDNN,将文件解压,解压完成以后,我们打开会得到如下三个目录。
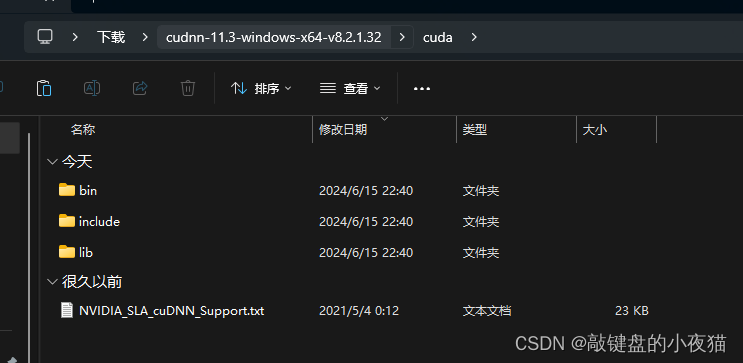
然后我们打开刚刚安装好的CUDA的根目录,然后把codnn里边并目录下的所有文件复制到CUDA的bin目录如下。

将include里边的所有文件复制到CUDA的include文件下,lib文件夹也是如此。这样我们便完成了CUDA和cuDNN的安装。
配置CUDA/cuDNN环境变量
配置环境变量
下面开始设置系统环境变量,右键点击此电脑,选择属性打开高级系统,设置环境变量,在系统变量里面找到path,点击编辑。我们可以看到CUDA的两个文件已经存在,点击新建浏览,找到CUDA目录。
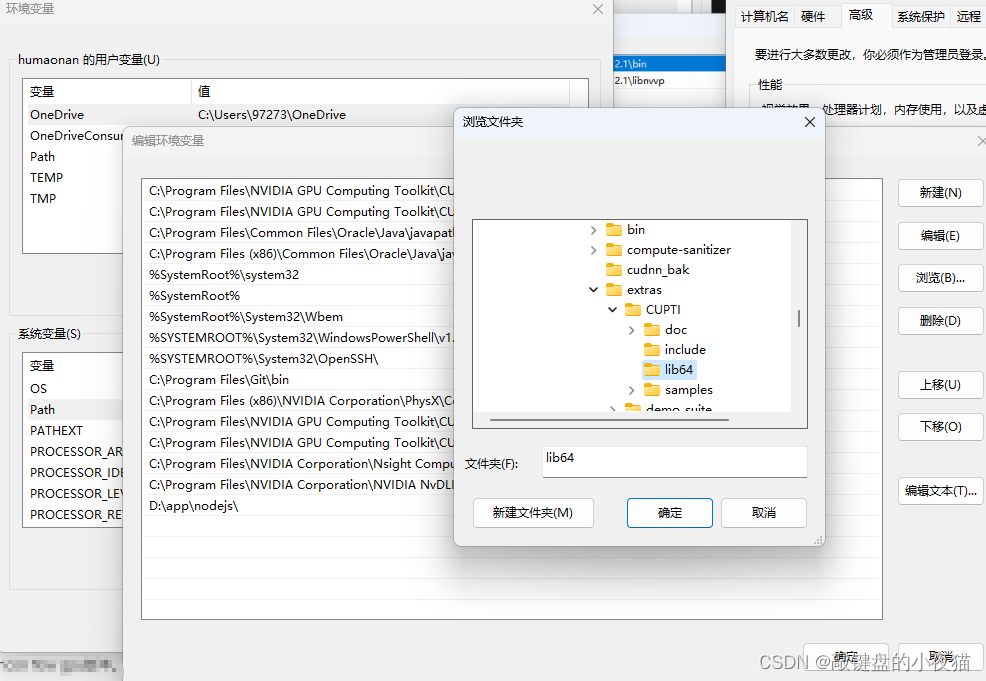
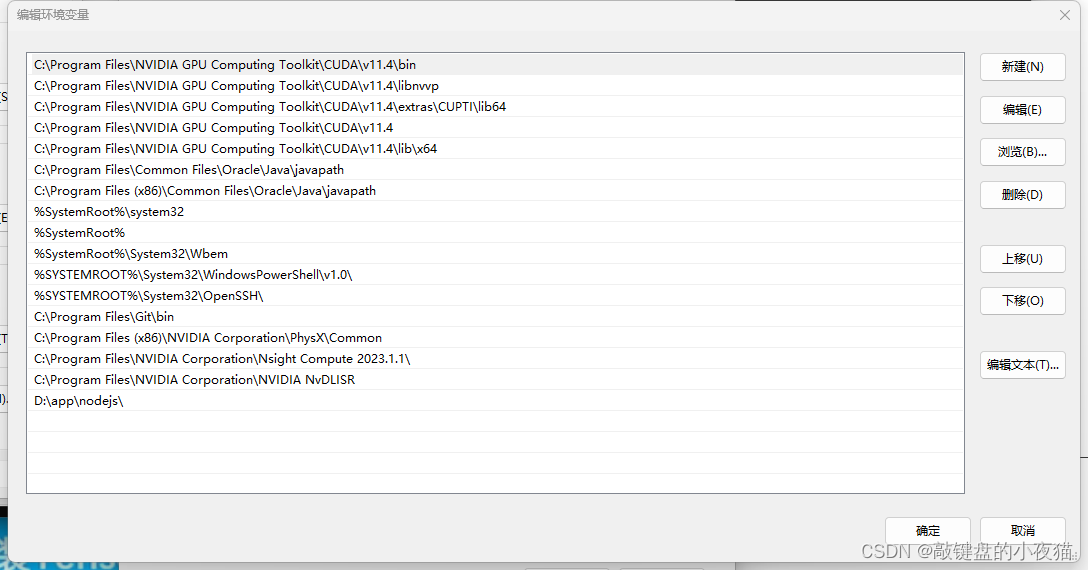
将其上移,与其他两个环境变量一起,这样就完成了环境变量的设置。
核验是否安装成功
可以通过nvcc -V命令查看是否配置CUDA成功

输入nvidia-smi命令,返回GPU型号则安装成功
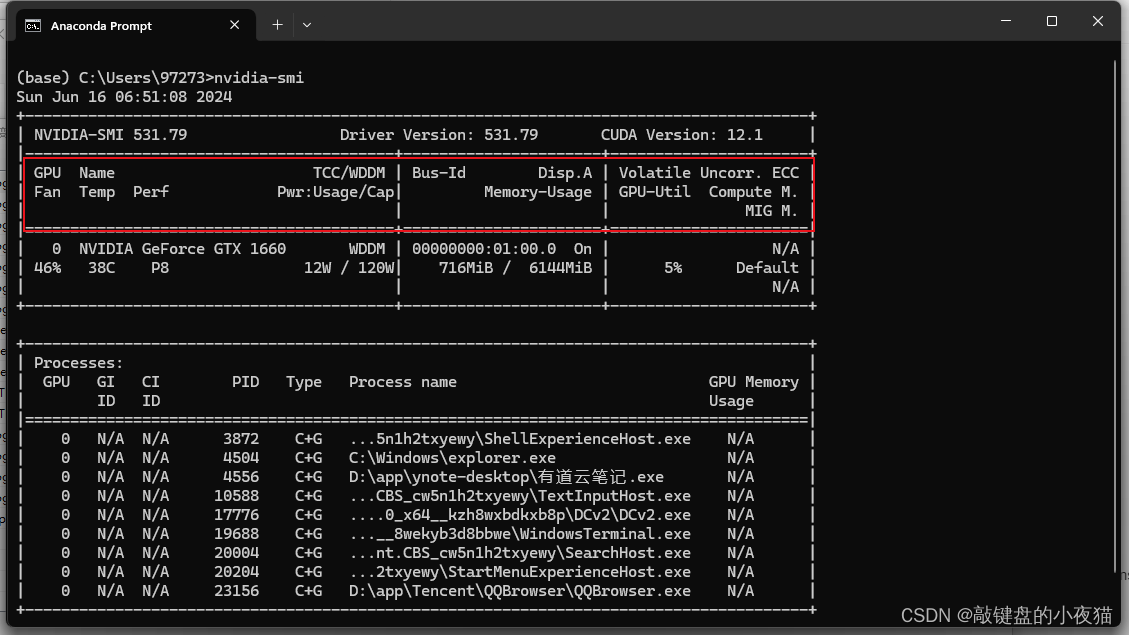
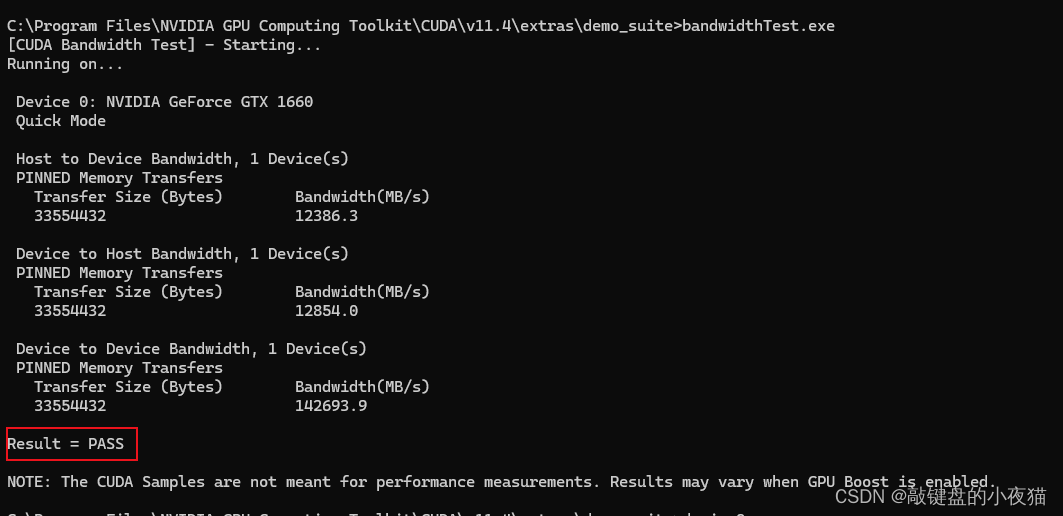
同时也可以通过在CUDA执行bandwidthTest.exe和deviceQuery.exe和核验,返回PASS则表明GPU安装成功
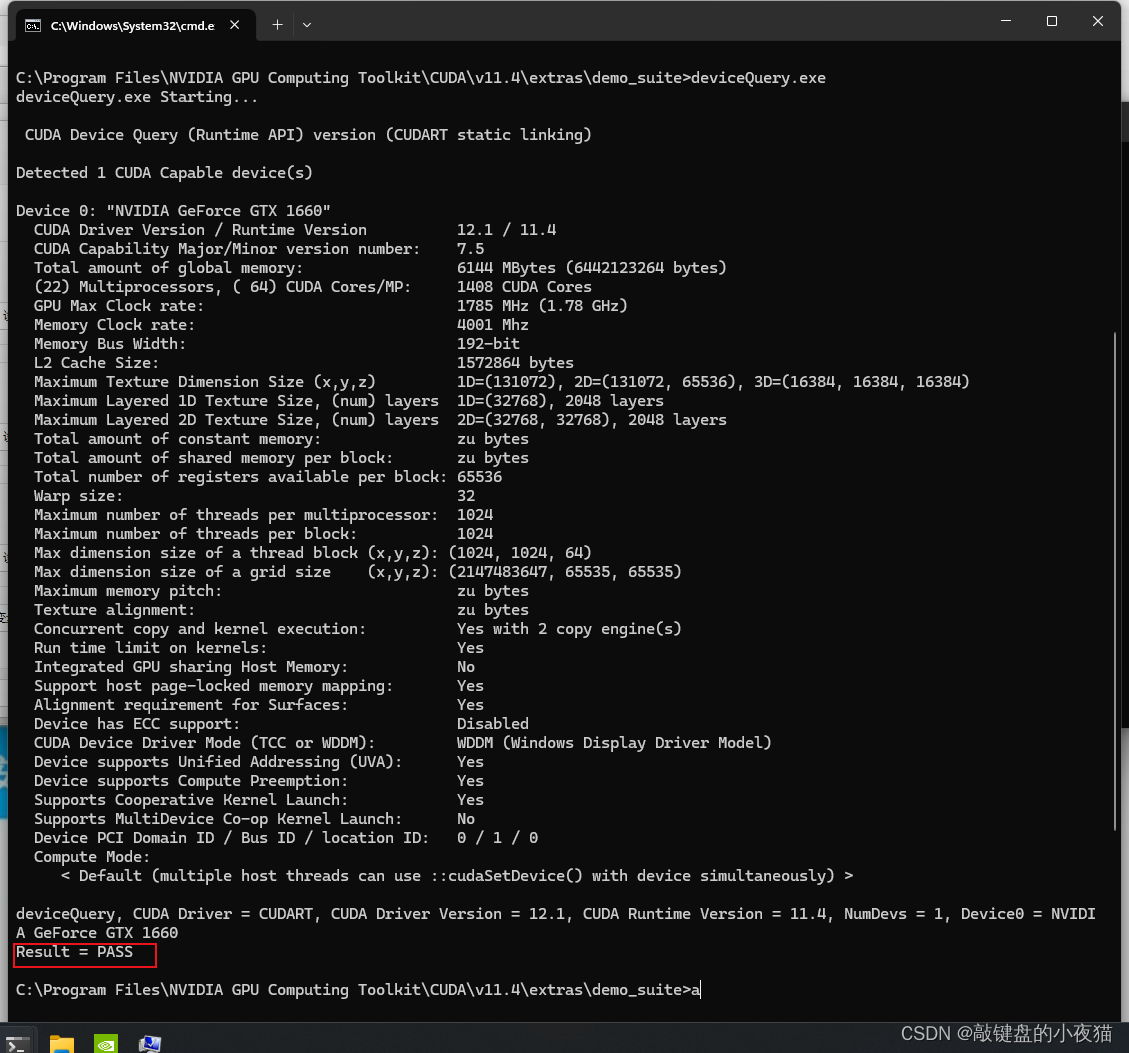
Tensorflow-gpu安装
接下来我们开始安装tensorflow-gpu,安装过程可以参考上篇文章tensnflow2.4的安装,这里我就不再详述。不同之处,就是我们创建并激活另一个独立环境tensorflow-gpu选择适当的版本号,小伙伴们可以根据自己的安装环境选择对应的版本安装,第二步是安装相关软件,在第三步的时候安装tensorflow-gpu,命令为pip install tensorflow-gpu==对应版本号安装完成以后就完成了tensorflow-gpu的安装。
直通车:人工智能发展历程和工具搭建学习-CSDN博客
命令安装
创建独立环境并激活
conda create -n tensorflow-gpu python==3.8conda activate tensorflow-gpu安装相关软件包
# conda install numpy matplotlib PIL scikit-learn pandas 于下行命令等价pip install numpy matplotlib Pillow scikit-learn pandas -i Simple Index安装Tensorflow-gpu
pip install tensorflow-gpu==2.6.0 -i Simple Index报错处理
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. matplotlib 3.7.5 requires numpy<2,>=1.20, but you have numpy 1.19.5 which is incompatible. pandas 2.0.3 requires numpy>=1.20.3; python_version < "3.10", but you have numpy 1.19.5 which is incompatible.
pip uninstall numpypip install numpy==1.19.5TypeError: Descriptors cannot be created directly. If this call came from a _pb2.py file, your generated code is out of date and must be regenerated with protoc >= 3.19.0. If you cannot immediately regenerate your protos, some other possible workarounds are: 1. Downgrade the protobuf package to 3.20.x or lower. 2. Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python (but this will use pure-Python parsing and will be much slower).
pip uninstall protobuf pip install protobuf==3.20.0
校验安装结果
最后我们测试一下是否安装成功,打开命令行窗口,激活我们刚才创建的独立环境。输入python,打开python交互模式,输入import tensorflow as tf,输入我们的测试语句tf.test.is_gpu_available(),它的输出结果为true,显示我们安装成功。
pythonimport tensorflow as tftf.test.is_gpu_available()exit()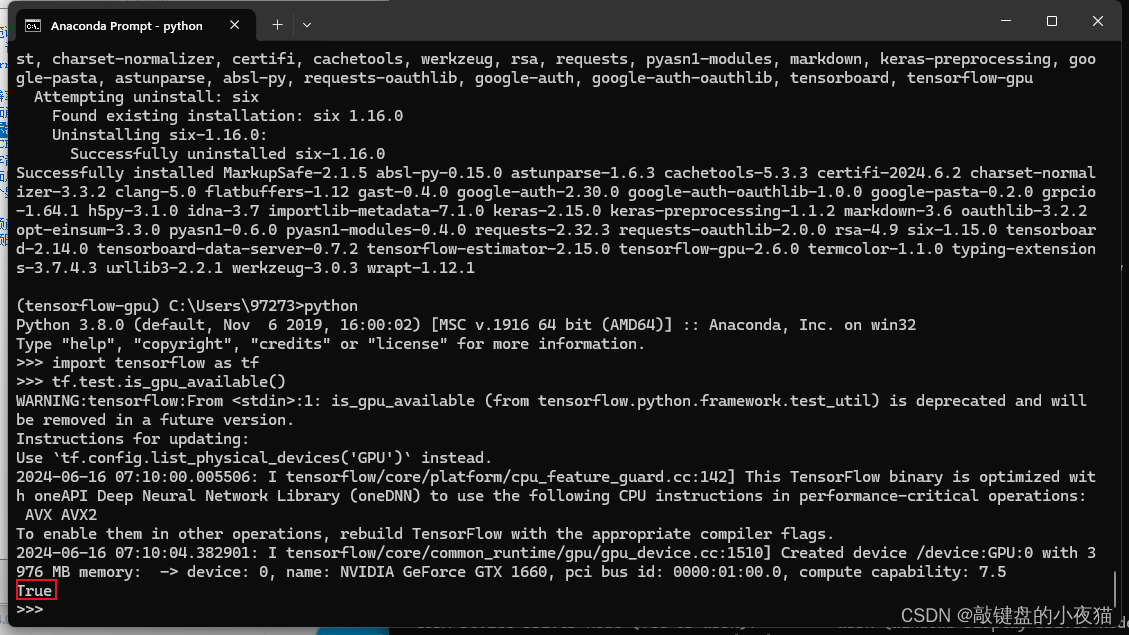
这篇关于Tensorflow-GPU工具包了解和详细安装方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






