本文主要是介绍【招联消费金融股份】有限公司2024年5月18日【算法开发岗暑期实习】一面试经验分享,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
招联消费金融股份有限公司2024年5月18日面试经验分享
- 面试流程:共30多分钟,先3分钟自我介绍,然后细细介绍简历上面的论文和实习信息。
- 问题1:扩散模型的noise schedule有什么研究。
- 问题2:有哪些常见的数学分布
- 问题3:用过哪些优化器,详细介绍一下特点和策越,为什么好?
- 问题4:详细介绍LORA,对于不同秩的对比实验设置有没有了解,优势是什么,如何初始化的?
- 问题5:介绍minhash算法的实现
- 问题6:特征提取器用过哪些,介绍一下。
- 问题7:transformer介绍一下架构,QKV机制。
- 问题8:python与c++的源层面上的不同,比如python的GIL,深拷贝和浅拷贝。python是静态语言还是动态语言,pytorch的神经网络是静态图还是动态图。
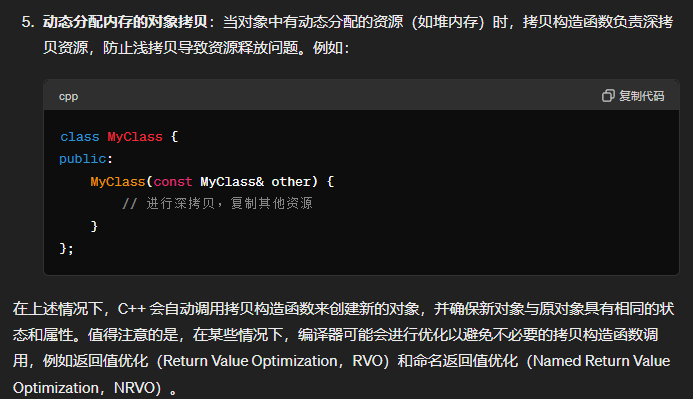
- 问题9:c++的拷贝构造函数是在什么时候调用的
- 问题10:对于传统的机器学习方法有没有了解,决策树和聚类(k-means),介绍k-means的特点,类别数量是模型学习的还是人为定义的?每个类里面是假设符合什么分布?
- 问题11:介绍强化学习DP,蒙特卡洛法和dt算法。
- 问题12:线性代数,介绍特征值和特征向量。
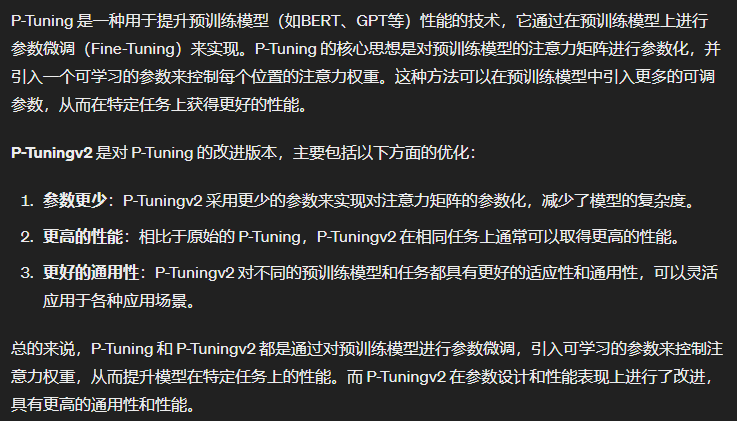
- 问题13:介绍P-Tunig和P-Tuningv2
- 问题14:介绍ChatGLM、LLAMA。
面试流程:共30多分钟,先3分钟自我介绍,然后细细介绍简历上面的论文和实习信息。
问题1:扩散模型的noise schedule有什么研究。
从0.0001到0.02有linear,cosine,sqrt_linear,sqrt
def make_beta_schedule(schedule, n_timestep, linear_start=1e-4, linear_end=2e-2, cosine_s=8e-3):if schedule == "linear":betas = (torch.linspace(linear_start ** 0.5, linear_end ** 0.5, n_timestep, dtype=torch.float64) ** 2)elif schedule == "cosine":timesteps = (torch.arange(n_timestep + 1, dtype=torch.float64) / n_timestep + cosine_s)alphas = timesteps / (1 + cosine_s) * np.pi / 2alphas = torch.cos(alphas).pow(2)alphas = alphas / alphas[0]betas = 1 - alphas[1:] / alphas[:-1]betas = np.clip(betas, a_min=0, a_max=0.999)elif schedule == "sqrt_linear":betas = torch.linspace(linear_start, linear_end, n_timestep, dtype=torch.float64)elif schedule == "sqrt":betas = torch.linspace(linear_start, linear_end, n_timestep, dtype=torch.float64) ** 0.5else:raise ValueError(f"schedule '{schedule}' unknown.")return betas.numpy()
问题2:有哪些常见的数学分布
'离散分布'二项分布 (Binomial Distribution)用途: 用于描述在n次独立试验中成功的次数,每次试验成功的概率为p。
参数: n(试验次数),p(成功的概率)。
例子: 抛硬币n次,统计正面朝上的次数。泊松分布 (Poisson Distribution)用途: 用于描述在固定时间或空间内某事件发生的次数。
参数: λ(单位时间或空间内事件的平均发生率)。
例子: 每小时顾客到达商店的次数。几何分布 (Geometric Distribution)用途: 用于描述第一次成功之前需要的失败次数。
参数: p(每次试验成功的概率)。
例子: 抛硬币直到第一次出现正面。'连续分布'正态分布 (Normal Distribution)用途: 用于描述许多自然现象和测量数据。
参数: μ(均值),σ²(方差)。
例子: 人的身高、考试成绩等。指数分布 (Exponential Distribution)用途: 用于描述时间间隔或寿命。
参数: λ(事件发生的速率)。
例子: 机器的故障时间。均匀分布 (Uniform Distribution)用途: 用于描述在一定范围内每个值都有相同概率的情况。
参数: a(最小值),b(最大值)。
例子: 随机生成的密码。卡方分布 (Chi-Square Distribution)用途: 用于检验样本方差和假设方差的差异。
参数: k(自由度)。
例子: 假设检验中的卡方检验。t分布 (Student's t-Distribution)用途: 用于小样本的均值推断和假设检验。
参数: ν(自由度)。
例子: 小样本的均值检验。'其他分布'贝塔分布 (Beta Distribution)用途: 用于描述概率的分布。
参数: α和β(形状参数)。
例子: 用于贝叶斯统计中的先验分布。伽玛分布 (Gamma Distribution)用途: 用于描述等待时间。
参数: k(形状参数),θ(尺度参数)。
例子: 处理时间、服务时间分布。
问题3:用过哪些优化器,详细介绍一下特点和策越,为什么好?



Adam及其变种:结合动量和自适应学习率,快速稳定收敛,适用于大多数深度学习任务。
AdamW 是 Adam 优化器的改进版本,旨在解决 Adam 优化器在某些情况下会导致权重衰减(weight decay)效果不佳的问题。AdamW 是由 Ilya Loshchilov 和 Frank Hutter 提出的,并在他们的论文《Decoupled Weight Decay Regularization》中详细介绍。


AdamW 是一种改进的 Adam 优化器,通过将权重衰减与梯度更新分离,提供了更好的正则化效果和更快的收敛速度。它在许多深度学习任务中表现优异,是现代深度学习中常用的优化器之一。
问题4:详细介绍LORA,对于不同秩的对比实验设置有没有了解,优势是什么,如何初始化的?



问题5:介绍minhash算法的实现



问题6:特征提取器用过哪些,介绍一下。
很多,比如人脸身份信息的特征提取器,Arcface, Cosface, blendface等等。GAN和VQVAE的图像编码器等Autoencoders。
Word2Vec
PCA
SIFT(尺度不变特征变换)(Scale-Invariant Feature Transform)
TF-IDF(Term Frequency-Inverse Document Frequency)(词频-逆文档频率)
问题7:transformer介绍一下架构,QKV机制。


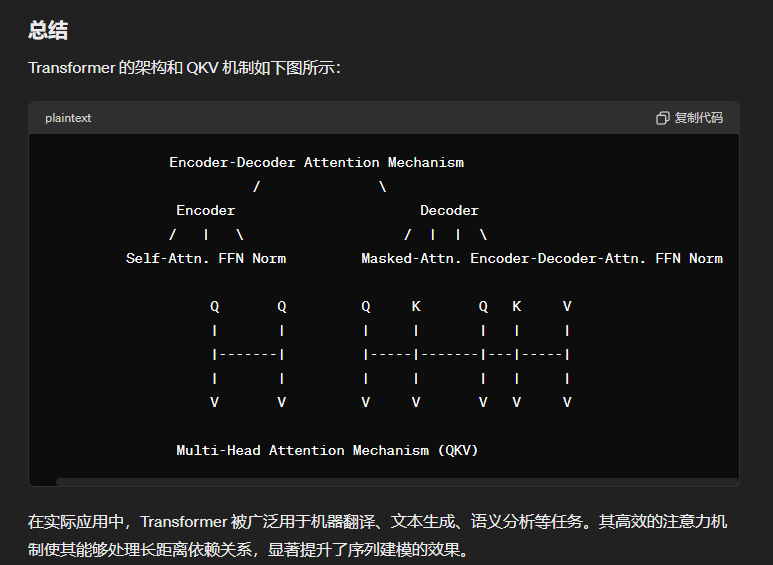
问题8:python与c++的源层面上的不同,比如python的GIL,深拷贝和浅拷贝。python是静态语言还是动态语言,pytorch的神经网络是静态图还是动态图。

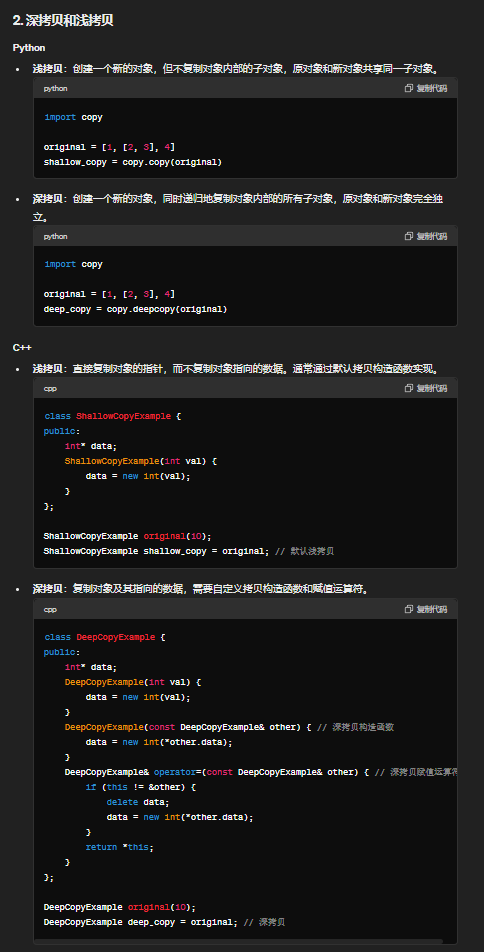
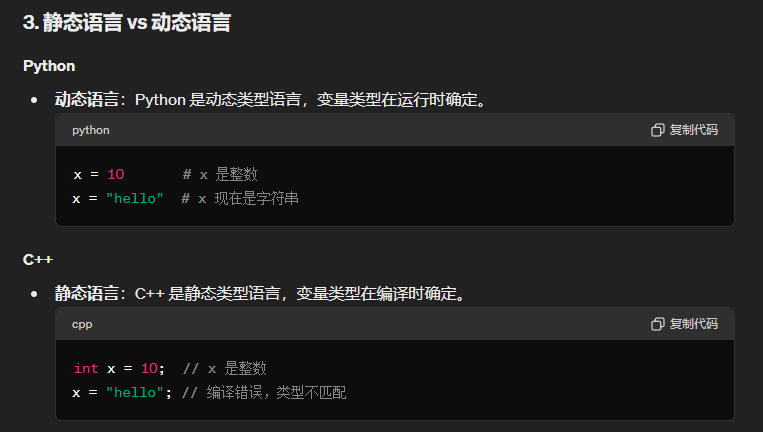


问题9:c++的拷贝构造函数是在什么时候调用的
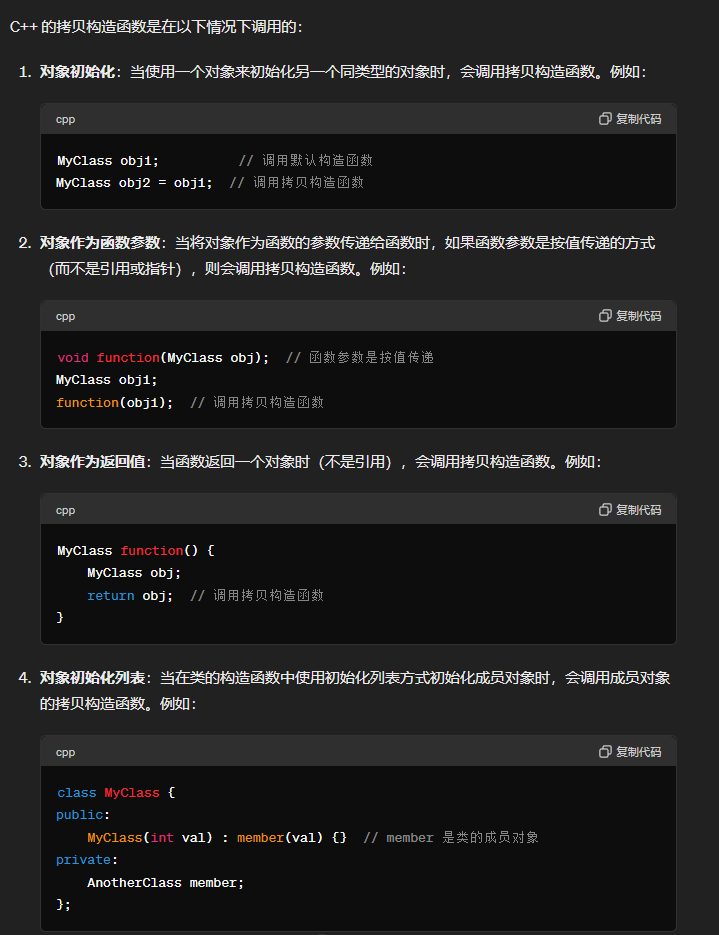
问题10:对于传统的机器学习方法有没有了解,决策树和聚类(k-means),介绍k-means的特点,类别数量是模型学习的还是人为定义的?每个类里面是假设符合什么分布?


下面是 K-Means 算法的伪代码表示:
输入:数据集 X,簇数量 K
输出:簇分配结果(cluster_assignment),簇中心(centroids)1. 初始化簇中心 centroids
2. 迭代优化:重复执行以下步骤,直到满足停止条件:a. 簇分配:对每个数据点 x 属于 X:计算 x 与所有 centroids 的距离,选择最近的簇中心所属的簇作为 x 的簇分配结果 cluster_assignment[x]b. 簇中心更新:对每个簇 c 属于 K:计算 c 中所有数据点的均值向量作为新的簇中心 centroids[c]停止条件:
- 达到最大迭代次数
- 簇中心不再变化(收敛)
- 其他停止条件
需要注意的是,K-Means 算法的结果可能会受到初始簇中心的影响,不同的初始值可能导致不同的聚类结果。因此,通常会多次运行算法,选择最优的聚类结果作为最终输出。
问题11:介绍强化学习DP,蒙特卡洛法和dt算法。

比较与应用
- DP 适用于确定性环境下的最优化问题,但需要完整的环境模型。
- 蒙特卡洛方法不需要环境模型,但需要大量的采样轨迹来进行值函数估计。
- TD 算法结合了增量学习和模型无关的特点,适用于需要实时学习和模型不完全的情况。
在实际应用中,这些方法可以根据问题的特点结合使用,例如在强化学习中使用 DP 进行价值函数的初始化和策略改进,结合蒙特卡洛方法进行策略评估,或者使用 TD 算法进行增量学习和实时更新。
问题12:线性代数,介绍特征值和特征向量。

问题13:介绍P-Tunig和P-Tuningv2
问题14:介绍ChatGLM、LLAMA。





♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠
这篇关于【招联消费金融股份】有限公司2024年5月18日【算法开发岗暑期实习】一面试经验分享的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







