本文主要是介绍高阶数据结构[2]图的初相识,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
图的初相识
1.前言
2.图的概念
3.图的相关术语
4.图的存储结构
4.1邻接矩阵
4.2邻接表
4.3两种存储方式的对比
5.图的存储实现
5.1邻接矩阵的实现
5.2邻接表的实现
6.总结
1.前言
本章将大家学习数据结构中的“图”。有学习过离散数学的同学对这一章节或许会比较熟悉。本篇文章将从最基础的概念开始介绍,一步步深入。让我们开始吧!
2.图的概念
大家是否还记得我们学过的“树”?“树”就是一种无环的连通图。
图有两个部分组成:1.顶点集合 2.顶点间形成的边。
因此图是一种由顶点集合以及边集合组成的一种数据结构表示为G=(V,E)。

下面我们用图像来理解该概念。
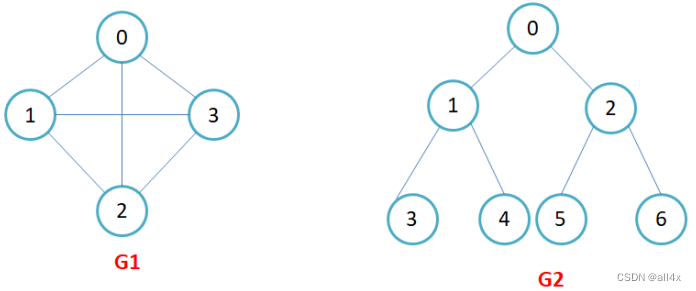
如上图所示。G1中四个顶点0,1,2,3 ,各顶点形成连接的边。抽象概念可以表示为顶点集合v1,v2,v3,v4。形成的边可以表示为ek=(vi,vj),表示改边由顶点vi和vj连接而成。
G2就是我们刚刚介绍的树是一种无向连通图。
既然说到了无向图,那么必然就有有向图。如图,G3,G4均为有向图。相信大家能看出来有向图和无向图的区别了!无向图没有明确的指向,而有向图则有明确的指向。
3.图的相关术语
在图的学习中,会涉及到大量的专业名词,我们在此一一列举。
完全图:在有n个顶点的无向图中,若有n * (n-1)/2条边,即任意两个顶点之间有且仅有一条边,则称此图为无向完全图. 上图的G1就是无向完全图, G4为有向完全图。
邻接顶点: 若顶点u和v有直接的边相连, 那么它们这两个顶点就称为邻接顶点。
顶点的度: 顶点v的度是它相关联的边的条数,记作deg(v)。在有向图中,顶点的度等于该顶点的入度与出度之和,其中顶点v的入度是以v为终点的有向边的条数,记作indev(v);顶点v的出度是以v为起始点的有向边的条数,记作outdev(v)。因此:dev(v) = indev(v) + outdev(v)。注意:对于无向图,顶点的度等于该顶点的入度和出度,即dev(v) = indev(v) = outdev(v)。如上图中的G1每个顶点的度都为2。
上图中的G3中顶点1的出度为2,入度为1,顶点的度为3.
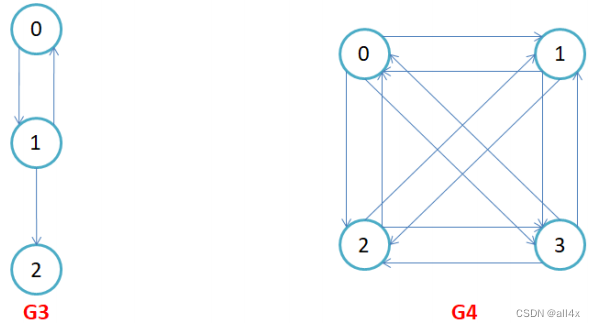
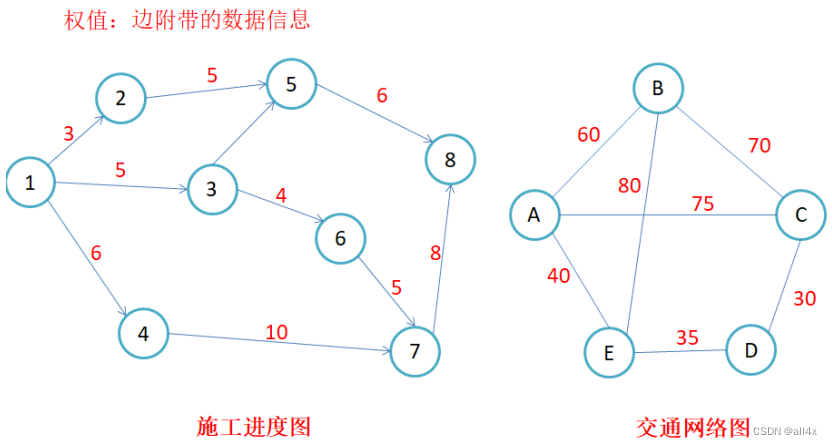
路径:若顶点A可以到达顶点B, 则从A到B经过的所有顶点就是A到B的路径. 对于不带权图,路径长度等于边数之和,带权图则是权值之和。如图。
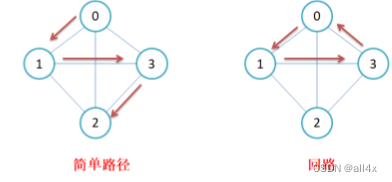
简单路径和回路:从图上的任一顶点出发,路径上经过的顶点只过一次,则为简单路径。
回路则是路径的上的出发点和结束点为同一个顶点形成一个环。如图。
子图:图2的顶点和边都是图1的一部分 ,则称图2是图1的子图。如图。

连通图:在无向图中,若两顶点间有边则称这两个边连通。若任意两个顶点都有边,则称为连通图。
强连通图:在有向图中,任意两个顶点间都有相连的边,并且顶点1有指向顶点2,顶点2也指向1。
生成树:一个无向连通图的最小连通子图称为改图的生成树。n个顶点的连通图的生成树有n-1条边。
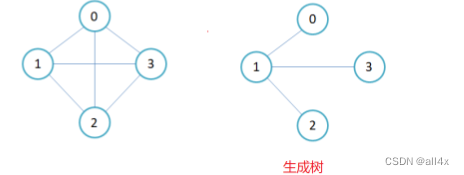
4.图的存储结构
图的存储结构有两种:1.邻接矩阵 2.邻接表
4.1邻接矩阵
邻接矩阵用以判断顶点间是否连通,用0来表示连通,1来表示不连通。
因此,我们用二维数组来实现邻接矩阵,表示两点是否连接。
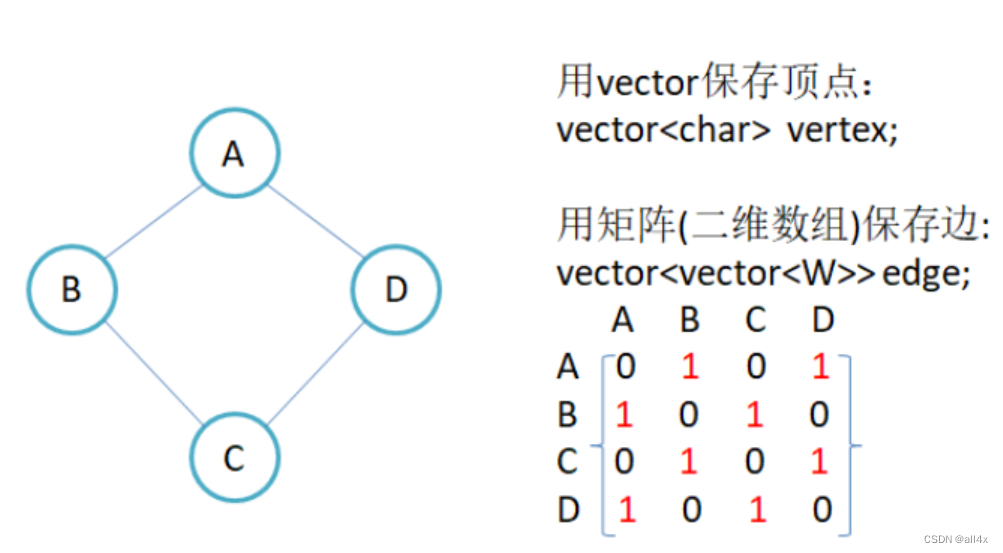
如上图,对于无向图,矩阵是对称的。因为,A对于B是连通的,B对于A也是连通的。
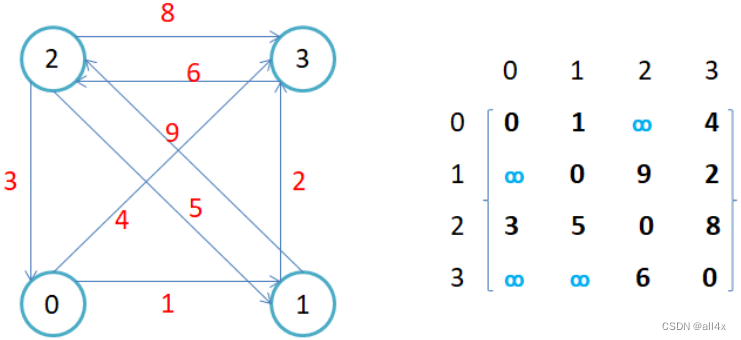
对于有向图而言,如图,二维数组的行表示边是由该顶点出发,而列则为被指向的顶点。

若图中的边带有权值,则在二维矩阵中用无穷大来表示两顶点间无边即不连通。
4.2邻接表
邻接表:用数组表示顶点的集合,用链表表示边的关系。
无向图的邻接表
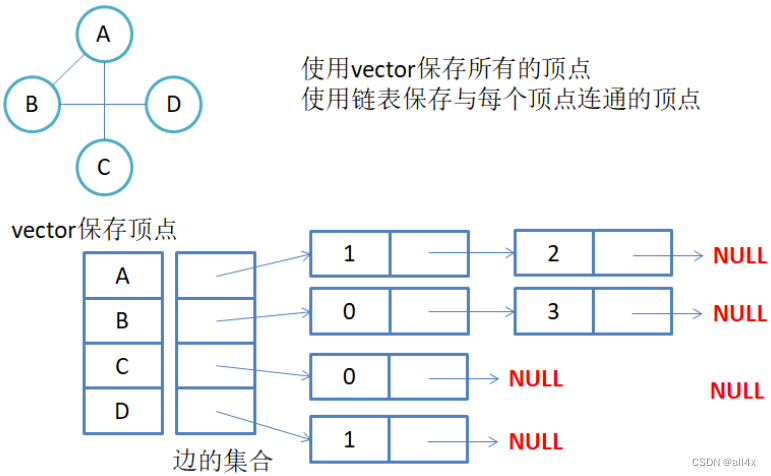
假设顶点A,B,C,D 的下标为0,1,2,3。与A连通的有B,C。所以在邻接表中,A指向B,C。
有向图的邻接矩阵
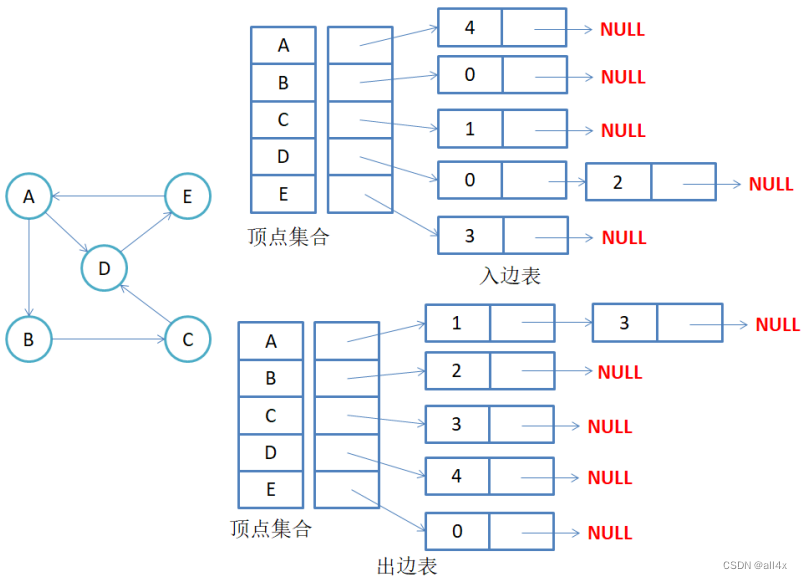
有向图的邻接表中包含有入边表和出边表。以A为例,顶点E指向A因此在入边表中A连接E的下标4。在出边表中,由于从A出的边指向B和D,所以出边表指向B和D的下标1,3。
4.3两种存储方式的对比
而邻接表的优点是很快能判断出一个顶点与哪些顶点直接相连. 而邻接表想要知道两个顶点是否连通,要比邻接矩阵要麻烦。
用邻接矩阵存储图的有点是能够快速知道两个顶点是否连通,缺陷是如果顶点比较多,边比较少时,矩阵中存储了大量的0成为系数矩阵,比较浪费空间,并且要求两个节点之间的路径不是很好求。
5.图的存储实现
首先,和学习其他数据结构一样。我们先来实现图的基本框架。上代码。
template<class V,class W,W MAX_W=INT_MAX,bool Direction=false>//V表示顶点的类型 W表示边的类型,MAX_W作为二维数组的初始值
class Graph {
piblic:Graph(const V* a, size_t n){_vertrx.resize(n);//为顶点集合开辟空间for (int i = 0; i < n; i++){_vertex.push(a[i]);//将数组中的值写入集合_indexMap[a[i]] = i;//顶点值和顶点下标的映射}_edge.resize(n);//为边的集合开辟空间for (int i = 0; i < n; i++){_edge[i].resize(n, MAX_W);}}
private:vector<v> _vertex;//存储顶点的集合vector<vector<w>>edge;//存储边的集合map<v, w>_indexMap;//存储顶点和其映射
};5.1邻接矩阵的实现
namespace martix {template<class V, class W, W MAX_W = INT_MAX, bool Direction = false>class Graph {public:Graph(const V* a, size_t n){_vertex.reserve(n);for (int i = 0; i < n; i++){_vertex.push_back(a[i]);_indeMap[a[i]] = i;}_edge.resize(n, MAX_W);}size_t GetIndex(const V& v){if (_indexMap.find(v) == _index.end())//map的特性,找不到时就等于end{cout << "要添加的顶点不存在" << endl;return -1;}return _index[v];}void AddEdge(const V& src, const V& dest, const W& w)//加边,依次为源点,目标点和边的权值{size_t srci = GetIndex(src);size_t desti = GetIndex(dest);_edge[srci][desti] = w;//边的权值if (Direction = false){_edge[desti][srci] = w;//无向图,矩阵是对称的}void print(){//打印顶点for (int i = 0; i < _edge.size(); i++)cout << "[" << i << "]" << "->" << _vertex[i] << endl;cout << endl;//打印矩阵for (int i = 0; i < _edge.size(); i++)//横坐标{for (int j = 0; i < _edge[i]).size(); j++)//纵坐标{if (_edge[i][j] = MAX_W)cout << "*";else {cout << _edge[i][j] << " ";}
}}cout << endl;}cout << endl;}};private:vector<V>_vertex;//顶点的集合vector<vector<w>> _edge;//边的集合map<v, w>_indexMap;}5.2邻接表的实现
namespace link_table{template<class W>//边的权值struct Edge {int _dsti;//目标点的下标W _w;Edge<W>* _next;Edge(int dsti, constW& w)//邻接表用链表的形式实现,因此是对每一个结点进行初始化:_dsti(dsti), _w(W), _next(nullptr){}};template<class V, class W, bool Direction = false>class Graph {typedef Edge<W> Edge;public:Graph(const V* a, size_t n){_vertex.reverse(n);//顶点集合开辟空间for (int i = 0; i < n; i++){_vertex.push_back(a[i]);_indexMap(a[i]) = i;}_tables.resize(m, nullptr);}size_t GetVertexIndex(const V& v){size_t it = _indexMap.find(v);if (it != _indexMap.end()){return it->second;//返回顶点集合映射的下标}else {return -1;}}void AddEdge(const V& src, const V& dst, const W& w){size_t srci = GetVertexIndex(src);sizet_t dsti = GetVertexIndex(dst);Edge* eg = new Edge(dsti, w);//对结点进行开辟eg->_next = _tables[srci];//头插的方式加入邻接表的新边,指向原来的头_tables[srci] = eg;//做新头if (Direction == false){Edge* eg = new Edge(srci, w);eg->_next;_tables[dsti];_tables[dsti] = edge;//做新头}}void Print(){for (size_t i = 0; i < _vertex.size(); i++){cout << "[" << i << "]" << "->" << _vertex[i] << endl;//下标对应的顶点}cout << endl;for (size_t i = 0; i < _tables.size(); i++){cout << _vertex[i] << "[" << i << "]" << "->";Edge* cur = _tables[i];while (cur)//和链表一样的遍历方式{cout << "[" << _vertexs[cur->_dsti] << ":" << cur->_dsti << ":" << cur->_w << "]->";cur = cur->_next;}}}private:vector<V>_vertex;//顶点的集合map<V, int>_indexMap;vector<Edge*>_tables;};}可以看到,邻接矩阵和邻接表在实现时的差别,邻接矩阵使用二维数组,而邻接表则使用的链表。
此外,在邻接表中插入新边时,我们使用的是头插的方式,因为这样可以免去找链表尾的操作。
6.总结
本篇文章,我们对图进行了基本的了解。在后续讲解图的相关算法时,我们将以邻接矩阵的存储方式的基本框架来分析。
这篇关于高阶数据结构[2]图的初相识的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








