本文主要是介绍Apache IoTDB进行IoT相关开发实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
当今社会,物联网技术的发展带来了许多繁琐的挑战,尤其是在数据库管理系统领域,比如实时整合海量数据、处理流中的事件以及处理数据的安全性。例如,应用于智能城市的基于物联网的交通传感器可以实时生成大量的交通数据。据估计,未来5年,物联网设备的数量将达数万亿。物联网产生大量的数据,包括流数据、时间序列数据、RFID数据、传感数据等。要有效地管理这些数据,就需要使用数据库。数据库在充分处理物联网数据方面扮演着非常重要的角色。因此,适当的数据库与适当的平台同等重要。由于物联网在世界上不同的环境中运行,选择合适的数据库变得非常重要。
原创文字,IoTDB 社区可进行使用与传播
一、什么是IoTDB
我先来给大家简单介绍一下:
IoTDB即物联网数据库,是一个面向时间序列数据的集成数据管理引擎,可以为用户提供特定的数据收集、存储和分析服务。由于其轻量级结构、高性能和可用特性,以及与Hadoop和Spark ecology的紧密集成,IoTDB满足了物联网工业领域的海量数据集存储、高速数据输入和复杂数据分析的要求。
二、IoTDB的体系结构
IoTDB套件可以提供真实情况下的数据采集、数据写入、数据存储、数据查询、数据可视化和数据分析等一系列功能,下图显示了IoTDB套件的所有组件带来的整体应用程序架构。

如图所示,咱们广大用户可以使用JDBC将设备上传感器收集的时间序列数据导入本地/远程IoTDB。这些时间序列数据可以是系统状态数据(如服务器负载和CPU内存等)。消息队列数据、来自应用程序的时间序列数据或数据库中的其他时间序列数据。用户也可以将数据直接写入TsFile(本地或HDFS)。对于写入IoTDB和本地TsFile的数据,大家可以使用TsFileSync工具将TsFile同步到HDFS,从而在Hadoop或Spark数据处理平台上实现异常检测、机器学习等数据处理任务。对于写入HDFS或本地TsFile的数据,用户可以使用TsFile-Hadoop-Connector或TsFile-Spark-Connector来允许Hadoop或Spark处理数据。分析的结果可以用同样的方式写回TsFile。
还有,IoTDB和TsFile提供了客户端工具,完全可以满足用户以SQL形式、脚本形式和图形形式编写和查看数据的各种需求。
三、IoTDB的文件类型
在IoTDB中,需要存储的数据种类繁多。现在我来给大家介绍IoTDB的数据存储策略,方便大家对IoTDB的数据管理有一个直观的了解。
首先呢,IoTDB存储的数据分为三类,即数据文件、系统文件和预写日志文件。
(1)数据文件
数据文件存储用户写入IoTDB的所有数据,IoTDB包含TsFile和其他文件。TsFile存储目录可以用data_dirs来配置相关项目,其他文件通过其他特定的数据来配置项目。
为了更好地支持用户的磁盘空间扩展等存储需求,IoTDB支持多种文件目录存储方式进行TsFile存储配置。用户可以将多个存储路径设置为数据存储位置,大家可以指定或自定义目录选择策略。
(2)系统文件
系统文件包括模式文件,模式文件存储IoTDB中数据的元数据信息。它可以通过配置base_dir配置项目。
(3)预写日志文件
预写日志文件存储WAL文件。它可以通过配置wal_dir配置项目。
(4)设置数据存储目录的示例
为了更清楚地理解配置数据存储目录,我在这给出一个示例。
存储目录设置中涉及的所有数据目录路径有:base_dir、data_dirs、multi_dir_strategy、wal_dir,分别指系统文件、数据文件夹、存储策略、预写日志文件。
配置项的示例如下:
base_dir = $IOTDB_HOME/data
data_dirs = /data1/data, /data2/data, /data3/data
multi_dir_strategy=MaxDiskUsableSpaceFirstStrategy
wal_dir= $IOTDB_HOME/data/wal这段代码并不复杂,相信很多小伙伴都应该可以看懂,我在这里给大家简单说明一下下,设置以上配置后,系统将:
-
将所有系统文件保存在$io TDB _ HOME/data中
将TsFile保存在/data1/data、/data2/data、/data3/data中。选择策略是MaxDiskUsableSpaceFirstStrategy,即每次数据写入磁盘时,系统会自动选择剩余磁盘空间最大的目录来写入数据。
将WAL数据保存在$IOTDB_HOME/data/wal中
四、InfluxDB 协议适配器开发
1、引入依赖
<dependency><groupId>org.apache.iotdb</groupId><artifactId>influxdb-protocol</artifactId><version>1.0.0</version></dependency>这里是一些使用 InfluxDB-Protocol 适配器连接 IoTDB 的示例open in new window。
2、切换方案
假如您原先接入 InfluxDB 的业务代码如下:
InfluxDB influxDB = InfluxDBFactory.connect(openurl, username, password);您只需要将 InfluxDBFactory 替换为 IoTDBInfluxDBFactory 即可实现业务向 IoTDB 的切换:
InfluxDB influxDB = IoTDBInfluxDBFactory.connect(openurl, username, password);3、方案设计
3.1 InfluxDB-Protocol适配器
该适配器以 IoTDB Java ServiceProvider 接口为底层基础,实现了 InfluxDB 的 Java 接口 interface InfluxDB,对用户提供了所有 InfluxDB 的接口方法,最终用户可以无感知地使用 InfluxDB 协议向 IoTDB 发起写入和读取请求。

architecture-design

class-diagram
3.2 元数据格式转换
InfluxDB 的元数据是 tag-field 模型,IoTDB 的元数据是树形模型。为了使适配器能够兼容 InfluxDB 协议,需要把 InfluxDB 的元数据模型转换成 IoTDB 的元数据模型。
3.2.1 InfluxDB 元数据
-
database: 数据库名。
measurement: 测量指标名。
tags : 各种有索引的属性。
fields : 各种记录值(没有索引的属性)。

influxdb-data
3.2.2 IoTDB 元数据
-
database: 数据库。
path(time series ID):存储路径。
measurement: 物理量。
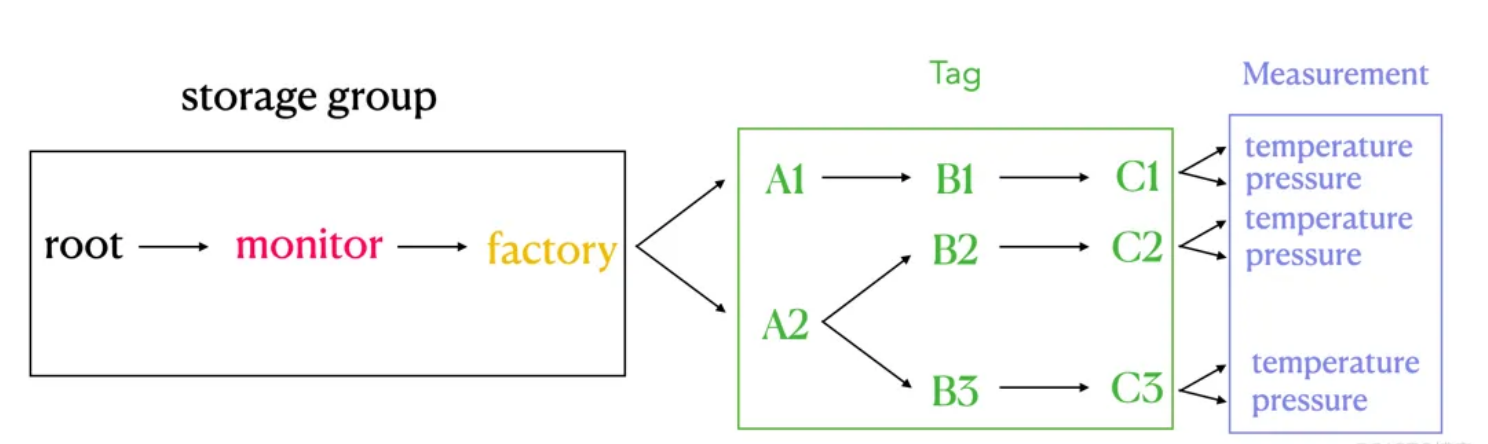
iotdb-data
3.2.3 两者映射关系
InfluxDB 元数据和 IoTDB 元数据有着如下的映射关系:
-
InfluxDB 中的 database 和 measurement 组合起来作为 IoTDB 中的 database。
InfluxDB 中的 field key 作为 IoTDB 中 measurement 路径,InfluxDB 中的 field value 即是该路径下记录的测点值。
InfluxDB 中的 tag 在 IoTDB 中使用 database 和 measurement 之间的路径表达。InfluxDB 的 tag key 由 database 和 measurement 之间路径的顺序隐式表达,tag value 记录为对应顺序的路径的名称。
InfluxDB 元数据向 IoTDB 元数据的转换关系可以由下面的公示表示:
root.{database}.{measurement}.{tag value 1}.{tag value 2}...{tag value N-1}.{tag value N}.{field key}

influxdb-vs-iotdb-data
如上图所示,可以看出:
我们在 IoTDB 中使用 database 和 measurement 之间的路径来表达 InfluxDB tag 的概念,也就是图中右侧绿色方框的部分。
database 和 measurement 之间的每一层都代表一个 tag。如果 tag key 的数量为 N,那么 database 和 measurement 之间的路径的层数就是 N。我们对 database 和 measurement 之间的每一层进行顺序编号,每一个序号都和一个 tag key 一一对应。同时,我们使用 database 和 measurement 之间每一层 路径的名字 来记 tag value,tag key 可以通过自身的序号找到对应路径层级下的 tag value.
五、支持情况
5.1 InfluxDB版本支持情况
目前支持InfluxDB 1.x 版本,暂不支持InfluxDB 2.x 版本。
influxdb-java的maven依赖支持2.21+,低版本未进行测试。
5.2 函数接口支持情况
目前支持的接口函数如下:
public Pong ping();public String version();public void flush();public void close();public InfluxDB setDatabase(final String database);public QueryResult query(final Query query);public void write(final Point point);public void write(final String records);public void write(final List<String> records);public void write(final String database,final String retentionPolicy,final Point point);public void write(final int udpPort,final Point point);public void write(final BatchPoints batchPoints);public void write(final String database,final String retentionPolicy,
final ConsistencyLevel consistency,final String records);public void write(final String database,final String retentionPolicy,
final ConsistencyLevel consistency,final TimeUnit precision,final String records);public void write(final String database,final String retentionPolicy,
final ConsistencyLevel consistency,final List<String> records);public void write(final String database,final String retentionPolicy,
final ConsistencyLevel consistency,final TimeUnit precision,final List<String> records);public void write(final int udpPort,final String records);public void write(final int udpPort,final List<String> records);5.3 查询语法支持情况
目前支持的查询sql语法为
SELECT <field_key>[, <field_key>, <tag_key>]
FROM <measurement_name>
WHERE <conditional_expression > [( AND | OR) <conditional_expression > [...]]WHERE子句在field,tag和timestamp上支持conditional_expressions.
field
field_key <operator> ['string' | boolean | float | integer]tag
tag_key <operator> ['tag_value']timestamp
timestamp <operator> ['time']目前timestamp的过滤条件只支持now()有关表达式,如:now()-7D,具体的时间戳暂不支持。
六、总结
IoTDB作为一款专门针对时序数据设计的数据库,以其高性能、高压缩比、多协议兼容等特性,在物联网领域得到了广泛的应用。通过对IoTDB的详细介绍和使用方法的阐述,相信读者已经对IoTDB有了深入的了解。在未来的物联网应用中,IoTDB将继续发挥其在时序数据管理方面的优势,为物联网技术的发展和应用提供有力的支持。
这篇关于Apache IoTDB进行IoT相关开发实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








