本文主要是介绍使用消息队列(MQ)实现MySQL持久化存储与MySQL server has gone away问题解决,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在现代应用程序开发中,消息队列(MQ)扮演着重要的角色。它们可以帮助我们解决异步通信和解耦系统组件之间的依赖关系。而其中一个常见的需求是将消息队列中的数据持久化到数据库中,以确保数据的安全性和可靠性。在本文中,我们将探讨如何使用MQ将消息持久化存储到MySQL数据库。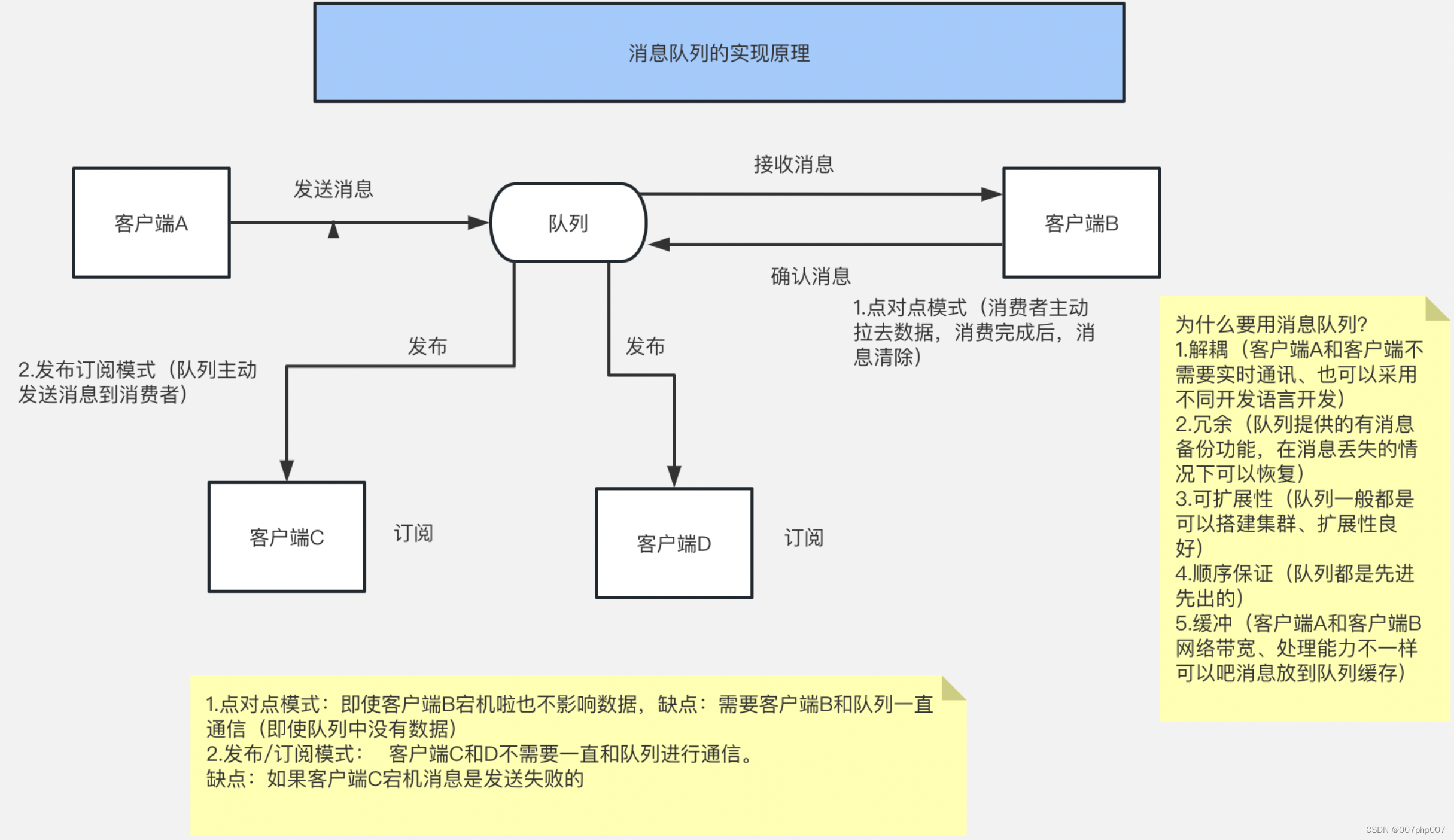
一、介绍消息队列(MQ)和MySQL数据库
首先,让我们简要了解消息队列和MySQL数据库的基本概念。
消息队列是一种允许应用程序之间异步通信的中间件。它通过将消息发送到队列中,然后由消费者从队列中获取并处理这些消息。消息队列有助于解耦不同组件之间的通信,提高系统的可伸缩性和可维护性。
MySQL是一种流行的关系型数据库管理系统(RDBMS),被广泛用于存储和管理结构化数据。它提供了可靠的事务支持和高性能的查询功能。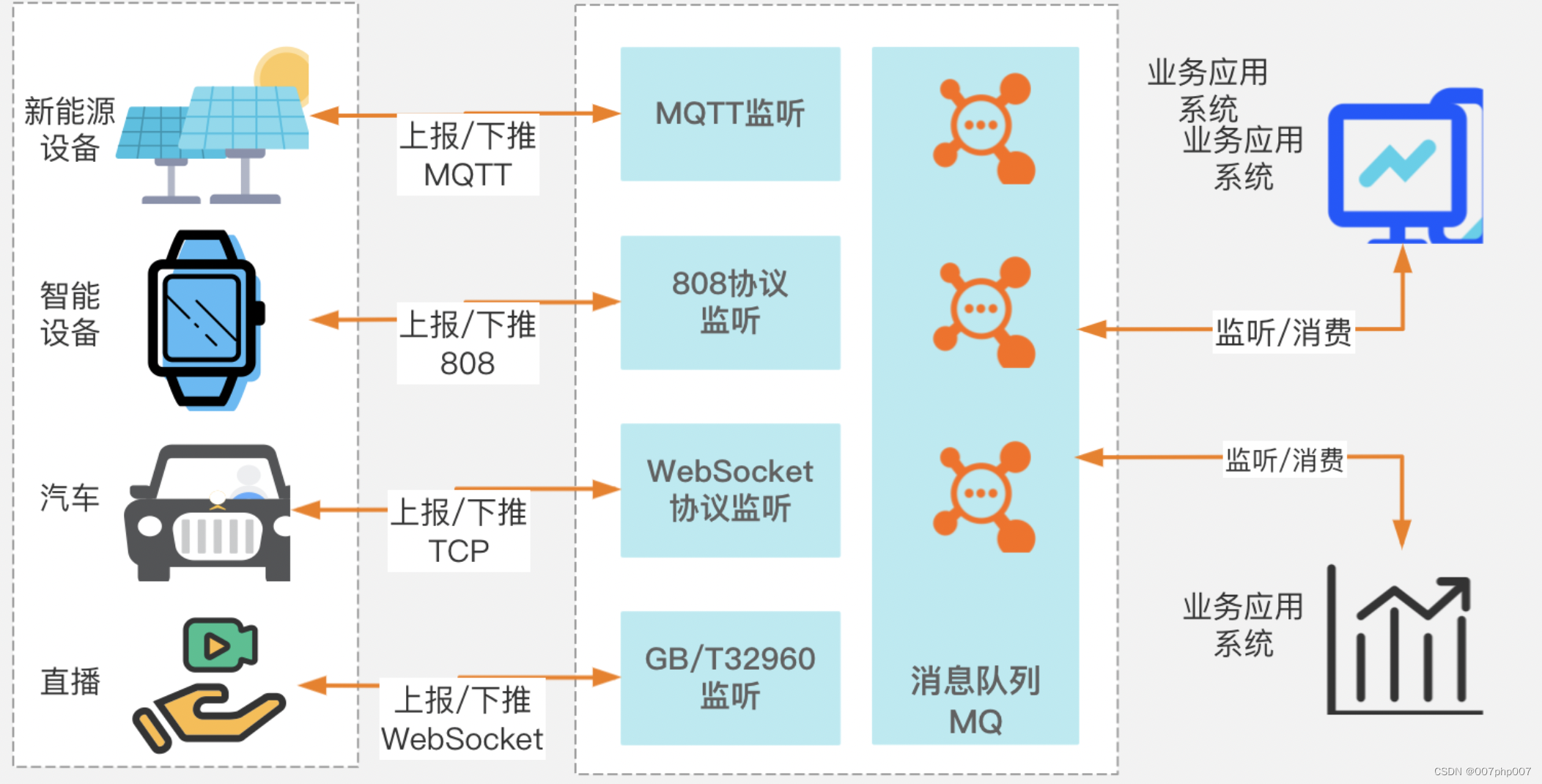
二、为什么需要将消息队列持久化到MySQL
将消息队列中的数据持久化到MySQL数据库有以下几个优势:
1. 数据安全性:通过将消息存储到MySQL数据库中,可以确保数据不会因应用程序或服务器故障而丢失。
2. 数据可靠性:通过将消息队列中的数据存储到MySQL数据库中,可以确保消息被可靠地处理和传递给消费者。
3. 数据分析:将消息队列的数据存储到MySQL数据库中,可以方便地进行数据分析和报表生成。
三、如何实现消息队列持久化到MySQL
下面是实现将消息队列持久化到MySQL的一般步骤:
1. 创建数据库表:首先,在MySQL数据库中创建一个用于存储消息的表。表的结构应该包含消息的内容、发送时间、状态等字段。
2. 配置MQ和数据库连接:在应用程序中配置MQ和MySQL数据库的连接信息。确保应用程序能够同时连接到MQ和数据库。
3. 发送消息:当需要发送消息时,将消息发送到MQ的队列中。
4. 消息消费:编写一个消费者程序,从MQ的队列中获取消息,并将消息存储到MySQL数据库中。
5. 消息确认:在成功将消息存储到数据库后,向MQ发送消息确认,告知MQ消息已被处理。
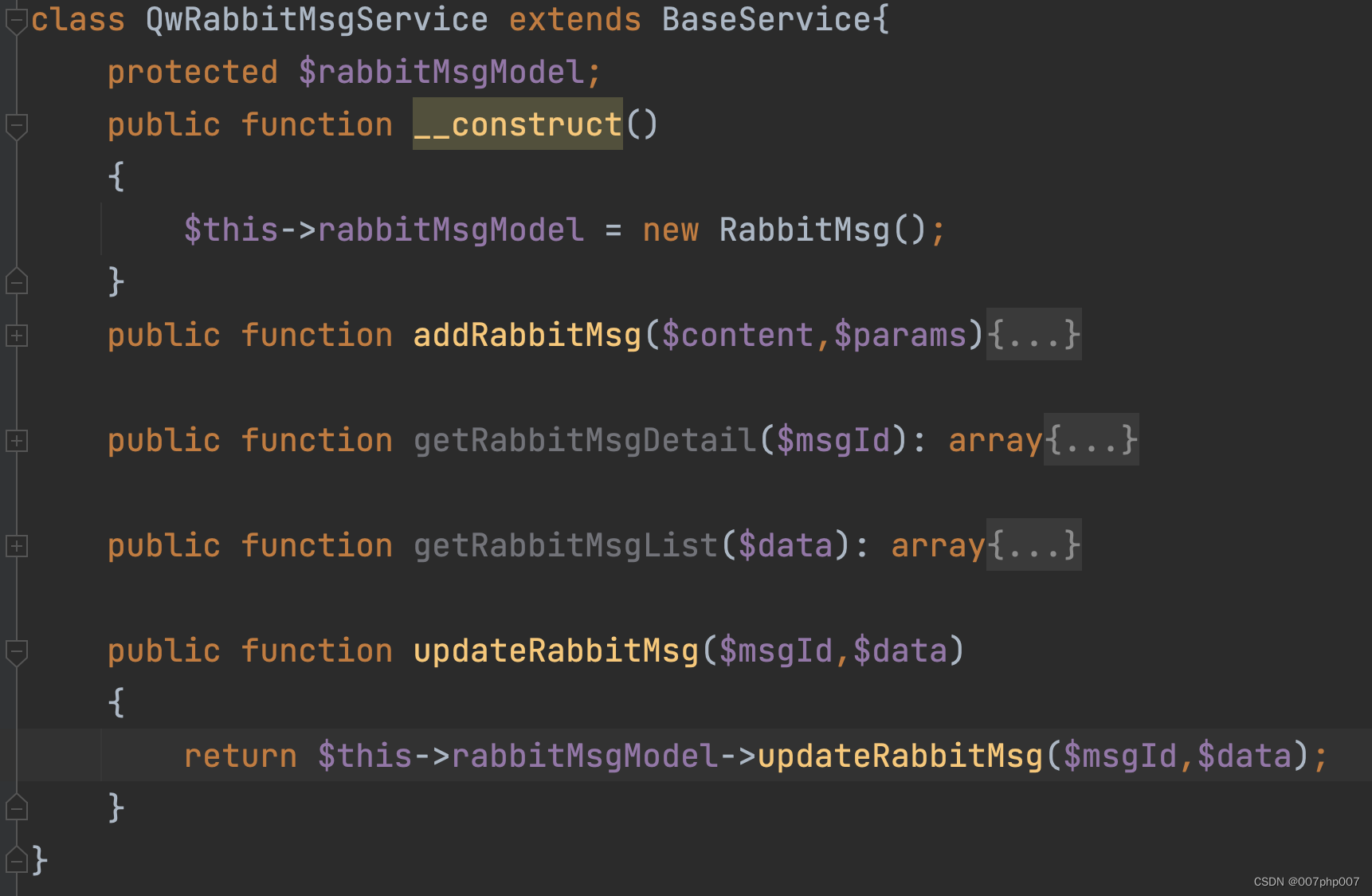
6. 错误处理:处理可能出现的错误情况,例如数据库连接失败或消息处理失败错误如下;
General error: 2006 MySQL server has gone away
代码如下
优化如下:构造方法引入父类的构造方法
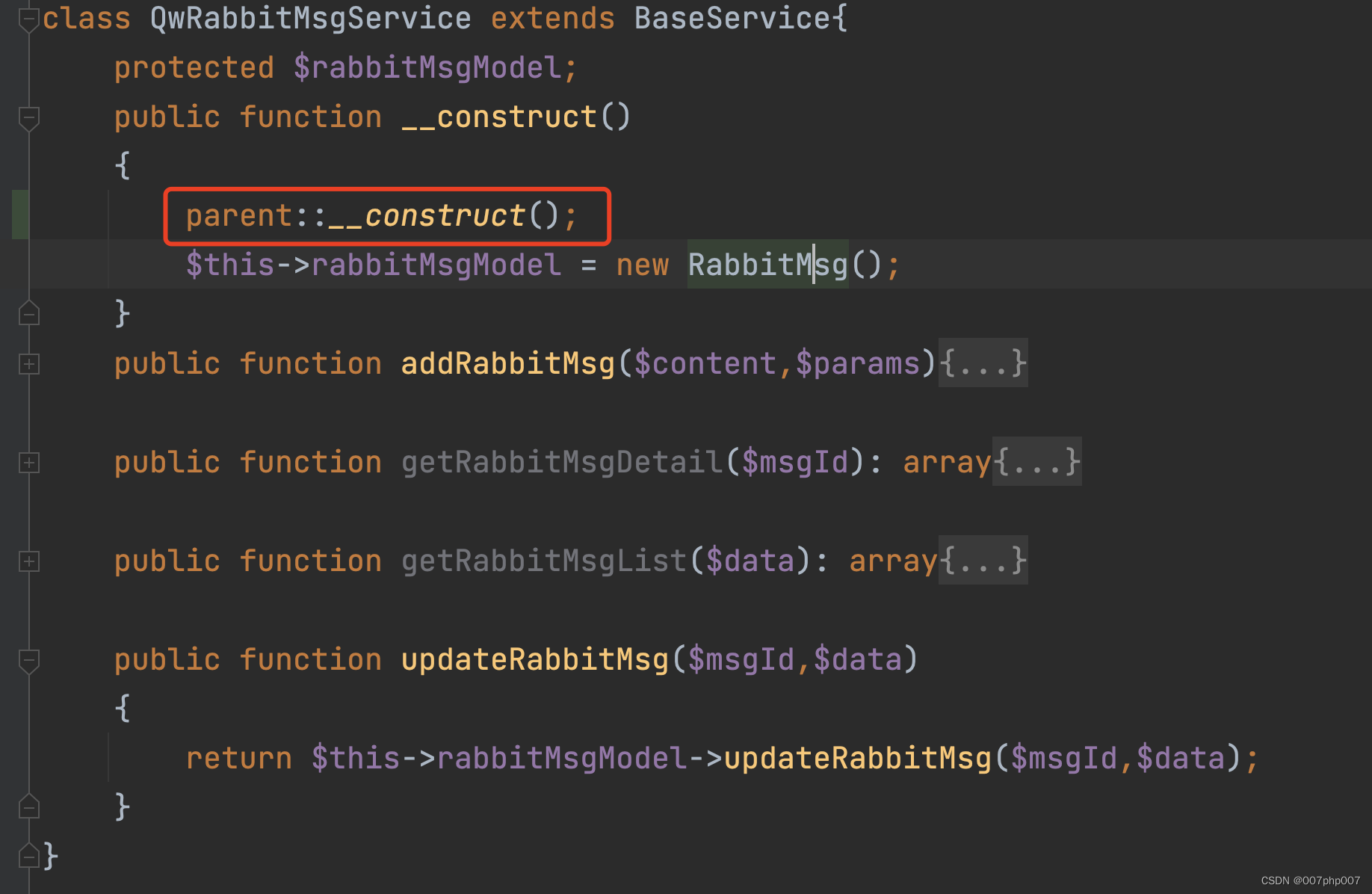
解决问题后获取数据如下

四、总结
通过使用消息队列(MQ)将消息持久化存储到MySQL数据库,我们可以提高系统的可靠性和可维护性。通过将数据存储到数据库中,我们可以确保数据的安全性,并方便地进行数据分析和报表生成。请记住,在实际应用中,根据具体需求和技术栈的不同,可能需要进行额外的配置和调整。
希望本文能够帮助你理解如何使用MQ实现MySQL持久化存储,欢迎留言和分享你的想法。感谢阅读!
这篇关于使用消息队列(MQ)实现MySQL持久化存储与MySQL server has gone away问题解决的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




