本文主要是介绍零代码本地搭建AI大模型,详细教程!普通电脑也能流畅运行,中文回答速度快,回答质量高,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这篇教程主要解决:
1). 有些读者朋友,电脑配置不高,比如电脑没有配置GPU显卡,还想在本地使用AI;
2). Llama3回答中文问题欠佳,想安装一个回答中文问题更强的AI大模型。
3). 想成为AI开发者,开发一款AI大模型的应用和产品,如何选择API的问题。
我相信,大家平时主要还是以中文问答为主,安装一个中文回答更强的AI,就显得更很有必要。
这篇教程主要解决上面两个问题。
1 通义千问大模型的优势
近日阿里云正式发布通义千问2.5,模型性能全面赶超GPT-4 Turbo,成为地表最强中文大模型。

从初代模型升级至2.5版本,2.5版模型的理解能力、逻辑推理、代码能力分别提升9%、16%、10%,中文能力更是持续领先业界。
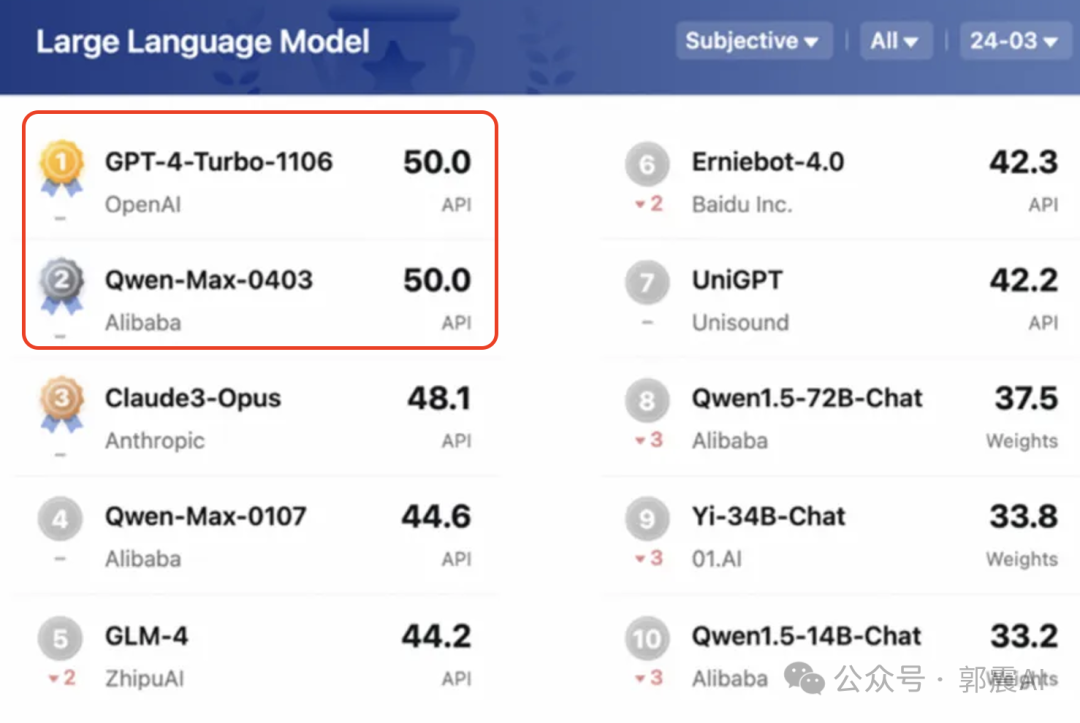
通义千问2.5相对于前代版本还有以下几方面的重大升级:
-
文档处理能力增强:通义千问2.5能够处理单次长达1000万字、100个文档的大量数据,支持包括PDF、Word、Excel在内的多种文件格式,并能解析标题、段落、图表等多种数据结构。
-
音视频理解能力提升:融合了语音、大规模语言模型(LLM)、多模态和翻译能力,实现了实时语音识别、说话人分离,能够从音视频内容中提取全文摘要、总结发言要点、提取关键词,同时支持同时上传处理50个音视频文件。
-
智能编码能力集成:集成通义灵码,使得用户能够在移动设备上编写、阅读代码及学习编程技能,进一步提升了代码相关的交互和处理能力。
因此,如果你的日常以中文回复为主,在本地搭建一个通义千问用于回复中文问题,是最好的选择。并且,通义千问****开源免费,在自己电脑可以直接搭建一个,使用起来非常方便。再看看通义****千问回答问题的速度,很快:
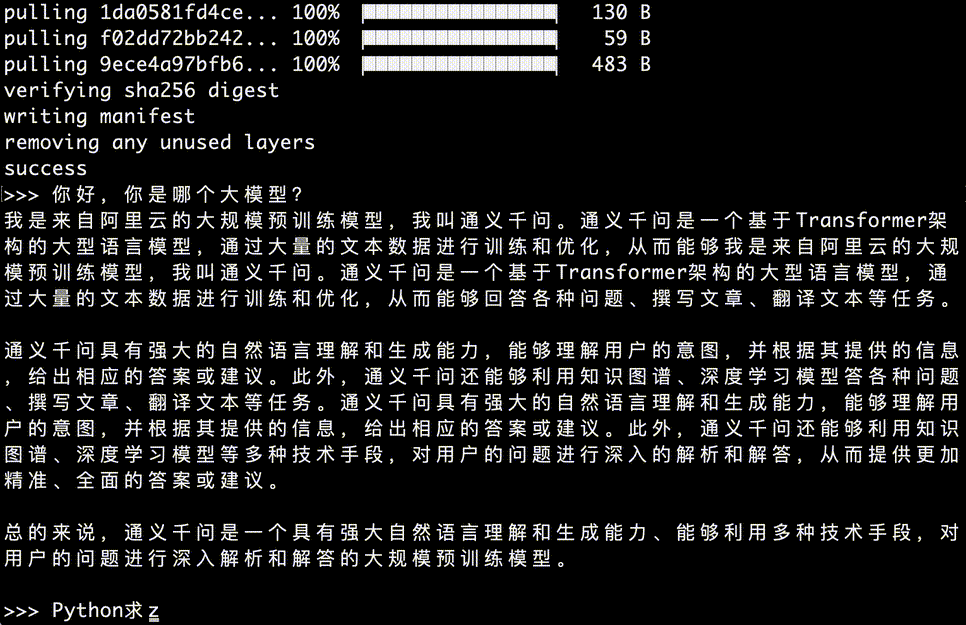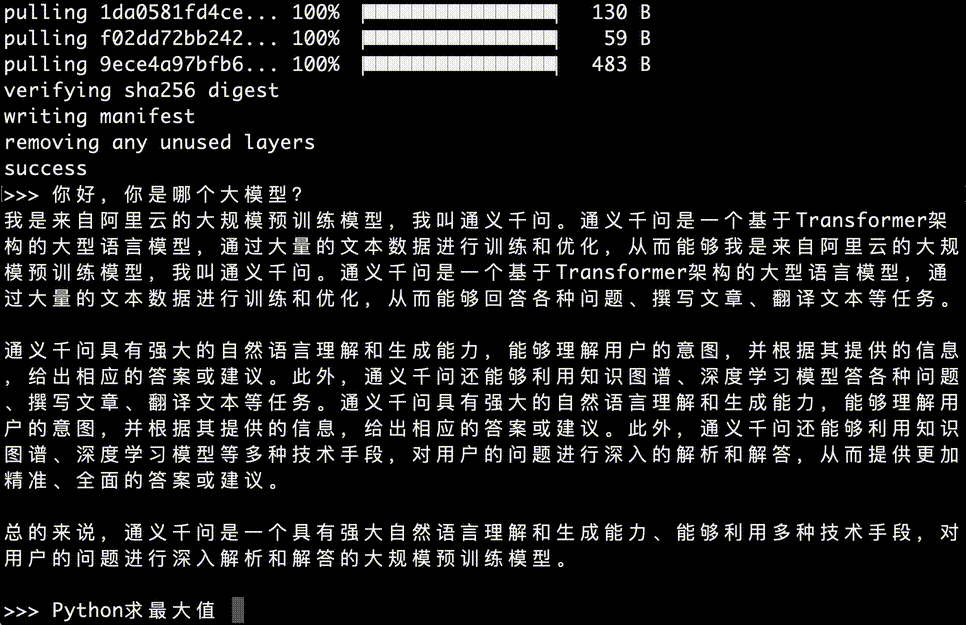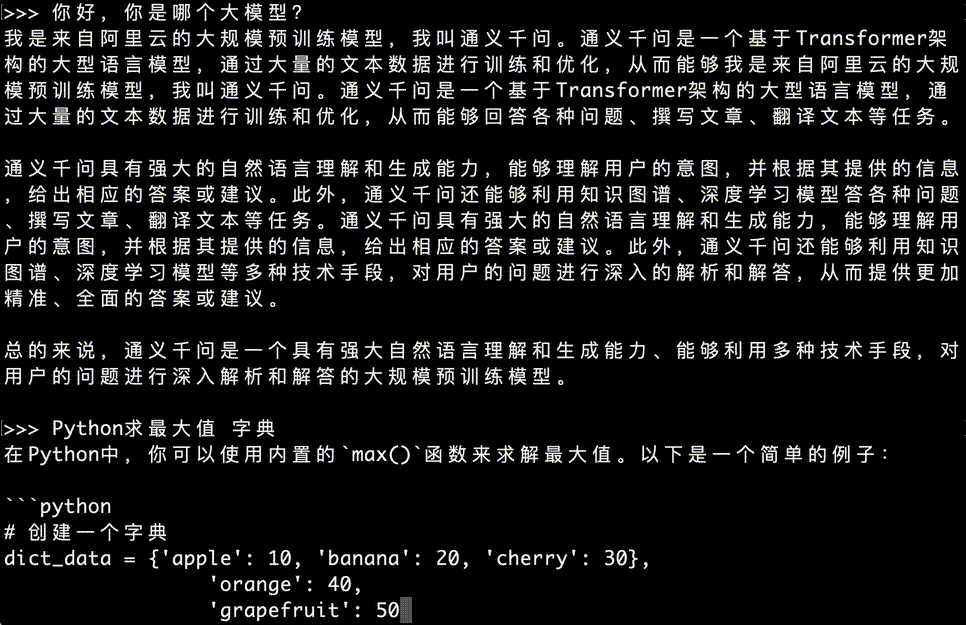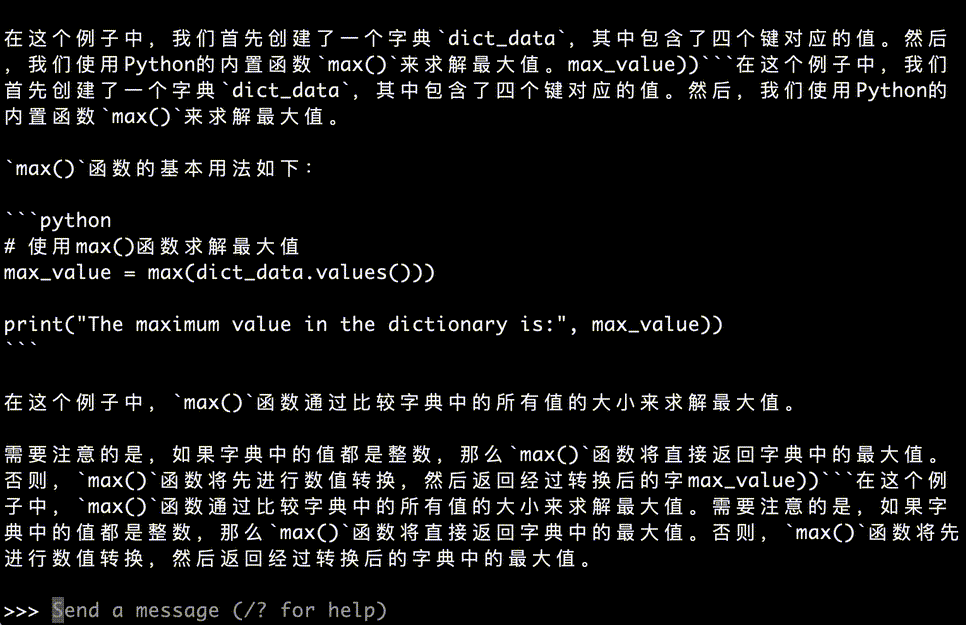
如果,你想更友好的使用通义千万,这篇教程还会帮助你,搭建一个前端网站,零代码,按照教程逐步搭建好,使用通义千问,就更加方便,下面是带界面问答使用效果:

因为阿里通义千问是在本地运行,数据安全,并且开源免费,不用花钱充值买流量,开箱即用,良心好用。
2 下载通义千问大模型
推荐使用ollama工具,一行命令就能下载千问。
千问尺寸提供多种,如果你的电脑配置一般,比如是5年前的电脑,可以安装一个小尺寸的,从下面的尺寸列表中:
- ollama run qwen:0.5b
- ollama run qwen:1.8b
- ollama run qwen:4b
- ollama run qwen:7b
下面,已安装1.8b尺寸为例演示:
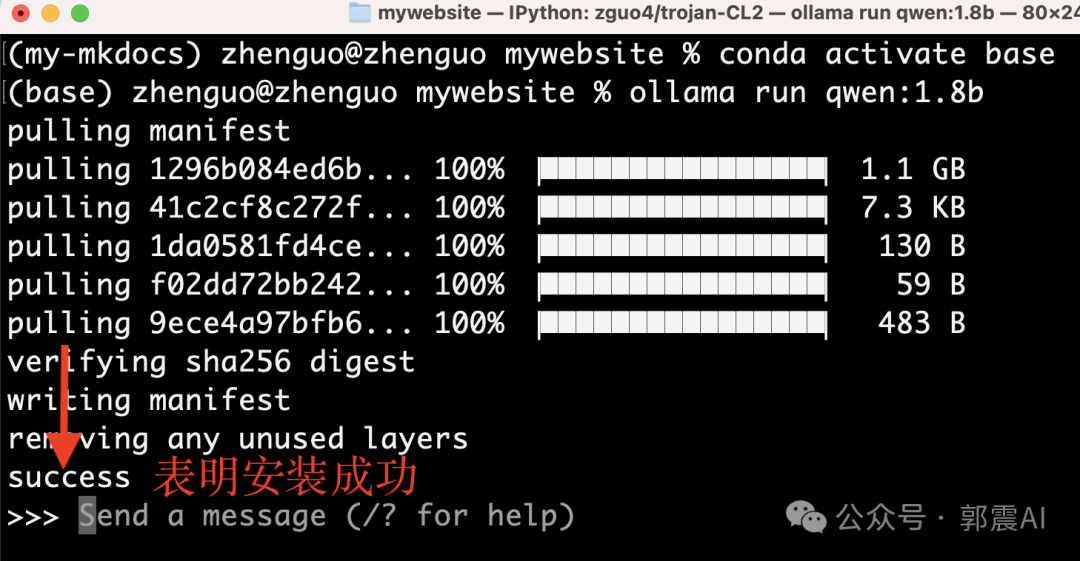
第一步,执行下面一行命令:

下面就开始安装,看到这个模型只有1.1G大小:

出现success,表明安装成功:
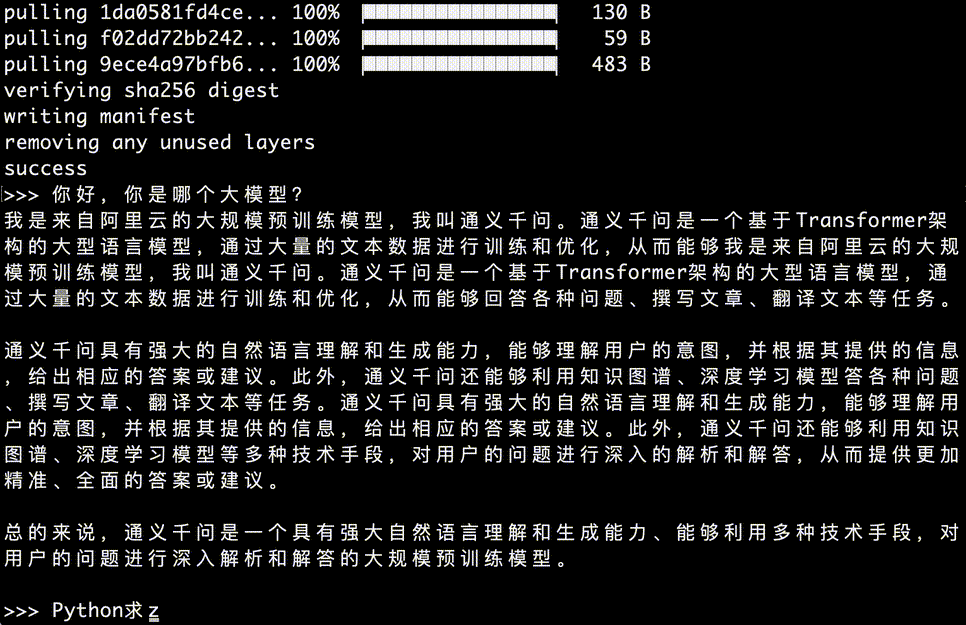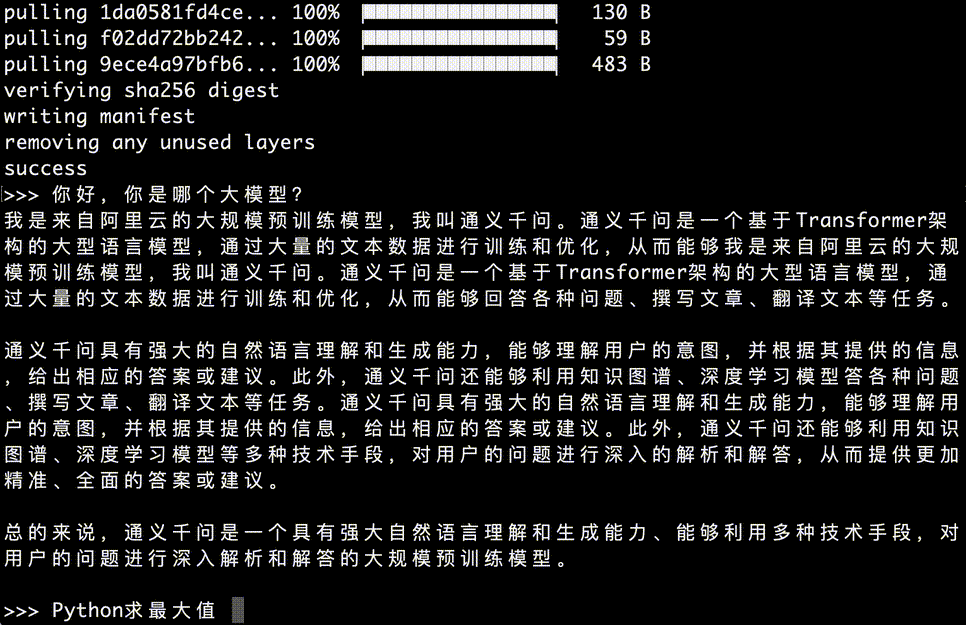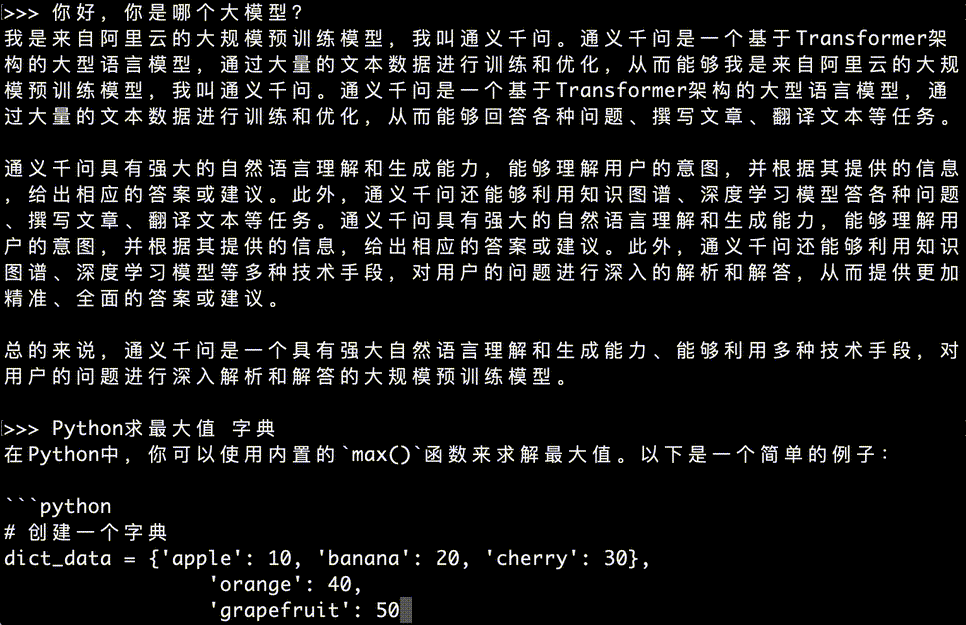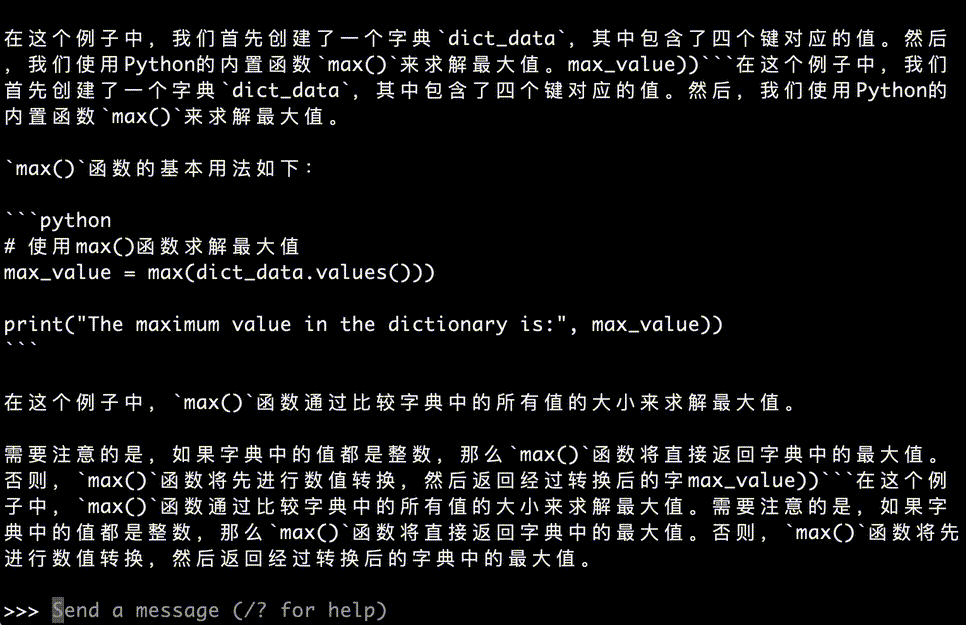
接下来,就直接可以提问通义千问,如下图所示:

AI时代,很多读者都想学习一点编程,下面我们提问它文章开头的那个问题,下面是GIF演示,回答很快,回答中文是真的好,用过llama3的读者有体会,每次提问后缀都要带上:请用中文回答,但是通义千问就不需要,对中文支持更好。
3 前端网页配置
第一步,安装docker。
第二步,docker拉取lobe镜像,无论windows还是mac,都是打开命令窗口,输入下面命令:

这条命令用于从 Docker Hub 上拉取最新的 lobehub/lobe-chat 镜像。
执行这条命令后,Docker 会将 lobehub/lobe-chat 镜像的最新版本下载到你的本地系统,以便你可以使用它创建和运行 Docker 容器。
第三步,再运行一条命令就可以了:

解释下这条命令,不想看的读者直接跳过:docker run:启动并运行一个新的 Docker 容器。-d:在后台(守护进程模式)运行容器,不会占用当前终端。–name lobe-chat:给容器分配一个名称 lobe-chat。这有助于以后通过名称管理容器。-p 10084:3210:将主机的 10084 端口映射到容器的 3210 端口。这样,主机的 10084 端口的请求会被转发到容器的 3210 端口。-e ACCESS_CODE=lobe66:设置环境变量 ACCESS_CODE 的值为 lobe66,这通常是用于在容器内配置应用程序的参数。
这时,你再访问网页:http://localhost:10084,就会进入到AI网站界面,选择千问的英文字符:qwen,配置一下就可以畅享使用了。
4 通义千问应用案例
1)生成同意词汇:

答案部分截图
2)AI学习辅助:

答案部分截图
3)编程变量命名辅助:

答案部分截图
4)通义千问中还内置效率利器,比如下面都能帮助我们很大提升效率:

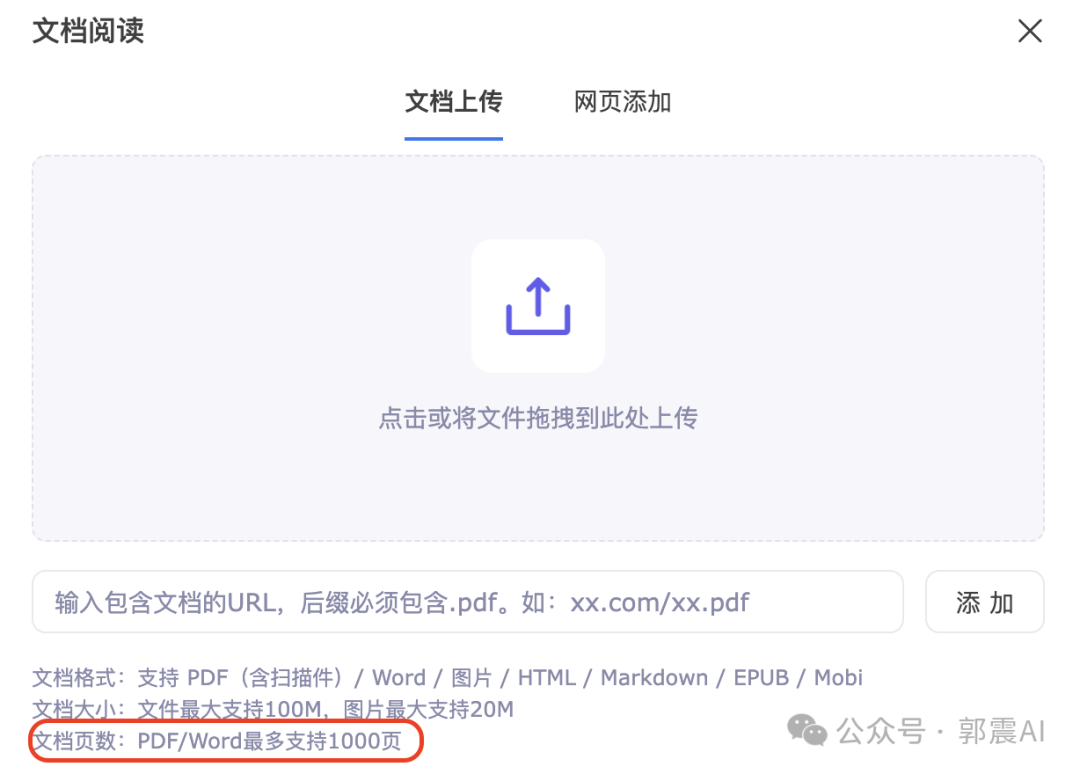
下面是文档阅读,支持多种格式的文件上传,1000页的PDF可以直接上传,真的太强:
5 个人开发者调用通义千问费用对比
上面我们介绍了本地搭建千问大模型步骤,这个小节面向AI个人开发者,什么意思呢,就是说你如果想基于千问AI做一个产品、app、网站或桌面软件,那么这个小节就对你很有帮助。选择通义千问,就是一个很好的选择。在5月21日,阿里云宣布通义千问9款模型齐降价,其中GPT-4级主力模型Qwen-Long,API输入价格从0.02元/千tokens降至0.0005元/千tokens,直降97%,这款模型最高支持1千万tokens长文本输入,降价后约为GPT-4价格的1/400。
千问API模型,最高支持1千万tokens,这是一个什么概念?我给大家打个比方。一本书的长度可以用token来衡量。例如:普通小说:平均每页大约有250-300个单词。假设每个单词平均为1.2个token(考虑到标点符号和分词),那么我们可以得到以下估算:普通小说(50,000个单词)大约为60,000个tokens。现在我们来计算一下1千万tokens相当于多少本书:普通小说:1千万tokens / 60,000 tokens/本 ≈ 167本书
也就是说一次提问Qwen-Long一次可处理167本书,这个有点吓人。通过API调用无须购买任何硬件成本、电力成本、材料消耗等成本,问题来了,有的读者如果坚持要本地自建这样的AI模型,需要投入多少成本呢?
我们来算笔账。以一般规模Qwen-7b、一般用户(每天满载4小时,闲置20小时)为例,前期硬件投入成本:总成本:3万元(其中GPU成本2万元,其余硬件成本1万元):硬件折旧费用::625元,网络费用:200元,自建服务器每月综合成本:897元(36元电费 + 625元硬件折旧 + 200元网络费用)

而使用千问API,也就是百炼平台,方案的对比成本:Qwen 7b的使用成本如下:输入:1元/100W tokens,输出:1元/50W tokens,每月tokens消耗和成本:百炼成本:194.4元,约为自建成本的22.5%,也就是节省了80%的费用。
大家注意,这个还只是7b,那么如果是Long模型,本地自建的成本可能远超3万元,自建成本就更高了,更能凸显通过调用百炼API的成本节省以及它的价值。
并且,调用API是按需付费,不像自建AI需要前期固定几万的投入。所以,各个角度来看,如果你打算基于AI做应用和产品,通过调用百炼API才是首选,而不是自建AI。
如果你是创业者,开公司的老板,走千问API更是一种好的选择。
更多千万API应用大家可以去百炼平台探索,希望通过这个教程帮助你解决了:电脑配置不高,比如电脑没有配置GPU显卡,还想在本地使用AI;想安装一个回答中文问题更强的AI大模型;AI开发者基于千问API与自建AI成本对比。如需要体验通义千问API,可以访问百炼官网:https://www.aliyun.com/product/bailian?spm=5176.29250174.0.0
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。
这篇关于零代码本地搭建AI大模型,详细教程!普通电脑也能流畅运行,中文回答速度快,回答质量高的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





