本文主要是介绍【论文笔记】The Dilemma between Deduplication and Locality: Can Both be Achieved?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
代码:https://github.com/Borelset/MFDedup/
演讲:https://www.youtube.com/watch?v=3oozoXYE9SQ
目录
论文总结
论文详读
0. Abstract
1. Introduction
2. Background
2.1 Background of Data Deduplication
2.2 Deduplication Techniques
3. Observation and Motivation
3.1 Analysis for Fragmentation and Read Amplification after Deduplication
3.2 An Optimal Data Layout
3.3 Derivation Relationship of Backups
4. Design and Implementation
4.1 MFDedup Overview
4.2 Neighbor-Duplicate-Focus Indexing
4.3 Across-Version-Aware Reorganization
4.4 Restore and Garbage Collection
4.5 Discussion and Limitations
5. Performance Evaluation
5.1 experimental setup
5.2 Actual Deduplication Ratio
5.3 Backup Throughput
5.4 Restore Throughput
5.5 Arranging vs. Traditional GC
5.6 Size Distribution of Volumes/Categories
6. Conclusion and Future Work
论文总结
场景:基于HDD的全量备份存储
问题:目前全量备份的去重存在数据局部性问题(碎片),导致:
① Restore效率低:恢复backup时其中块引用之前存的块,需要随机来回访问磁盘,导致读放大和seek latency
② GC性能低:container中有引用和未引用的块,移动引用的块需要大量块读写
现状:全局OPT布局不可行。
1. restore优化方法:写去重(Capping和HAR),Caching无法完全解决碎片问题。
① Capping: 记录container中被引用块的数量,低被引的container重写
② HAR:根据备份流相似性,结合历史信息识别sparse container,重写指向sparse container的块 (本方法重写最少)
2. GC方法:
① Mark-Sweep:未被引用的块清除,被引用的复制移动到新container,粒度太细,I/O紧张
② CMA:删除未被引用的container,粒度太粗,空间浪费
观察:
备份大量重复来自前一个版本:① 提出categories-变长container,其中所有块都有用,避免读放大;② Categories数量分析,原本很大 ③ 忽略unique块,降低categories数量
贡献:
设计OPT布局,比传统方法相比:管理友好、解决碎片问题(提升restore和GC性能)、离线算法代价可接受。
核心技术:
① NDF:检测新版本与前一版本的重复,减少索引内存占用
② AVAR:depulicating阶段:检测新版本中unique块(装入active categories);arranging阶段:对active categories,用NDF进行比对,一部分archive,一部分继续activate,更新OPT。restore简单,读顺序的volumes;GC简单,只需删最早的categories
效果:ADR和restore throughput高,fully utilize设备,NDF代价可接受,GC 0代价
论文详读
0. Abstract
数据去重被广泛用于减少备份工作负载backup workloads的大小,但是具有低数据局部性data locality的缺点,这个问题也被称为碎片问题fragmentation problem,从而导致较低的恢复restore和垃圾回收garbage collection性能。目前的研究包括写去重writing duplicates来维持局部性,以及在内存或SSD中缓存数据,但是碎片还是会降低restore与GC的性能。(背景问题介绍)
为了解决局部性问题,发现备份中大部分的重复块duplicate chunks来自之前的备份。因此提出了易于管理的去重框架MFDedup,利用数据分类方法来生成最优数据分布OPT data layout,从而维持备份工作负载的局部性。核心两个技术:NDF Neighbor-Duplicate-Focus indexing 和 AVAR Across-Version-Aware Reorganization,来进行先前备份的重复检测,利用离线迭代算法重新整理chunks,使其成为紧凑线性compact, sequential的布局,几乎能去除恢复时的随机I/O。(本文观察与方法)
实验使用4个备份数据集,本方法的去重率deduplication ratios和恢复吞吐效率restore throughputs都很优秀,Arranging重组织阶段引入了额外消耗,但是more than offset by a nearly-zero overhead GC过程。NDF只需要索引两个备份版本,而传统的索引随着保存的版本增加而增加。(实验效果及优点)
1. Introduction
数据去重是目前备份系统重要的技术,去重率deduplication ratio (the logical size divided by the post deduplication size)通常在10~30。基本的去重方法是把重复块替换成指向已存储的同样块identical chunks的引用reference。本文研究基于硬盘的hard-drive based针对备份存储的去重。(基础概念+研究场景)
碎片是硬盘系统中的去重的显著问题:备份中的逻辑上连续的块可能指向之前所写的分布在磁盘中的块,导致低局部性poor locality(空间局部性)。碎片问题导致:1. 低恢复restore性能:需要随机磁盘读取,可能引用很多之前的块,随机来回访问磁盘 2. GC效率低:之前备份版本删除时,被引用的块可能与未被引用的块存在一起,被引用的块需要移动后保存。(2个问题简述:restore+GC)
碎片问题(低局部性)是由于备份版本之间共享块。去重系统一般把要去重的块分组成大的单元unit称为container(通常4MB),用于压缩和最大化磁盘数组的写性能,并且使用块引用表chunk-reference list,例如recipe来记录每个备份版本中的被引用块。例如,版本1基本没有重复,其块在container中连续存储;版本2可能只修改小部分,其recipe中有许多指向版本1的引用,与指向新块的引用混合在一起。版本N可能引用许多之前备份中的块,因此恢复备份时需要随机来回访问磁盘random seeks back and forth across the disks,由于accessed container中可能有不需要的块,导致read amplification很高。(问题1详述,导致random seeks+read amplification)
为了解决碎片问题,提高恢复性能,提出了许多基于碎片程度fragmentation degree来write duplicates又称为重写的方法,来保证数据局部性。而且有方法使用内存和SSD缓存碎片块和经常引用的块,提升恢复速度,但是增加了硬件成本。随着备份版本的不断增长,碎片不可避免的存在。对4个备份数据集实验发现,即使用Capping和HAR的重写技术,去重率ADR降低了,但是sequential read speed of storage devices恢复速度也下降了。(rewrite和chache方法介绍,缺点简介)
在传统基于container的数据组织下,GC的性能也会被数据局部性影响。旧备份删除后,一些块无引用后可以从container中删除。GC包括2个阶段:1. 选择包括unreferenced块的container 2. 移动container中referenced块到新container中。第1阶段目前已有工作能快速找出containers,当局部性很差时,container中有引用和未被引用的块,由于大量块读写,第2阶段会很耗时。(问题2详述,container中有引用与未引用块)
目前用来提升restore和GC性能的方法需要平衡去重deduplication与备份工作负荷的局部性locality of backup workloads。在非去重的存储中解决碎片问题,通常把数据重组织以提升其布局layout。然而由于不同备份版本中会共享块,导致块引用关系复杂,针对所有备份版本设计最优布局同时保证去重效率不太可行。另外,由于一些块可能被很多版本引用,重组织块代价高,组织这些块涉及到很多版本。(全局OPT布局不可行)
通过对去重备份的观察,发现几乎所有重复块都是来自前一个版本,使得设计几乎没有碎片的去重块deduplicated的最优数据布局是可行的。通过以下3点来描述:1. 最优数据布局把块根据引用关系划分成不同类别categories。例如,一些块(集合M)只被备份版本Bi和Bj引用,被分成同一类,category类似于可变容量的container,分类保证如果一个块在备份恢复时被需要,那同category中的其他块也被需要,加载整个category不会造成read amplification。2. 通过观察和理论分析,categories个数可能增加飞快,对n个备份版本可能高达2^n个categories。 3. 通过观察,很少一些块引用关系可以忽略,因此只考虑被1个版本或连续版本引用的块。这样块引用关系得到简化,categories个数下降到n(n+1)/2,使得最优OPT数据布局可行。(观察想法:categories定义+数量分析+忽略少量块)
基于分类的OPT数据布局与传统的去重框架不同。传统去重主要集中在写路径the write path of deduplication,很少对块的位置location和放置placement进行管理,称为写友好的write-friendly。本文方法重新设计去重块的数据布局,解决碎片问题从而使得恢复和GC更快,称为管理友好的management-friendly。在实现OPT数据布局中使用离线迭代组织方法对每个incoming备份版本处理,代价相比与传统方法可接受。(对比传统去重框架:管理块布局,解决碎片问题,离线方法代价可接受)
总的来说,本文提出全新的管理友好的去重架构MFDedup,引入Neighbor-Duplicate-Focus indexing (NDF) and Across-Version-Aware Reorganization scheme (AVAR)技术。能够生成和维持OPT数据布局,解决碎片问题。具体贡献包括:
1. NDF只检测Bi+1与Bi版本中的重复,利用观察结论,使得有机会构建OPT数据布局。NDF在实现near-exact去重率的同时大大减少索引内存占用the memory footprint for the fingerprint index。(NDF优点)
2. 利用NDF对新备份版本Bi+1中去重后,AVAR依据简化的块和版本间的引用关系对版本Bi+1中unique块进行识别和分组,把这些特殊的块组织进OPT数据布局中。通过迭代更新OPT布局,GC直接删掉最旧的categories即可,因为最旧的版本被删除了,GC操作变得简单。(AVAR优点)
3. 实验结果表明,本方法拥有更高的去重率ADR和恢复吞吐效率restore throughput,恢复吞吐完全使用fully utilize存储设备。NDF索引相比于传统的全局索引只需要固定有限的成本fixed and limited overhead,GC基本是0代价的。(实验结论+优点总结)
2. Background
2.1 Background of Data Deduplication
数据去重是常用的存储系统数据缩减方法,通常数据去重系统会把输入数据流(备份数据、DB快照、VM映像等)划分成许多数据chunks(例如8KB),利用安全哈希签名(SHA-1)来进行唯一标识,也叫指纹fingerprint。然后去重系统根据指纹去除重复数据块,只保存一个物理copy来实现节约存储空间的目的。(基本去重方法)
备份存储和局部性:backup storage:由于本身重复特性通常会使用数据去重技术。在备份存储系统中,工作负荷workload一般指一系列的备份版本(例如primary data的连续快照),这些备份的大小可以缩减至1/10~1/30,从而减少硬件成本。Locality局部性:备份流中的块很可能在每个full完全备份中以相同的顺序order出现,经常被用于提升去重性能,利用HDD高度连续的I/O速度the high sequential I/O speed of HDDs,用于提升指纹检索fingerprint indexing、恢复restore的效率。(备份会去重,局部性可提升效率)
基于container的I/O:许多去重方法会与压缩方法结合使用,所有块被存到container中作为压缩的基本单元。因此,存储I/O通常基于container,这些container一般不可变且具有固定大小(例如4MB)。container优点:1. Writing in large unit写大单元可实现最大化的HDD顺序吞吐,compatible with striping across multiple drives in a RAID configuration?。硬盘比SSD和其他设备便宜,能节约备份存储的成本。2. Container中的数据局部性可以用于提升重复识别和恢复备份的效率。(container优点)
碎片问题:去重系统中的碎片与container-based I/O and the seek latency of HDDs有关。不同的备份会共享块,这些块随机分布在不同的container中,每个备份的空间局部性在去重后会被破坏。由于基于container的I/O,当恢复备份时,即使有少部分块被需要,整个container都要从硬盘中读取,称为read amplification= ![]() 。即使系统支持container内部压缩 compression regions,完整的fully压缩区域也需要被读取并解压,以获得需要的chunk。由于每个备份需要的container是在HDD上随机分布的,在HDD上寻找这些container也很耗时。随着备份的增多,read amplification和seek问题也更严重。(碎片导致读放大和seek时延)
。即使系统支持container内部压缩 compression regions,完整的fully压缩区域也需要被读取并解压,以获得需要的chunk。由于每个备份需要的container是在HDD上随机分布的,在HDD上寻找这些container也很耗时。随着备份的增多,read amplification和seek问题也更严重。(碎片导致读放大和seek时延)
2.2 Deduplication Techniques
分块方法chunking:Content-Defined Chunking (CDC)是常用的把备份流基于内容划分成可变长度块的方法,能解决定长分块fixed-size chunking中的boundary-shift问题。
指纹索引Fingerprint Index:检查指纹索引以检测重复是去重中重要的一步,指纹索引是备份系统的一部分,保存在内存中很昂贵,但是保存在HDD上会导致去重系统索引的瓶颈。目前方法大部分利用spatial or temporal locality局部性原理,使用指纹索引从磁盘加载指纹most leverage spatial or temporal locality by using the fingerprint index to load many fingerprints from disk that were written at the same time or consecutively in a file.
恢复优化方法Restore Optimization Techniques:在去重后恢复备份时碎片会导致read amplification和seek问题。目前的恢复优化方法主要有两种技术:1. Rewriting重写:通过selectively rewrite duplicates来平衡去重率与提升局部性,重写会降低去重率,在重写后read amplification仍会有2~4倍。2. Caching 缓存:使用SSD或者内存来缓存经常被引用或者将来可能要用的块,缓存命中率cache hit ratio依赖于局部性,读放大问题仍未解决。
在重写技术中,Capping:在对之前写过的container去重时,会记录当前备份对container中的块引用数量。对于low reuse的container,重写块以提升当前备份的局部性。 HAR:利用备份流的相似性,根据历史信息识别sparse container,重写引用这些container的块。本方法写最少的重复块,并且创建没有碎片和读放大问题的数据布局writes minimal duplicate chunks and creates a data layout without any fragmentation or read amplification。(本方法比Capping和HAR重写更少)
GC:用户通常使用备份软件配置保留策略retention policy,一般保存数周或者数月后删除更旧的备份。GC从系统中移除未被引用的块,目前有两种GC方法:
1. 传统的Mark-Sweep:遍历备份,标记引用的块walks the backups and marks the chunks referenced from those backups,未被引用的块被清除。这需要从部分未引用的container中拷贝活动块,并创建新container,copying live chunks from a partially-unreferenced container and forming new containers这个操作是I/O紧张的。(粒度太细,I/O紧张)
2. Container-Marker Algorithm (CMA):维护container manifest用来记录每个container被引用的备份,删除无引用的container,是粗粒度coarse-grained的GC方法,如果container中有任何块被引用,就会保留container,会造成空间浪费。本文用细粒度fine-grained GC,但比之前的方法代价更小。(粒度太粗,空间浪费)
3. Observation and Motivation
3.1 Analysis for Fragmentation and Read Amplification after Deduplication
碎片会导致使用基于container的I/O的去重系统出现读放大问题,本节分析读放大产生的详细原因。(读放大产生原因:读了不需要的块-restore性能低之一)
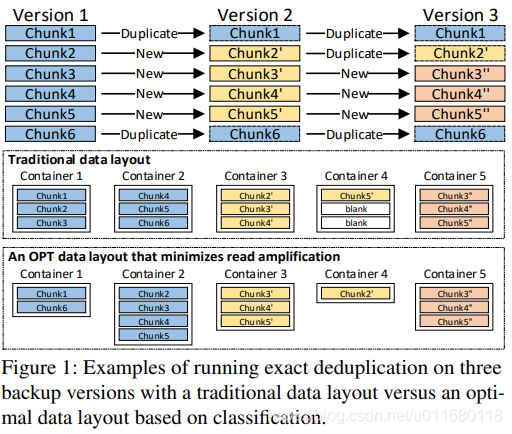
3个备份版本进行去重后的传统数据布局与基于分类的OPT数据布局
传统的去重后,所有保留的块按照备份中的出现顺序存储在container中,图1中块6被所有备份版本引用,因此不论恢复哪个版本,都需要从HDD中读取container2。
对于版本2和3,只需要container2中的块6,但是包含了未引用的块4和5,这是空间局部性低的例子。因此加载container2时导致了读放大,在恢复备份时读取了不需要的2个块。对于版本1,container2中的3个块都需要,具有强局部性,没有碎片和读放大问题。在传统数据布局下,块6对于版本2和3是碎片,对版本1不是碎片,碎片与备份版本和块引用关系有关。
3.2 An Optimal Data Layout
本节讨论根据块引用关系的基于分类的OPT数据布局。
分类例子:container2中的3个块可以分为两类:第1类包括块4和5,只被版本1引用;第2类包括块6,被3个版本都引用。如果把这两类分开存储到不同的container中,碎片问题可以解决,在恢复版本时没有读放大问题。
基于分类的数据布局:所有块可以按照引用关系分为5类,把每一类存到变长container中,container1中包括被3个版本引用的块,container2中包括只被版本1引用的块。。这种布局对每个备份版本都能保持强空间局部性,读放大为1,因此称为最小化读放大数量的OPT数据布局。恢复备份时不会读取任何不必要的块,最坏情况下n个版本会有2^n-1类
OPT数据布局的挑战:实际的备份工作负载非常复杂,这种方法解决读放大,但是需要对很多只包括1个块的container进行搜索seek,也造成了低数据局部性。(本方法无读放大,但可能seek太多)
3.3 Derivation Relationship of Backups
对4个大备份数据集进行分析,能帮助减少categories的个数。
在备份存储系统中,工作负载workload通常包括一系列备份映像,都是从主要存储系统primary storage system中的原始数据original data所产生。因此,每个备份的重复块不是随机分布的,而是由上一个版本继承得到的。这个观察与许多系统利用的重复内容具有典型的连续特征这一原则相符合。
在备份版本Bi中标注4种块:1. 内部internal重复块:引用的块也在Bi中; 2. 相邻adjacent重复块,引用的块不在Bi,在Bi-1中; 3. 跳跃skip重复块:引用的块不在Bi-1和Bi中; 4. 唯一unique块:不重复的块
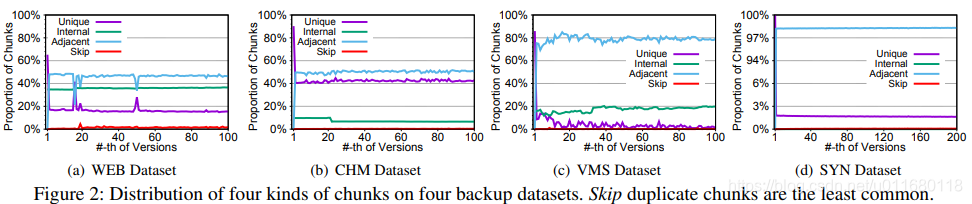
Key observation:图2中展示了4个备份数据集在去重过程中的4中块的个数分布。发现重复最多的是第2类和第1类,占据了超过99.5%,第3类跳跃块很少,因此不对跳跃块去重以保证局部性,因为这些块对去重率影响很小。
把第3类当作第4类来处理,很大的简化了块引用关系:OPT布局中每个块要么被1个版本引用,要么被连续的版本(Bi…Bi+k)引用。基于这个条件,可以大大减少categories的数量,3个备份版本,k=0时,有3个categories,k!=0时,选择开头和结尾,有3个category,一共6个,比原来的7个少。n个备份版本,k=0即开头与结尾相同,共n个;k!=0,在n个中不重复挑两个作为开头和结尾,n(n-1)/2个,总共categories的个数最多为n(n+1)/2。
30个备份版本,最多有465个container,2150个块,每个container的大小平均为17.6MB,使得OPT数据布局可行,且container的大小足以维持空间局部性。(简化块定义:internal,adjcent以及unique(包括skip),减少categories数量)
4. Design and Implementation
4.1 MFDedup Overview
在去重备份系统中实现OPT数据布局是可行的,主要基于以下2个设计原则:① 所有块根据引用关系被分类到categories中 -> 避免读放大 ② Skip跳跃块被当作unique块,以简化引用关系
MFDedup:保持局部性,减少碎片,利用离线算法重组织块,使用以下两个技巧:
1. Neighbor-Duplicate-Focus indexing (NDF):只去除相邻备份版本间的重复,只需要建立和访问包括相邻版本指纹的索引,比传统的全局指纹索引资源要求更少
2. Across-Version-Aware Reorganization (AVAR): 检测到每个新版本中的重复块后,MFDedup在线下组织上一个版本的去重块。这些块被不断的分类从而更新OPT数据布局。
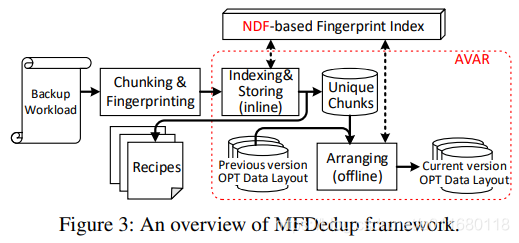
图3展示了完整流程,包括3个阶段:① Chunking & Fingerprinting:利用CDC对备份数据流进行分块,利用SHA1对每个块计算指纹;② Indexing & Storing:利用基于NDF的指纹索引,检测来自上一版本的重复和唯一块,存储唯一块,以及对每个备份的Recipe,记录备份中的块指纹顺序chunk-fingerprint sequence,用于去重后的备份版本恢复;③ Arranging:离线操作,迭代更新OPT数据布局,以支持基于NDF的指纹索引。
MFDedup利用NDF进行在线去重,只去重相邻备份版本间的重复,利用AVAR进行离线组织,使得OPT数据布局能保持备份的局部性且去除碎片。
4.2 Neighbor-Duplicate-Focus Indexing
NDF索引是基于大部分重复块来自前一版本的观察结论,在版本Bi中只识别与Bi中其他块相同的块,或者与Bi-1中块相同的块。
对每个备份版本维护一个独立的指纹索引表,除了在Indexing & Storing中使用NDF来进行重复检测,在Arranging阶段也使用NDF进行分类。对最新的2个备份版本使用指纹索引表后,即可释放表,因此只需要维护2个指纹索引表,相比于传统的存储所有版本的索引要小的多,因此可以存在内存里或者利用基于局部性locality-based的方法进行加载。假设1个指纹索引条目entry需要20 bytes(SHA1的摘要长度),备份版本大小为10GB,块大小为8KB,基于NDF的指纹索引所需空间为2×10GB/8KB×20B = 50MB。
NDF的索引成本indexing overhead与最新的2个备份版本的数据大小有关,相比于传统的全局指纹索引要小。NDF还可以在支持OPT布局的同时实现achieve a near-exact deduplication ratio。(NDF中包括2个表,更小,且去重率差不多)
4.3 Across-Version-Aware Reorganization
AVAR用于去除碎片和利用NDF生成OPT布局。包括:① Deduplicating (i.e., Indexing & Storing):识别版本Bi中的unique块; ② Arranging:利用Bi的unique块,重新组织B1..Bi-1的布局,从而对版本B1..Bi的OPT布局进行更新。当第1个版本保存时,自然有一个OPT布局,这时候不需要Arranging。图4给出3个备份下的AVAR工作流程。
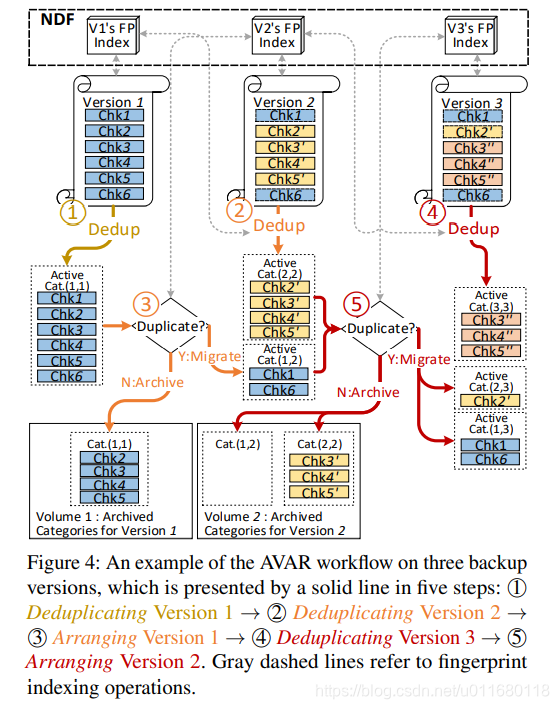
Deduplicating Stage:利用基于NDF的指纹检测重复块,保存unique块到Recipe中。先忽略Recipe,主要关注OPT布局中如何组织数据块。图4中的①②④中,去重阶段把Bi中的unique块存入新的active category中,目前只被Bi引用,这些块未来可能被新版本引用,那时候会被Arranging阶段处理。(去重:把unique块存入active categories)
每个category的名称反映了哪些备份版本引用本category。例如被版本2,3,4引用的category命名为Cat.(2,4)
Arranging Stage:根据MFDedup的第1个原则:所有块根据引用关系被分类到categories中。分类方法是基于块和版本的引用关系,当新版本产生并被Deduplicating阶段处理后,旧的OPT布局就会失效,因为块和版本的引用关系发生了变化。因此本阶段遵循第2个原则Skip跳跃块被当作unique块,以简化引用关系,基于经过Deplicating阶段处理的新版本的unique块,来更新OPT布局。
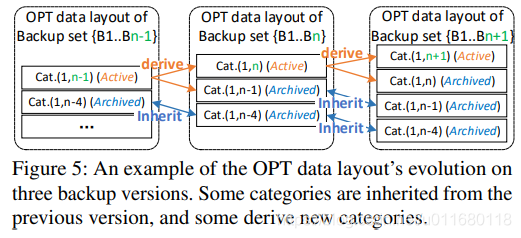
图5中展示了OPT布局的变化过程,在版本集B1..Bn-1中,Cat.(1,n-4)没有被最新版本Bn-1引用,也不会被Bn及以后的版本引用。因此这类categories作为OPT布局的一部分carried forward一直保存,被标记为archived。另外,被最新版本Bn-1引用的Cat.(1,n-1)在备份Bn时会被分成2个categories,这类categories称为active。
在更新OPT布局时,Archived表示categories不可变,active表示categories后续会被Arranging。因此在Arranging阶段,主要关注active类的categories。例如图4中的⑤,在备份版本3后,现存的active Cat.(1,2)和Cat.(2,2)是唯一2个目前active的,因此使用版本3的指纹索引检查其中的每个块,在版本3中重复的块就移动到new active Cat.(1,3)和Cat.(2,3),其他块保存到archived Cat.(1,2)和Cat.(2,2)。当完成移动与archive后,旧的active Cat.(1,2)和Cat.(2,2)被删掉。(分组:用最新指纹对当前active categories分类)
Grouping分组:对现有active的categories进行Arranging后,新的Archived categories根据名称顺序(e.g. in the order of Cat.(1,3), Cat.(2,3), Cat.(3,3))被分组到Volume中,能更好的管理存储。
4.4 Restore and Garbage Collection
Restore: 进行备份恢复时,只用读取OPT布局中需要的categories。所需块的检索可以通过OPT布局计算出来,因此是 totally metadata-free。
存储了n个备份版本,想恢复Bk,所有被Bk引用的块都需要,其计算公式如下:
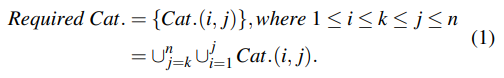
图6中有4个存储的版本,恢复版本3需要蓝色的categories,根据Volume的存放规则,![]() 是顺序存放的,因此加载这些categories最多需要n次顺序读操作。
是顺序存放的,因此加载这些categories最多需要n次顺序读操作。
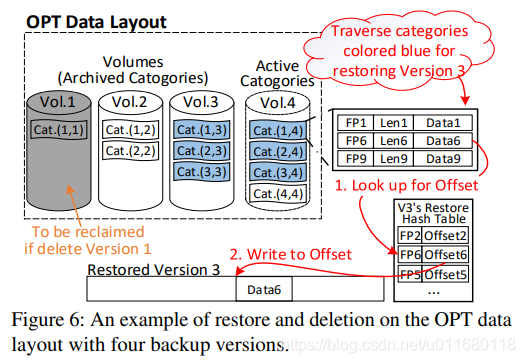
在恢复备份时需要Recipe来构建’restore’哈希表,其结构如图6所示。哈希表中的条目包括<指纹,偏移>,记录了块指纹和在要恢复系统中的偏移量。
图6也展现了restore的过程,在获得需要的categories后,根据版本3的Recipe每个块依次恢复。MFDedup只需要找到需要的Volumes,然后顺序读取所需categories,这样实现了更高的restore性能,只需很少的seeks和大量sequential I/O。(restore快速顺序读)
Deletion and Garbage Collection:删除和GC很简单,空间可以立刻重用。在去重系统中,删除备份版本意味着重新使用其unique块(未被其他备份引用的块)。FIFO-based的删除只需要删除和重用最老的Volumes,因为他们包括了最早备份版本的unique块。例如图6中,直接删掉Volume1就能重用版本1的空间。
MFDedup也支持删除非最早版本的备份。从Depulicating阶段中的描述可知每个备份版本的unique块都存储在每个volume最后一个category中,如图6所示。因此,可以通过修改volume的长度,删掉最新的category,从而删除任意版本的备份。例如要删掉图6的版本2,可以直接从Volume2中删掉archived Category 3。已有工作提到CMA方法只支持FIFO删除,本方法可以支持任意删除。
MFDedup中不使用传统的GC方法,例如mark-sweep或者reference-count management,由于块引用关系已经在OPT布局中设计好,可以大大减少系统资源(CPU cycles, RAM, I/O)的消耗,以及编码复杂度。(删除简单0代价)
4.5 Discussion and Limitations
本节讨论overheads、limitations、optimizations。
Self-Organization of OPT data layout :OPT数据布局是自组织且简单的,元数据metadata的成本大大降低。传统的去重系统中每个unique块的真实物理位置和引用计数被用于restore和GC,这里不再需要。在OPT布局中每个版本的所需categories都可以计算。
Backups Size:备份大小一般是可变的,许多VM备份超过100GB,最近的虚拟机的索引是400MB。有学者指出大部分Data Domain and Symantec production系统的备份为50~500GB,MFDedup的内存成本合理,可以直接用于这些场景。
Fingerprint Prefetching for Larger Backups:目前MFDedup设计的索引在RAM中,之前针对大量指纹索引设计的prefetching and caching sequences of fingerprints技术也可以使用。认为顺序局部性sequential locality仍然存在的原因:1. 尽管经过Arranging,categories之间的顺序局部性被破坏,categories内部的顺序局部性仍然存在;2. Recipe保存了每个备份的顺序局部性。
Restoring for Larger Backups:当恢复单个大备份时,由于块是由categories组织的,也可以对每个category设计’restore’哈希表,单独加载到内存中。另外,单个备份可以被分为多个小单元sub-units < 100GB,以减轻备份和恢复的内存压力。当备份大小很大(超过10TB)时,如果只有1个categories,哈希表也会很大over 10T B/8KB × (20B + 8B) = 35GB,其中指纹20B,偏移8B,很难保存到内存中,因此MFDedup不能处理这种情况。
Incremental Backups vs. Full Backups:MFDedup是为全量备份设计的,对于增量备份,可以增加API进行区分备份类型。由于synthetic full backups应用广泛,增长的变化incremental changes与最新的全量备份有关,MFDedup也可以直接应用。
Reserved Space for Arranging:Arranging是离线的,其中块要么迁移要么存档,需要额外的空间。图4中显示Arranging是在active categories上运行的,因此预留空间与active categories最大空间相等,与全量备份相比很小,在5.6中会介绍。
What if Arranging Falls Behind:如果要备份的workload很多,没时间完成Arranging,可以暂时跳过这个阶段,将来空闲时间再完成。如果拖得越久,OPT布局更新越慢,会导致读放大和restore吞吐量的下降。不过有研究表明用户备份时间一般间隔较大,可以留足够时间完成Arranging,另外当Arranging滞后时,去重率越高,读放大程度和restore吞吐量的减少越小。
Time Overhead of Offline Arranging:把GC的一些后台工作放到Arranging中有多个好处:高restore speed,即时空间重利用。Arranging是一个遍历备份中active categories,把重复块迁移、unique块存档的离线过程。在5.5中表明,Arranging的耗时接近或者优于GC,并且提供更高的restore和GC性能。本文中在每次备份后都运行Arranging,以保证OPT布局最优,但是Arranging也可以像GC一样,几次备份后再运行,这种情况下,会增加读放大,不过这种情况下重复块多次迁移的情况可以进行合并,减少迁移次数,不过这点没有进行实验。
Out-of-Order Restore:与传统去重系统不同,MFDedup中的restore是乱序的,恢复块的写顺序不一定与workload中的逻辑顺序一致。但是一个备份中volumes中的块一般是顺序的,有一些由其他volumes来填充的logical gaps,因此会导致随机写random writes。尽管categories内部仍具有顺序局部性,如果存储介质由很好的随机写性能(例如SSD)那么restore效率会更高。此外,在恢复备份到HDD时也可以使用reassembly buffer等技术提高性能。(相关问题讨论)
5. Performance Evaluation
5.1 experimental setup
Evaluation Platform and Configurations:workstation ubuntu 18.04, i7, 3.2GHz CPU, 64GB内存,Intel D3-S4610 SSDs, and 7200rpm HDDs 构建原型和Destor(实验平台)用于比较多个restore和GC的方法,包括HAR、Capping和CMA。MFDedup和Destor在Chunking&Fingerprinting阶段使用相同配置:Chunking使用FastCDC (块最小2KB,平均8KB,最大64KB),Fingerprinting使用ISA_L_crypto的SHA1算法。
Experimental methods:为了模拟真实的备份/恢复场景,把工作站的存储空间分成两部分:备份空间使用7200转的HDD,用户空间使用SSD。两个空间都有XFS日志文件系统,用HDD做备份,用SSD运行主系统primary system很常见。
测试数据集用于从用户空间存储到备份空间,保存一个个版本,恢复过程则相反。在每次备份/恢复前,都需要清空文件系统缓存 echo 3> /proc/sys/vm/drop_caches
为了模拟用户的删除需求,最多保存20个备份版本,因此当版本n备份时,版本n-20被删除,与HAR和CMA一样。对备份、恢复、GC的吞吐量throughput (time cost)进行评估采用5次运行的平均值。
基于Container的I/O也被考虑,许多去重存储系统会与压缩技术结合,所有块存储在container中,作为压缩的基本单元。压缩与去重目标一样,但方法不同,不评估压缩方法。
Evaluation Dataset:4个数据集代表不同的典型备份workload,包括网页、开源项目、VM镜像和人工数据集synthetic,去重率从2.19~44.65. WEB, SYN, VMS数据集已经被其他数据去重工作使用过。(实验配置:平台+对比方法+数据集+模拟过程)
5.2 Actual Deduplication Ratio
ADR= ![]() 重写和GC方法(HAR, Capping, CMA)使用更多存储空间来换取更好的恢复和GC性能。MFDedup忽略skip块来实现OPT布局,也会降低去重率。
重写和GC方法(HAR, Capping, CMA)使用更多存储空间来换取更好的恢复和GC性能。MFDedup忽略skip块来实现OPT布局,也会降低去重率。
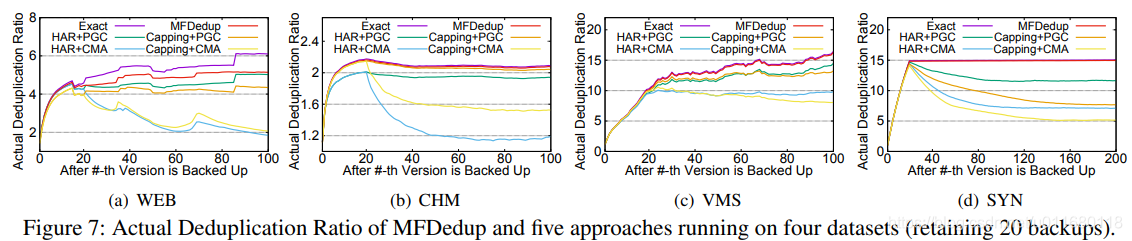
图7反映了MFDedup(包括GC),Exact Deduplication和其他方法,包括重写(HAR+Capping)、GC(Perfect GC+CMA)。由于只保留20个最新备份,Perfect GC和CMA代表两个使用Mark-Sweep的典型方法,效用分别是utilization thresholds set at 0% and 100%。Perfect GC重复使用所有可能的空间,CMA运作更快,但是在container中留下了部分未引用的块,代表了GC影响的两种极端。
图7中MFDedup与Extract去重的ADR非常接近,比重写和GC方法更高。因为MFDedup中忽略skip重复块的空间相比于用其他方法的重写块要小很多。
图7中在版本21后GC开始后,重写技术造成了ADR的下降。CMA技术加入后,下降更严重。符合第2章的讨论:重写降低去重率,GC可以lead to more rewritten chunks。OPT布局支持删除和GC,没有碎片问题和空间开销。由于OPT布局,MFDedup比其他方法去重率高1.12~2.19。(ADR对比)
5.3 Backup Throughput
本节评估与重写技术相比的备份吞吐量。由于GC一般离线,这里不考虑GC的影响。HAR和Capping都使用full-in-memory全局指纹索引,MFDedup使用基于NDF的local指纹索引。为了最小化读取数据集的性能影响,把数据集从ram disk中备份来衡量备份的吞吐量。
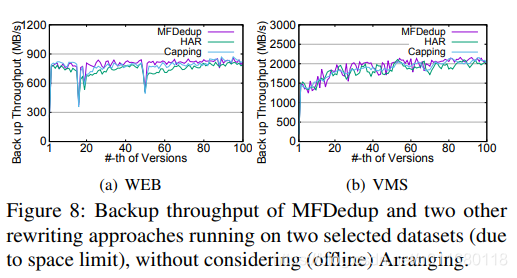
图8中显示本方法没有牺牲备份吞吐量以达到其他优点。3种方法的性能都相似受限于块和SHA1摘要计算。理论上,MFDedup不用重写重复块,达到更高的ADR,其在备份时的存储I/O也会更小。
Indexing Overhead:在备份时,测量了NDF索引的最大内存代价,从6.27~46.35MB(只索引2个备份版本)。传统的去重方法保留所有20个版本的全局指纹索引,需要26.81~64.45MB空间,传统的全局索引随着保留版本的增多而增长,而NDF只保留2个索引。(备份数据吞吐量不影响,索引存储更少)
5.4 Restore Throughput
以前的工作用Speed Factor来衡量恢复的吞吐量,指的时去重系统中每个固定大小的container读取中有用的数据比例。defined as the ratio of useful data restored per container read。由于MFDedup使用变长container,定义别的标准:1. Restore Throughput, 2. Seek Number:读磁盘上的container/volume所需要的寻道操作seek operations, 3.Read Amplification Factor:第2.2节定义过。
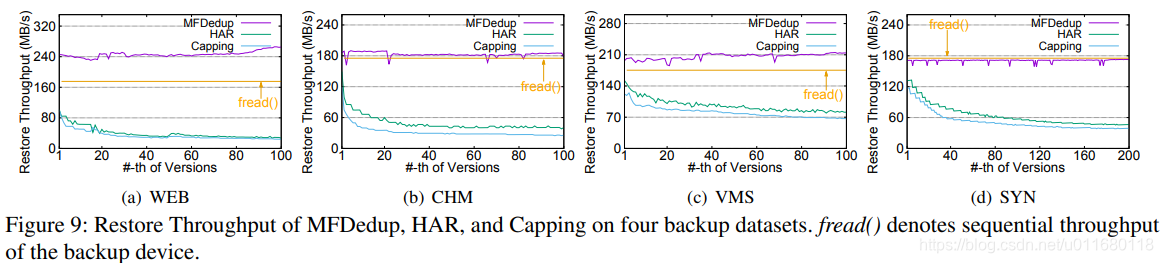
图9,10,11中展示MFDedup, HAR, Capping在3个标准的结果,恢复吞吐量与其他2个标准基本一致。图9表明HAR优于Capping,MFDedup比HAR更好。这是因为MFDedup消除碎片,利用OPT布局维持备份workload的局部性,但是其他2种方法种碎片问题还是存在,而且随着版本变多更加严重。(恢复吞吐量好)
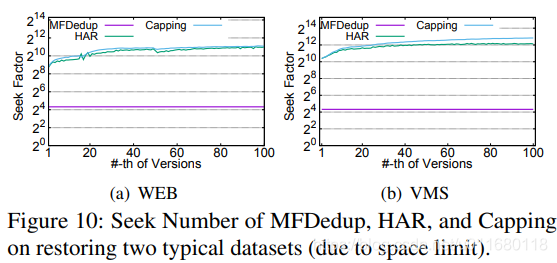
图10展示2个数据集的seek数量,因为空间不够移除了另外2个数据集,趋势是一致的。MFDedup把seek number从上千减少到20,因为把archived categories存储到大的顺序写的volume中,另外2个方法由于所需块分散而需要更多的seek操作。(seek number少)
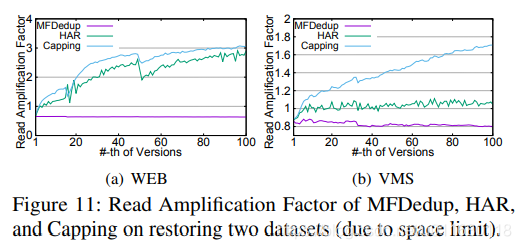
图11中所有数据集的读放大趋势一致,MFDedup最小,是因为去除了碎片,而另2个方法在恢复时会读无用的块。MFDedup的读放大因子<1是因为备份版本的内部去重(图2),读的块可以在恢复时多次使用。甚至比存储媒体本身的fread效率更高,说明可以完全利用存储介质的性能。(读放大低)
以上结果也是在保留20个版本的情况下评估的,如果保留更多备份版本,HAR和Capping的恢复性能会降低,而MFDedup没有碎片问题,实现了基本一贯较高的恢复吞吐量。
5.5 Arranging vs. Traditional GC
与传统去重方法相比,本方法的GC代价基本为0,但是增加了离线Arranging的过程。接下来与Perfect GC进行比较,对MFDedup中更新OPT布局的代价进行评估。
GC方法主要在如何选取要清除的container和块时不同,一旦选择后,所有GC方法都需要把被引用的块移动到新的不可变的container中。为了简化分析,主要关注GC中公共的阶段,即读取被选定的container和移动有效块到新container中。这是GC代价的下限,因为忽略了挑选阶段,例如遍历块等的耗时。
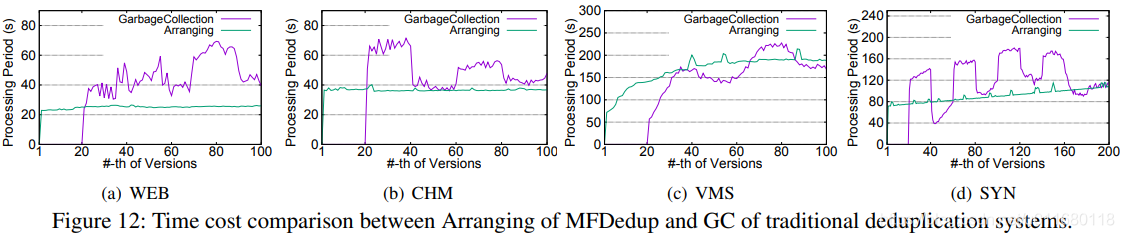
图12中比较Arranging和Perfect GC,对前20个备份不运行GC,但是会运行Arranging,对20个备份后的性能分析发现,Arranging在3个数据集上的处理时间比GC短,在VM映像上要长9%,这是因为VMS的修改方式是一直修改每个备份中的同一区域,使得GC很容易。通常来说,图12反映出即使把挑选环节考虑进来,Arranging通常要更快一些。当MFDedup进行GC时,处理时间可以忽略不计,因为大的volumes可以直接删除without any copy-forward。
Arranging的耗时是比较稳定的,而GC的运行时间不定,更稳定的代价对存储系统来说更好进行规划。Arranging稳定是因为这是一个对最近版本的本地操作local process,而GC是全局处理global process。图6中显示,每次版本中产生了active categories都会进行arranging,且总能实现更好的局部性。而其他方法中的GC局部性差,是因为被挑选的container和块可能随机分布。
在第5.2节中讨论过,其他GC方法比Perfect GC要快,但是会牺牲ADR真实去重率。而MFDedup几乎没有ADR的损失,而且支持立即immediate删除和GC,也达到了几乎完美的nearly perfect恢复性能,以及可接受的Arranging代价。(耗时短,稳定,代价可接受)
5.6 Size Distribution of Volumes/Categories
本节展示volumes和active categories的数据布局,保留了100个版本without retention for evaluation,系统中会有99个volumes和100个active categories,这些active categories组成了逻辑上的volume,会在下一次Arranging后archive到volume中。
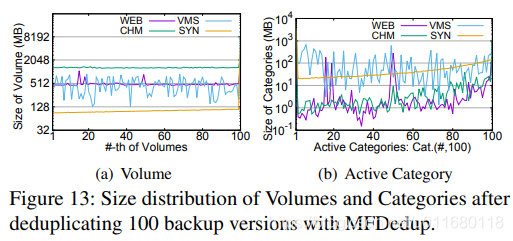
图13(a)表明volumes大小在90MB~1.3GB间,可以告知用户通过删除备份版本volumes可以释放多少空间,也能帮助用户估计剩余写空间,因为volumes代表了相邻版本的差距。对于传统的去重方法,即使考虑sketching approaches,这两个问题也难以解答。
图13(b)表明active categories的大小波动大,最大的categories空间为最新备份版本的51.87%,这表明离线Arranging所需要预留的空间比完整备份要小很多,与第4.5节的讨论一致。而且预留的空间可以通过压缩categories进行缩减。(volumes/categories占用空间)
6. Conclusion and Future Work
本文提出了管理友好的去重框架MFDedup,与传统的写友好Write Friendly的框架不同,本方法通过引入NDF和AVAR来生成OPT布局,从而维持备份的局部性,解决了碎片问题。
由于去除了碎片,MFDedup提高了ADR实际去重率(1.12× to 2.19× higher) 和恢复吞吐量(2.63× to 11.64× higher) ,在用于更新OPT布局的离线Arranging耗时可以接受的同时,GC基本零成本。
未来工作,加入delta压缩,进一步节约空间;对更复杂的备份场景进行处理,例如增量备份。
这篇关于【论文笔记】The Dilemma between Deduplication and Locality: Can Both be Achieved?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







