本文主要是介绍AI论文速读 | 2024[SIGIR]基于大语言模型的下一个兴趣点推荐,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文标题:Large Language Models for Next Point-of-Interest Recommendation
作者:Peibo Li ; Maarten de Rijke ; Hao Xue (薛昊); Shuang Ao ; Yang Song ; Flora D. Salim
机构:新南威尔士大学(UNSW),阿姆斯特丹大学(UVA)
论文链接:https://arxiv.org/abs/2404.17591
Cool Paper:https://papers.cool/arxiv/2404.17591
代码:https://github.com/neolifer/LLM4POI
TL, DR:本文通过利用预训练的大语言模型处理位置基社交网络数据,提出了一种新的方法来提高下一个兴趣点推荐的性能,同时通过轨迹提示和关键查询对相似性来缓解冷启动问题。
关键词:位置基社交网络(LBSN)、POI推荐、大语言模型(Large Language Models, LLMs)
Total 10 Pages(2 Methodology+3.5 Experiment)

🌟【紧跟前沿】“时空探索之旅”与你一起探索时空奥秘!🚀
欢迎大家关注时空探索之旅
摘要
下一个兴趣点 (POI) 推荐任务是根据用户的历史数据来预测用户的下一次 POI 访问。基于位置的社交网络(LBSN)数据通常用于下一个 POI 推荐任务,但也面临着挑战。一项经常被忽视的挑战是如何有效地利用 LBSN 数据中存在的丰富上下文信息。以前的方法受到数值性质的限制,无法解决这一挑战。本文提出了一个使用预训练大语言模型(LLM)来应对这一挑战的框架。该框架允许我们以原始格式保存异构 LBSN 数据,从而避免上下文信息的丢失。此外,由于包含常识知识,该框架能够理解上下文信息的内在含义。在实验中,在三个真实的 LBSN 数据集上测试框架。结果表明,所提出的框架在所有三个数据集中都优于最先进的模型。分析证明了所提出的框架在使用上下文信息以及缓解常见的冷启动和短轨迹问题方面的有效性。
Q: 这篇论文试图解决什么问题?

A: 这篇论文试图解决的问题是如何有效地利用位置基社交网络(Location-based Social Network, LBSN)数据中的丰富上下文信息来提高下一个兴趣点(Point-of-Interest, POI)推荐任务的性能。具体来说,论文提出了以下几个关键挑战:
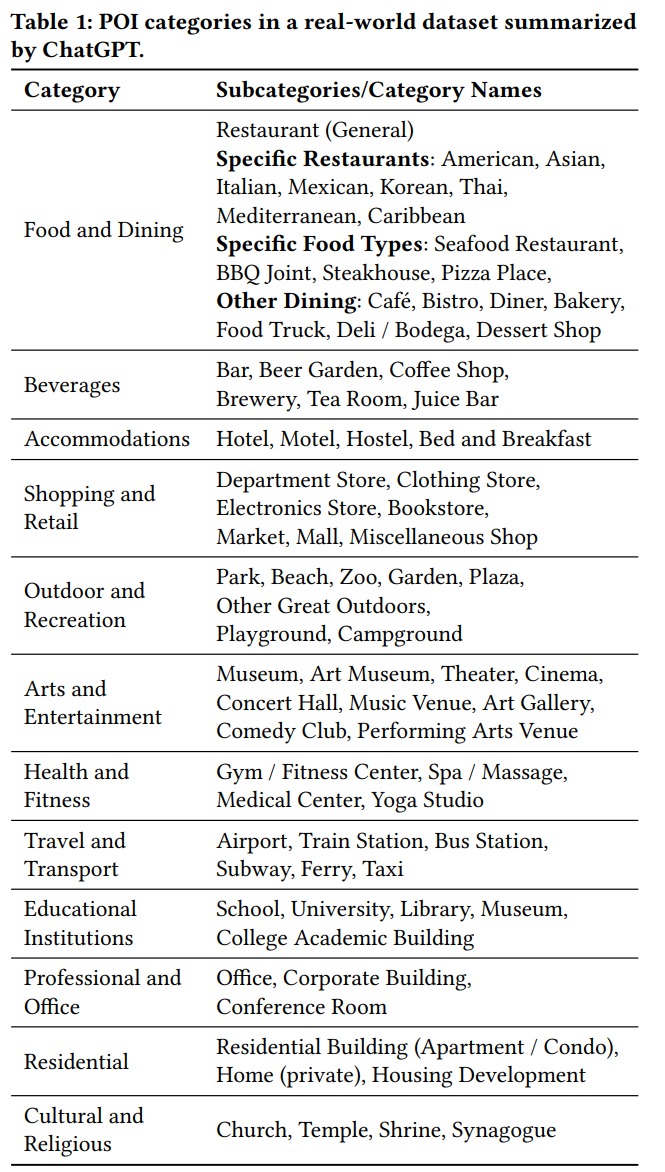
- 上下文信息的提取:如何从原始数据中提取上下文信息,如时间、POI类别和地理坐标。
- 上下文信息与常识知识的连接:如何将上下文信息与常识知识相结合,以有效地促进下一个POI推荐。
传统的基于数值的方法在处理上下文信息时存在两个主要限制:
- 它们需要将异构的LBSN数据转换为数字,这可能导致上下文信息的固有含义丢失。
- 它们仅依赖于统计和人为设计来理解上下文信息,缺乏对上下文信息提供的语义概念的理解。
为了解决这些挑战,论文提出了一个框架,使用预训练的大语言模型(Large Language Models, LLMs)来处理LBSN数据。该框架允许在原始格式下保留异构的LBSN数据,从而避免上下文信息的丢失,并且能够通过包含常识知识来理解上下文信息的内在含义。
论文的主要贡献包括:
- 提出了一个使用预训练大语言模型的框架,用于下一个POI推荐任务,这是首次在标准尺寸的数据集上微调语言模型以利用常识知识。
- 提出了基于提示(prompt-based)的轨迹相似性概念,用于结合历史轨迹和不同用户的轨迹信息,以缓解冷启动问题,并提高对各种长度轨迹的预测准确性。
- 在三个真实世界的LBSN数据集上进行了广泛的实验评估,证明了所提出的下一个POI推荐模型在所有三个数据集上都显著优于现有的最先进模型。
Q: 有哪些相关研究?
A: 论文中提到的相关研究主要分为以下几个领域:
- 下一个POI推荐(Next POI Recommendation):
- 早期工作通常将下一个POI推荐视为序列推荐任务,使用了FPMC、Markov链和softmax函数等方法。
- 随着深度学习的发展,开始应用基于RNN的模型,如HST-LSTM、LSTPM、PLSPL、STAN和CFPRec等,这些模型能够捕捉复杂的序列模式。
- 基于图的模型(Graph-based models):
- 用于解决序列模型的局限性,如STP-UDGAT、HMT-GRN、DRGN、GETNEXT和STHGCN等,这些模型通过全局视角和图注意力网络来捕捉用户和POI之间的复杂关系。
- 大语言模型(Large Language Models, LLMs)在时间序列数据(Time-series Data)中的应用:
- SHIFT和AuxMobLCast等研究将人类移动性预测视为语言翻译问题,使用序列到序列的语言模型。
- LLM4TS采用了两阶段微调方法,首先对LLM进行监督微调以适应时间序列数据,然后进行特定任务的微调。
- 大语言模型在推荐系统(Recommender Systems)中的应用:
- 近期的研究工作采用了LLMs,如通过设计多个提示模板来从不同角度处理新闻数据,并使用BERT进行提示学习。
- 其他方法包括直接微调LLMs进行提示完成,或者将LLMs的嵌入与现有序列模型结合,以增强模型的性能。
这些研究为本文提出的使用预训练的大语言模型来处理下一个POI推荐任务提供了理论和技术基础。论文中提到的相关工作还包括了如何通过提示工程(prompt engineering)和微调技术来利用LLMs,以及如何将这些技术应用于推荐系统和时间序列预测任务。
Q: 论文如何解决这个问题?
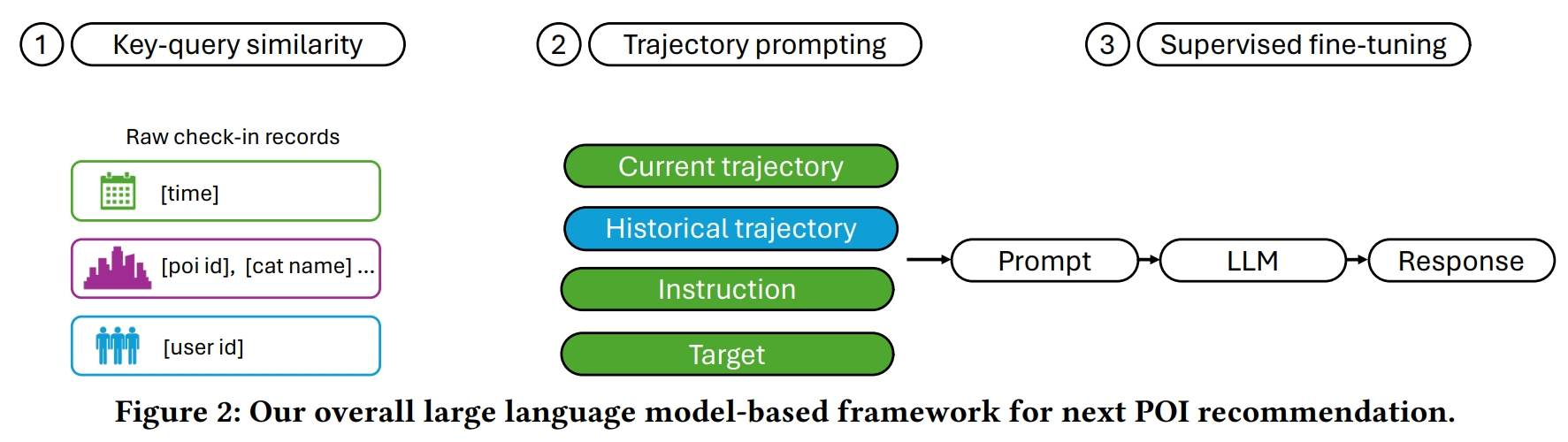

红色表示当前轨迹块。紫色表示历史轨迹块。橙色表示指令块。蓝色表示目标块。
A: 论文提出了一个基于大语言模型(LLMs)的框架来解决下一个兴趣点(POI)推荐任务中的挑战,具体方法如下:
- 轨迹提示(Trajectory Prompting):
- 将用户的检查点数据序列转换为自然语言问答格式,以便LLMs能够遵循提示中的指令并生成POI推荐。
- 通过设计不同的句子块来构建提示,包括当前轨迹块、历史轨迹块、指令块和目标块。
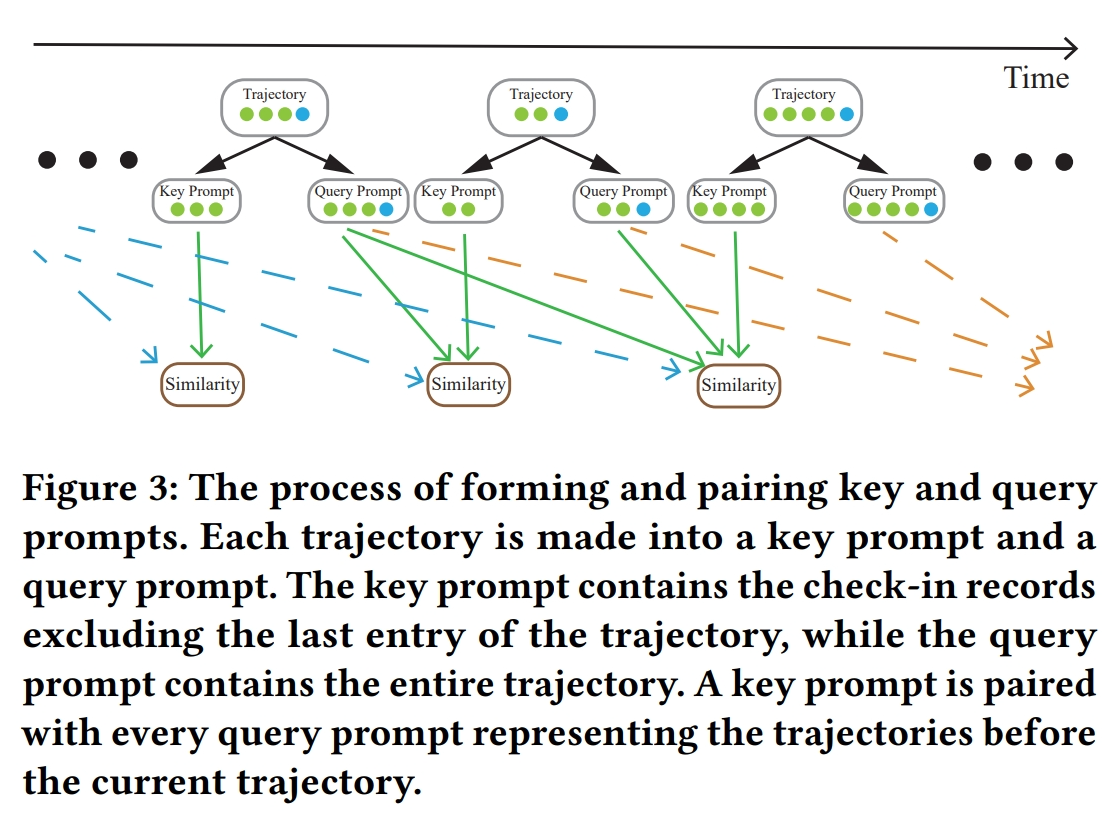
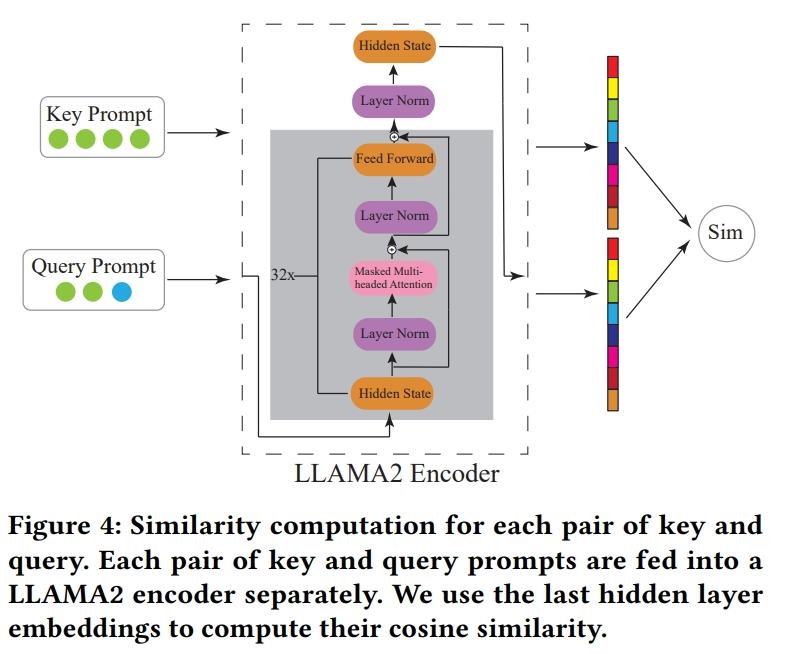
- 关键查询对相似性(Key-Query Pair Similarity):
- 提出一种计算框架,用于计算自然语言格式中轨迹的相似性,以便从历史轨迹和其他用户的轨迹中捕获用户行为模式。
- 通过计算关键提示(当前轨迹,不包括最后一个条目)和所有查询提示(代表早于关键提示开始时间的轨迹)之间的相似性,选择与关键提示相似性高的查询提示。
- 监督微调(Supervised Fine-tuning):
- 采用参数高效的微调技术,包括低秩适应(LoRA)、量化技术和FlashAttention,以减少训练成本和提高模型的效率。
- 实验评估:
- 在三个真实世界的LBSN数据集上进行广泛的实验评估,证明了所提出的模型在所有数据集上都显著优于现有的最先进模型。
- 分析:
- 对模型进行了深入分析,包括用户冷启动分析、轨迹长度分析、历史数据变体数量分析、未见数据泛化分析和上下文信息分析,以展示模型在处理冷启动问题、不同长度轨迹、利用历史数据和上下文信息方面的有效性。
通过这些方法,论文提出的框架能够有效地利用LBSN数据中的上下文信息,并缓解冷启动和短轨迹问题,同时提高下一个POI推荐任务的性能。
Q: 论文做了哪些实验?



A: 论文中进行了多项实验来评估提出的基于大语言模型(LLMs)的下一个兴趣点(POI)推荐框架的性能。具体的实验包括:
- 数据集选择:
- 实验使用了三个公开的数据集:Foursquare-NYC、Foursquare-TKY和Gowala-CA。
- 基线模型比较:
- 与多个现有的推荐模型进行比较,包括FPMC、LSTM、PRME、STGCN、PLSPL、STAN、GETNext和STHGCN。
- 模型变体评估:
- 评估了三种不同的模型变体,包括仅使用当前轨迹块的LLAMA2-7b、加上历史轨迹块但不考虑关键查询相似性的LLAMA2-7b*,以及结合历史轨迹块和关键查询相似性的LLAMA2-7b**。
- 评估指标:
- 使用Accuracy@1作为主要的评估指标,即预测的准确性在推荐列表的第一位。
- 实验设置:
- 描述了实验的具体设置,包括数据预处理、训练集、验证集和测试集的划分,以及模型训练的超参数设置。
- 主要结果:
- 展示了在三个数据集上的实验结果,显示提出的模型在所有数据集上都显著优于基线模型。
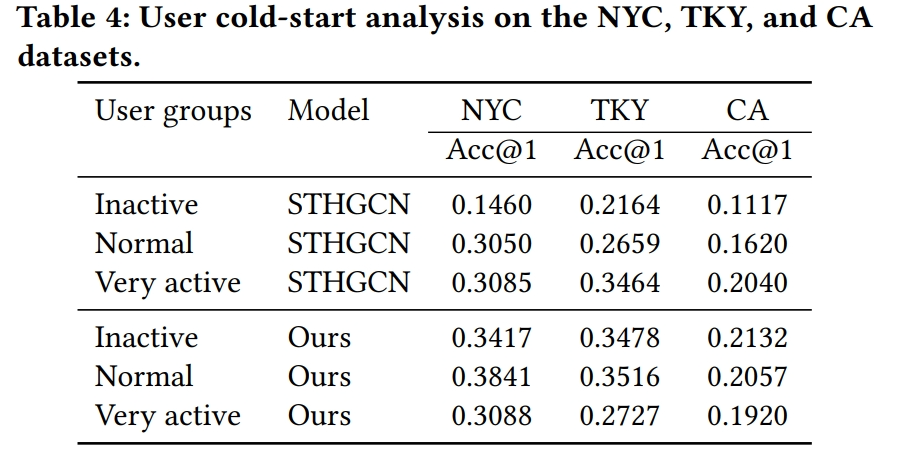
- 用户冷启动分析:
- 分析了模型对冷启动问题的处理能力,通过将用户分为活跃、正常和非活跃三组,比较了模型在不同用户群体上的性能。
- 轨迹长度分析:
- 探讨了轨迹长度对模型性能的影响,将轨迹分为长、中、短三类,并分析了模型在不同长度轨迹上的表现。
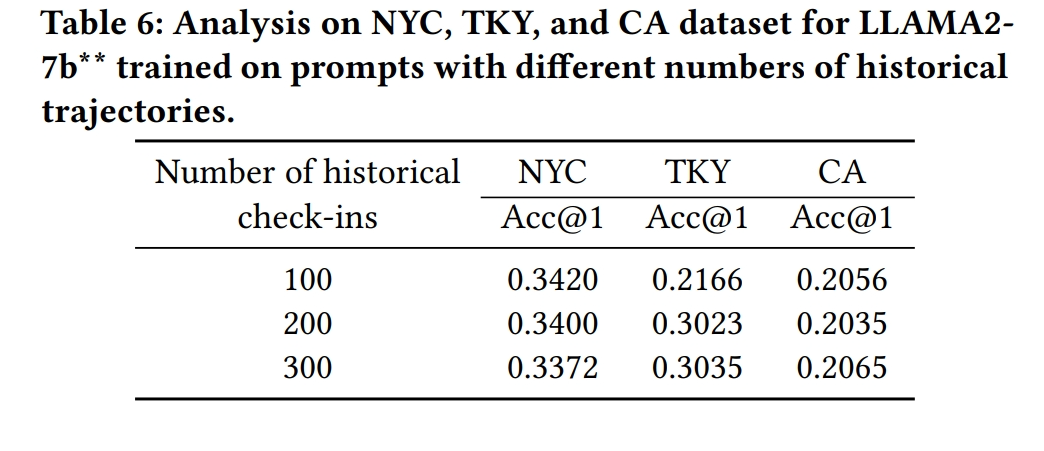
- 历史数据变体数量分析:
- 研究了在提示中使用不同数量的历史检查记录对模型性能的影响。
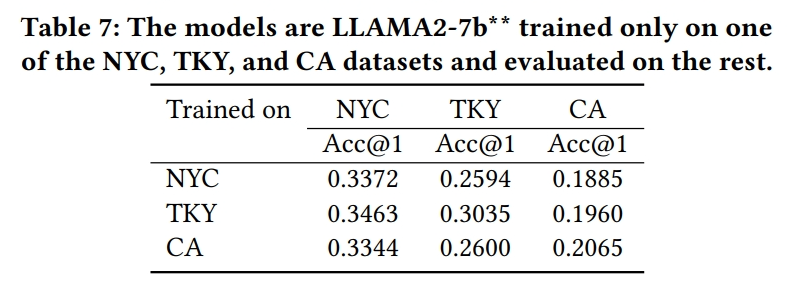
- 未见数据泛化分析:
- 评估了模型在未见过的数据集上的泛化能力,即在某个数据集上训练并在其他数据集上评估。
- 上下文信息分析:
- 分析了上下文信息在模型中的作用,通过在提示中移除POI类别名称的上下文信息来评估其对模型性能的影响。
- 不同组件效果分析:
- 通过去除历史轨迹块、关键查询相似性或上下文信息,来评估这些组件对模型性能的贡献。
这些实验全面评估了提出的框架在不同方面的表现,并与现有的推荐模型进行了深入的比较。通过这些实验,论文证明了其方法在处理冷启动问题、不同长度的轨迹、利用上下文信息以及泛化到未见数据方面的优势。




Q: 总结一下论文的主要内容
A: 这篇论文的主要内容概括如下:
- 问题定义:论文旨在解决如何利用位置基社交网络(LBSN)数据中的丰富上下文信息来提高下一个兴趣点(POI)推荐任务的性能。
- 挑战:现有的POI推荐方法在处理上下文信息时存在局限性,包括信息的数值化转换导致语义丢失,以及缺乏对上下文信息语义概念的理解。
- 方法:提出了一个基于预训练大语言模型(LLMs)的框架,通过轨迹提示(Trajectory Prompting)将POI推荐任务转化为问答任务,同时利用关键查询对相似性(Key-Query Pair Similarity)来缓解冷启动问题。
- 实验:在三个真实世界的LBSN数据集上进行实验,与多个基线模型相比,提出的框架在所有数据集上均显著提高了推荐性能。
- 分析:通过用户冷启动分析、轨迹长度分析、历史数据变体数量分析、未见数据泛化分析和上下文信息分析,展示了模型在处理不同用户行为和数据特性方面的有效性。
- 贡献:主要贡献包括提出了一个新的框架,利用预训练的LLMs来推荐下一个POI,以及一种新的基于提示的轨迹相似性方法。
- 未来工作:论文提出了未来工作的方向,包括效率优化、提示设计改进、链式思考推理、多步未来偏好推断、上下文信息的深入利用等。
型在处理不同用户行为和数据特性方面的有效性。 - 贡献:主要贡献包括提出了一个新的框架,利用预训练的LLMs来推荐下一个POI,以及一种新的基于提示的轨迹相似性方法。
- 未来工作:论文提出了未来工作的方向,包括效率优化、提示设计改进、链式思考推理、多步未来偏好推断、上下文信息的深入利用等。
- 结论:论文证明了利用LLMs进行下一个POI推荐任务的潜力,并展示了模型在未见数据上的泛化能力,同时指出了当前方法的局限性和未来改进的可能方向。
🌟【紧跟前沿】“时空探索之旅”与你一起探索时空奥秘!🚀
欢迎大家关注时空探索之旅
这篇关于AI论文速读 | 2024[SIGIR]基于大语言模型的下一个兴趣点推荐的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








