本文主要是介绍镭速如何做到数据同步文件及文件夹的ACL属性?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据文件同步时,除了要同步文件的内容,还要对文件的属性做同步。权限属性作为一个重要的文件属性,是属性同步的重中之重,控制着不同用户与用户组对文件和文件夹的访问权限。不同的操作系统有着自己不同的权限控制机制,对应着不同的文件权限属性,例如Linux系统中令人熟知的UGO属性。那么我们镭速为什么还需要引入ACL属性,或者说ACL属性相比UGO属性有什么样的优势呢?

UGO属性的局限
UGO(User, Group, Others)属性把文件和文件夹的访问用户简单的划分为了三类:属主(U)、属组(G)与其他用户(O),控制了三类用户对文件及文件夹的读、写、执行权限。这种简单的分类方式让UGO属性只能胜任一些简单的场景,在稍微复杂一些的场景下,其局限性就很快体现出来。
考虑这样一种情况,我们需要给不同的用户或用户组设置不同的权限。此时,如果使用UGO属性,我们是无法实现这种差异化的权限管理的。因为UGO属性只能对文件和文件夹的属组设置统一的权限,并且不支持对特定用户单独设置权限。为了解决这个问题,操作系统引入了ACL属性。

ACL属性——一种更细粒度的权限属性
ACL(Access Control List,访问控制列表)属性是一种用于精确描述文件和文件夹访问权限的属性,可以用来授予和剥夺特定用户与用户组对文件与文件夹的特定权限。我们以Linux系统为例,用test用户创建一个名为file的文件,并将它的UGO属性设置成属主、属组可读写,其他用户无权限:
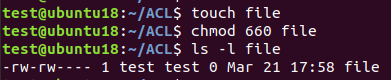
现在test用户和test组内用户都能够读写file文件,除此之外,其他任何用户都对该文件没有访问权限。我们再来看一下file文件的ACL属性:
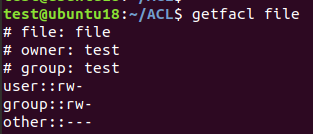
可见,ACL属性包含了UGO属性,前者是后者的一个超集。
接着,我们想要对file文件添加这样一种权限控制:针对系统中的wff用户(不在test组内),我们希望他也能对file文件具有读写权限,并且让wff用户组内的所有成员能够读取该文件:
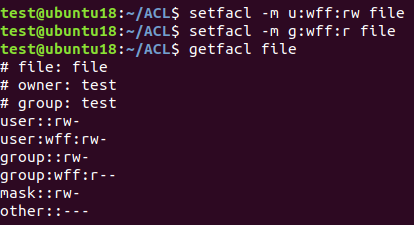
此时,使用简单的UGO属性已经无法满足我们的要求,但是使用ACL属性,我们可以很轻松的实现上述需求,从而达到更加细粒度的权限控制。
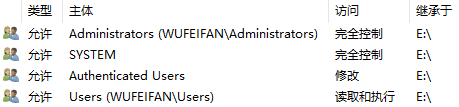
类似的,Windows也有属于自己的ACL权限管理机制:
国内

海外
文件夹的情况略有不同,比起文件其ACL属性有一些自身独特的机制。例如,文件夹可以设置其内部文件及子文件夹的默认ACL属性。

使用镭速文件传输系统同步ACL属性
如前所述,利用文件及文件夹的ACL属性,我们可以很方便的实现对用户及用户组更精确的权限控制。那么我们如何实现对ACL属性的同步呢?镭速文件传输系统(私有化部署方案,也可接入公有云,企业、社会组织用户可申请免费试用)提供了一套在相同操作系统间,方便快捷地进行ACL属性同步的解决方案。用户仅需要在创建同步任务时,通过UI或者命令行参数的形式,开启同步ACL属性的选项,即可实现对文件及文件夹的ACL属性同步。
这篇关于镭速如何做到数据同步文件及文件夹的ACL属性?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






