本文主要是介绍这世上又多了一只爬虫(spiderflow),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
让我们一起默念:
爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫爬虫
接着大声喊出来:
一!只!爬!虫!呀!爬!呀!爬!
爬!到!南!山!就!不!爬!啦!
怎么样,没想到吧? 这样的爬虫怕不怕?

好了,言归正传,到底又多了一只什么爬虫呢?
一、目标
为了分析国内上市公司的财务表现,需抓一批财务报告。
二、调研
上市公司财报哪家强? 要钱的统统走开,咱们只看以下几个source:
- 巨潮资讯
- 同花顺
- 东方财富
通过比较,博主选择了同花顺(仅供学习,别无它途哦)
三、实施
在正式实施前,强调一点,博主依然使用spiderflow作为利器,完成本次实践。
1. 打开财报页面
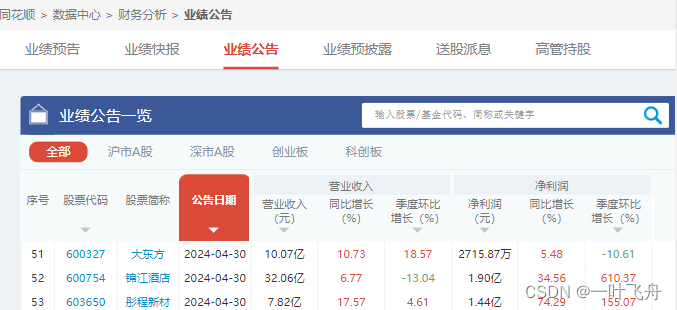
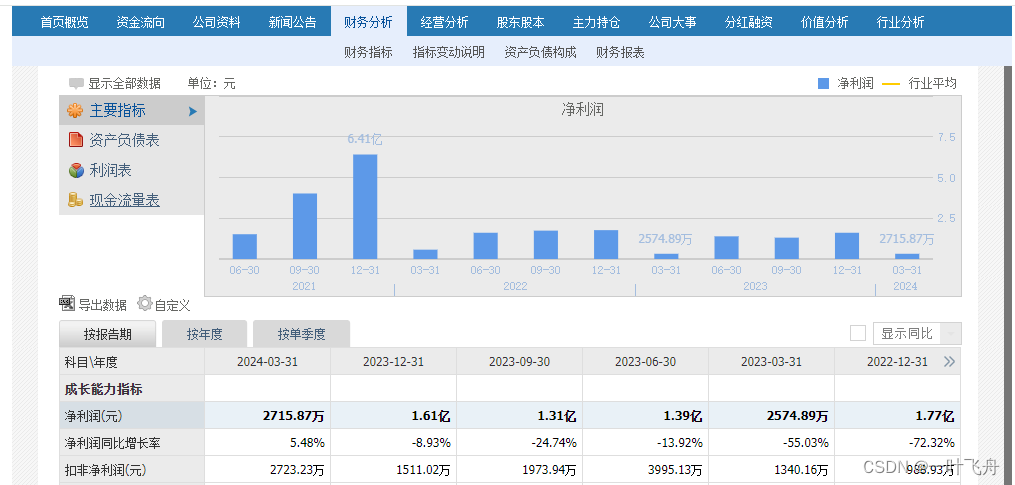
2. 分析财报页面
通过简单分析可知,财报数据是动态数据渲染而成。进一步抓包,可知来源于一个json文件: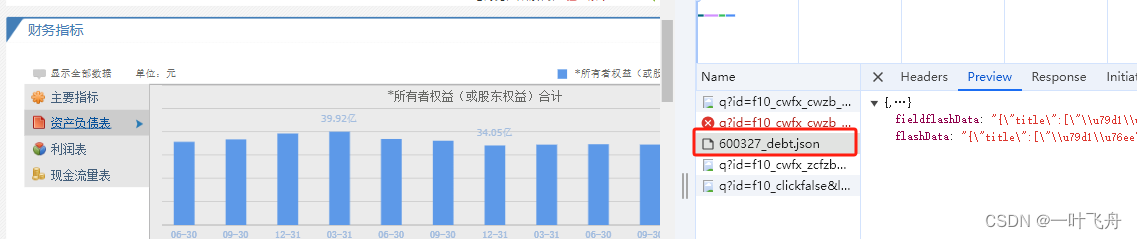
如此,遍简单了。爬起来~
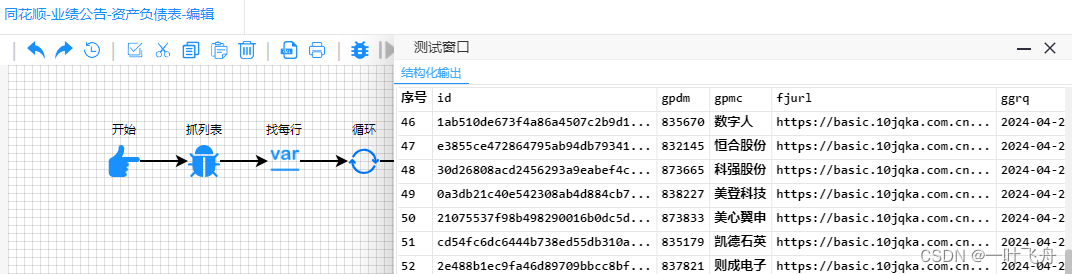
3. 新建一个爬虫
爬虫大致长这样:
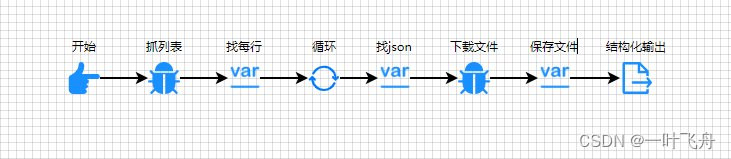
其中,关键一步是找json,需要指定类似以下的路径https://basic.10jqka.com.cn/api/stock/finance/600327_debt.json,红色数字代表上市公司代码,可作为一个变量进行替换。这样就能满足批量下载了。
到此,大功告成。值得一提,本文仅用于学习交流,切勿他用。

这篇关于这世上又多了一只爬虫(spiderflow)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







