本文主要是介绍技本功丨骚操作:教你如何用一支烟的时间来写个日志采集工具,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

袋鼠云日志团队
后端开发工程师


我放下了手中的键盘,陷入沉思,
作为一个优秀的程序猿最重要的就是
气~势~
泰山崩于前的镇~定~
我用最快的速度扫描了一遍现行的
filebeat、fluentd、flume、
scribe等解决方案,
发现,没有机会,
难道就这样放弃了吗?
不,没有什么可以难倒我良辰!

我从口袋里掏出一根烟,
在烟雾缭绕中我缓缓看向小马哥

如何唯一标识一个文件
从需求角度来讲,用户往往需要采集指定目录指定格式下的文件,常用方式是配置路径通配符,例如这样: /path/*/*.log,意思就是收集/path/a/web.log、/path/b/web_2018-12-11.log等日志。但是,用文件名来标识文件是不准确的,移动一个文件mv a.log b.log,虽然名称是变成了b.log,但实际日志依旧是a.log的日志,把b.log当做新文件处理就会出现采集到重复日志的问题。
那换成inode作为文件唯一标识怎么样?答案是,会好点。为啥是好一点而已呢,原因有2个,一是不同文件系统间的不同文件inode可以一样,二是同个文件系统下,不同时刻存在的文件inode可以一样。这2个问题都可以导致读取日志时的偏移量错乱问题,最终导致数据丢失或者数据重复。

那换成内容前缀的方式唯一标识怎么样?内容前缀指的是使用文件前N个字节作校验。很显然,这也是一个缓解的操作,因为不同日志依旧有出现相同校验码的情况。这里的校验码算法可以使用crc32或者adler32,后者相比前者可靠性弱一点,性能则是前者的2~3倍。
目前最靠谱的方式是通过inode+内容前缀的方式唯一标识文件,虽然没办法完全解决唯一标识文件的问题,但鉴于同个文件系统不同时刻产生的文件刚好内容前缀有相同的情况概率比较低,所以该方案已经符合业务使用了。
如何监听文件变化
当新增、删除、修改文件时,如果获知快速获知变化?一种方式是使用linux的inotify机制,文件发生变化会立马通知服务,这优点是实时性高,但缺点是相同通知过于频繁反而提高了开销,另外不是所有系统都含有inotify机制。另一种方式是用轮询,轮询的实时性会差点,因为考虑性能,一般轮训间隔在1s~5s,但好在简单且通用。
如何合并日志
有时用户有合并日志的需求,比较常见的就是异常堆栈信息,一行日志被换行符分割成了多行。因为日志都是有规范的,会按时间、日志等级、方法名、代码行号等信息顺序打印,那这里一个简单的处理方式就是使用正则匹配的方式来解决,按照匹配行作split划分日志。
但一些偏业务的日志,就不能简单地通过正则匹配了,这类日志的内容是存在着关联关系的,像订单信息,日志需要通过订单id进行关联的,但由于多线程并行写日志等原因,逻辑上存在关联的日志在物理上未必连续,所以要求合并逻辑具有"跳"行关联的能力,这时候可以利用可命名的正则捕获功能来处理,把捕获的字段作为上下文在上下游日志传递,把匹配的日志存到缓存统一输出即可。
如何实现高吞吐
批量化处理,一是日志读取批量化,虽然读取日志已经是顺序读了,但如果在读取时通过预读取提前把待读取的日志都读取出来放进buffer,这方式可以进一步提升性能。二是发送批量化,发送批量化的好处主要体现在2方面,一方面是提高压缩比,像日志这类存在大量重复内容的数据,数据越多压缩比越高,另一方面,降低了请求头部的大小占比,减少带宽的浪费。
异步化处理,文件监听、日志处理、日志发送3个模块解耦并异步化,数据及通知通过队列传递。
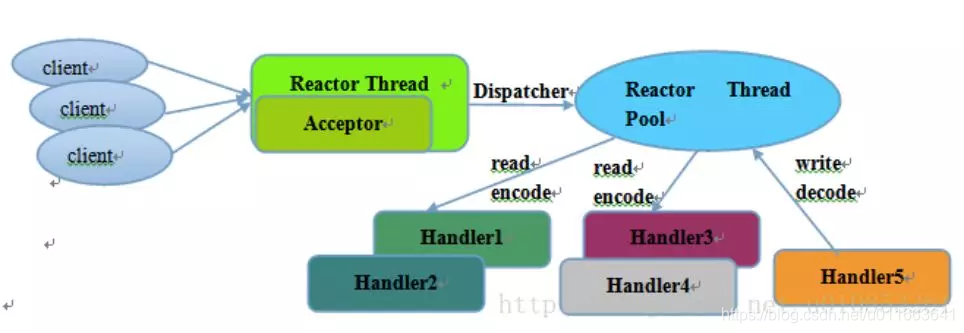
非阻塞发送,发送端要处理的常规操作包括参数校验、序列化、压缩、协议包装、ack、重试、负载均衡、心跳、校验和、失败回调、数据收发、连接管理。如果这系列操作都是由一个nio线程处理掉,发送效率肯定很低,但考虑到通常数据接收端数量不会太多(小于1000),所以这里使用reactor的多线程模型完全足够了,netty支持reactor多线程模型的,所以可以直接基于netty开发。这里只需要注意io线程除了连接管理,其余事情都交由工作线程处理就行。
如何实现资源控制
采集工具往往需要和待采集日志的系统放在同一个机器上,不少系统还对性能敏感的,这就要求采集工具必须有控制资源使用的能力。
如何控制句柄使用?句柄使用往往是被严格受限的,但如果机器需要监听上万上十万的文件时,如何使用句柄?这时候就需要采取惰性持有策略,即文件生成的时候不会持有句柄,只有尝试读取时再持有句柄,由于同时读取的文件往往不多,从而只会占用少量文件句柄。
另外,存在句柄引用的文件即便被删掉,空间是不会被释放掉的,导致长时间持有句柄是不是会有磁盘被打爆的风险?这就需要加上相应的定时释放句柄的机制,被删除的文件会加上一个时钟,时钟倒计时为0时把句柄释放掉。
如何控制内存使用?无论是日志的合并还是批量化操作,都需要使用较大的缓存,一旦缓存过大,就有oom的风险,所以需要机制控制内存占用。这里可以简单实现一个内存分配器,分配器内部维护一个计数器,用于记录当前分配内存大小。线程分配关键内存或者释放内存都需要请求内存分配器,内存超限则挂起请求的线程,并用等待/通知机制让线程协同起来。把分配内存的大户控制住,就可以控制住整体内存大小了。
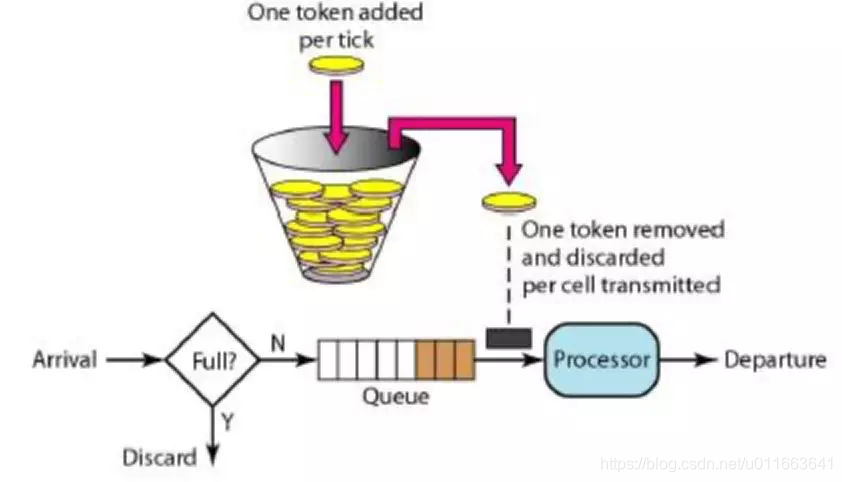
如何控制流量及cpu? 流量过大不仅占用多高带宽,而且流量与cpu占用也呈正比关系,所以控制流量的同时也就实现了cpu的控制。在固定窗口、滑动窗口、令牌桶、漏桶几个流控算法中,令牌桶和漏桶算法都可以令流速较为平滑,而且guava实现了令牌桶算法。这里直接使用guava的RateLimiter即可。
我看了一眼手上烧完的烟,
时间刚刚好。

良辰说
在实际应用中,仍旧会遇到各种各样的问题,一方面是来自于业务的扩展性需要,另一方面是随着集群的扩大,在数据热点、实时性、弹性负载均衡方面会遇到诸多复杂的挑战。本文仅提供开发采集工具常见问题的解决思路,更深入的细节需要读者实际去探索了。
这篇关于技本功丨骚操作:教你如何用一支烟的时间来写个日志采集工具的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





