本文主要是介绍不破坏预训练模型结构且与Lora微调后的模型等价,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
不破坏预训练模型结构且与Lora微调后的模型等价
- 一.原理
- 二.loss曲线
- 三.代码
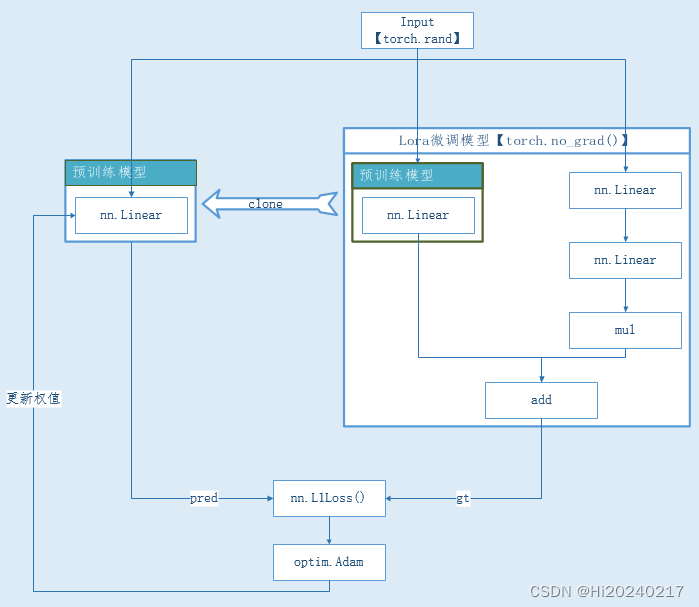
背景: Lora模块的引入破坏了图优化逻辑,是否能在不破坏原始的图的情况下,通过修改权值等价实现呢
方案: 将Lora的结果做为Ground True,去训练原始的Linear
小结: 方案虽然可行,但计算成本太高,Lora的初衷是减少微调的计算量
一.原理
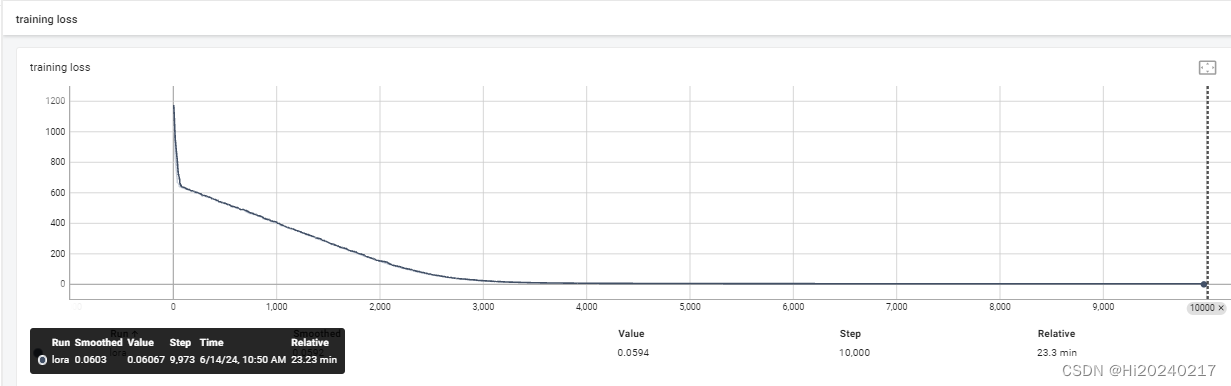
二.loss曲线
三.代码
import torch
import torch.nn as nn
import torch.optim as optim
import os
import numpy as np
from torch.utils.tensorboard import SummaryWriterclass PreTrainedModel(nn.Module):def __init__(self, input_dim, output_dim):super(PreTrainedModel, self).__init__()self.input_dim=input_dimself.output_dim=output_dimself.fc = nn.Linear(input_dim, output_dim)nn.init.normal_(self.fc.weight.data)nn.init.normal_(self.fc.bias.data)def forward(self, x):return self.fc(x)def clone(self):cloned_model = PreTrainedModel(self.input_dim,self.output_dim)cloned_model.load_state_dict(self.state_dict())return cloned_modelclass LoRALayer(nn.Module):def __init__(self, input_dim, low_rank_dim,lora_alpha=4.0):super(LoRALayer, self).__init__()self.U = nn.Linear(input_dim, low_rank_dim, bias=False)self.B = nn.Linear(low_rank_dim, input_dim, bias=False)self.lora_alpha=lora_alphann.init.normal_(self.U.weight.data)nn.init.normal_(self.B.weight.data)def forward(self, x):return x + self.B(self.U(x))*self.lora_alphaclass LoRAAdaptedModel(nn.Module):def __init__(self,input_dim,output_dim,low_rank_dim):super(LoRAAdaptedModel, self).__init__()self.pretrained_model = PreTrainedModel(input_dim,output_dim)self.lora = LoRALayer(output_dim, low_rank_dim)def clone_pretrained_model(self):return self.pretrained_model.clone()def forward(self, x):x = self.pretrained_model(x)x = self.lora(x)return xdef train():writer = SummaryWriter('runs/lora')input_dim = 128low_rank_dim=16output_dim=256torch.manual_seed(1)lora_adapted_model = LoRAAdaptedModel(input_dim,output_dim, low_rank_dim).cuda().eval()pretrained_model = lora_adapted_model.clone_pretrained_model().cuda()#criterion = nn.MSELoss()criterion = nn.L1Loss()optimizer = optim.Adam(pretrained_model.parameters(), lr=0.01)writer.add_graph(lora_adapted_model,torch.rand(32, input_dim).cuda())for epoch in range(10000000):running_loss = 0.0for i in range(100):input_data =torch.rand(8,input_dim,device="cuda")with torch.no_grad():gt=lora_adapted_model(input_data).detach()pred = pretrained_model(input_data)loss = criterion(pred,gt)optimizer.zero_grad()loss.backward()optimizer.step()running_loss += loss.item()avg_loss=running_loss / 100print('[%d] loss: %f' % (epoch + 1,avg_loss ))writer.add_scalar('training loss', avg_loss, epoch)running_loss = 0.0
train()
这篇关于不破坏预训练模型结构且与Lora微调后的模型等价的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








