本文主要是介绍使用langchain接入通义千问与知识图谱,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 大前提
- 准备工作
- 0. 找一个key
- 1. 手动部署
- 2. Docker部署
- 该怎么开始
- 用户的提问
- 问答历史
- 读取api-key
- 使用Streamlit构建页面框架
- Prompt知识库的植入
- Prompt知识库的执行
- Prompt知识库详细内容植入
- 更新布局
- 补全页面细节
前言
这一篇文章将尝试做一个缝合怪,把langchain、知识图谱以及qwen融合在一起,形成一个智能问答系统。其中,数据集将采用liuhuanyong老哥提供的以疾病为中心的一定规模医药领域知识图谱,同时教程将结合ranying666提供的控制台形式缝合教程以及Neo4j官方提供的网页形式缝合教程
最终产品就是这样的:点击跳转到我的GitHub中这个项目
如果想体验一下,也是没问题的:点击跳转到体验demo中
比较尴尬的是,服务器性能有限,经常挂掉,如果显示不可达,那应该是挂掉了。(首)
大前提
个人认为,Neo4j官方提供的网页形式缝合教程非常适合小白,一步步引导你如何使用Neo4j、streamlit、langchain、openai等工具,搭建一个基于Neo4j的LLM聊天机器人,并运行起来。
这个教程的前提有两个:
首先是你得有一个Neo4j的账号,免费注册一个即可。注册后就能够看到教程的详细内容。
其次是你的有一个ChatGPT的账号,而且还得给API付费,不光是ChatGPT的Plus套餐。如果只有Plus套餐,在后续将会报错,大意就是说api-key异常。
当你全部都准备好了,那就去学吧。如果你没有给API付费,那么你将停在教程的一半,就像我一样。不过幸运的是,即使只有一半,你也基本具备了langchain接入任何大模型的基本技能。所以,在这两个缝合教程的基础上,我再来一个究极缝合教程。
准备工作
我也学着Neo4j官方教程的样子,先给你一个准备好的库,大概可以直接运行,但是效果可能并不是很好。如果你已经熟读了源码,你会发现,这个大模型目前只能处理心肌炎相关的医疗问题。对于一些学习的人来说,这个方向实在是食之无味弃之可惜。
不说那么多啦,上链接!点击这里跳转到库。
0. 找一个key
是指你认为还行的大模型的api-key。这里我采用的通义千问,所以记录下来你在通义千问弄到的api-key。
使用方法就两种:
1. 手动部署
$ git clone https://github.com/sakebow/streamlit-tongyi # 下载库
$ cd streamlit-tongyi # 进入目录
$ pip install -r requirements.txt # 安装依赖
$ echo "DASHSCOPE_API_KEY=sk-x" > streamlit-tongyi/.env # 输入api-key
$ streamlit run bot.py # 运行
这样你就能够在localhost:8501看到一个streamlit的界面了,就像这样:
2. Docker部署
$ echo "DASHSCOPE_API_KEY=sk-x" > streamlit-tongyi/.env # 输入api-key
$ docker build -t tongyi/streamlit:v1 . # 构建镜像
$ docker run -d -p 8501:8501 tongyi/streamlit:v1 # 运行
这样你就能够在localhost:8501看到一个streamlit的界面了。
该怎么开始
那么这里面到底做了什么呢?我们来一个很直观的流程图:
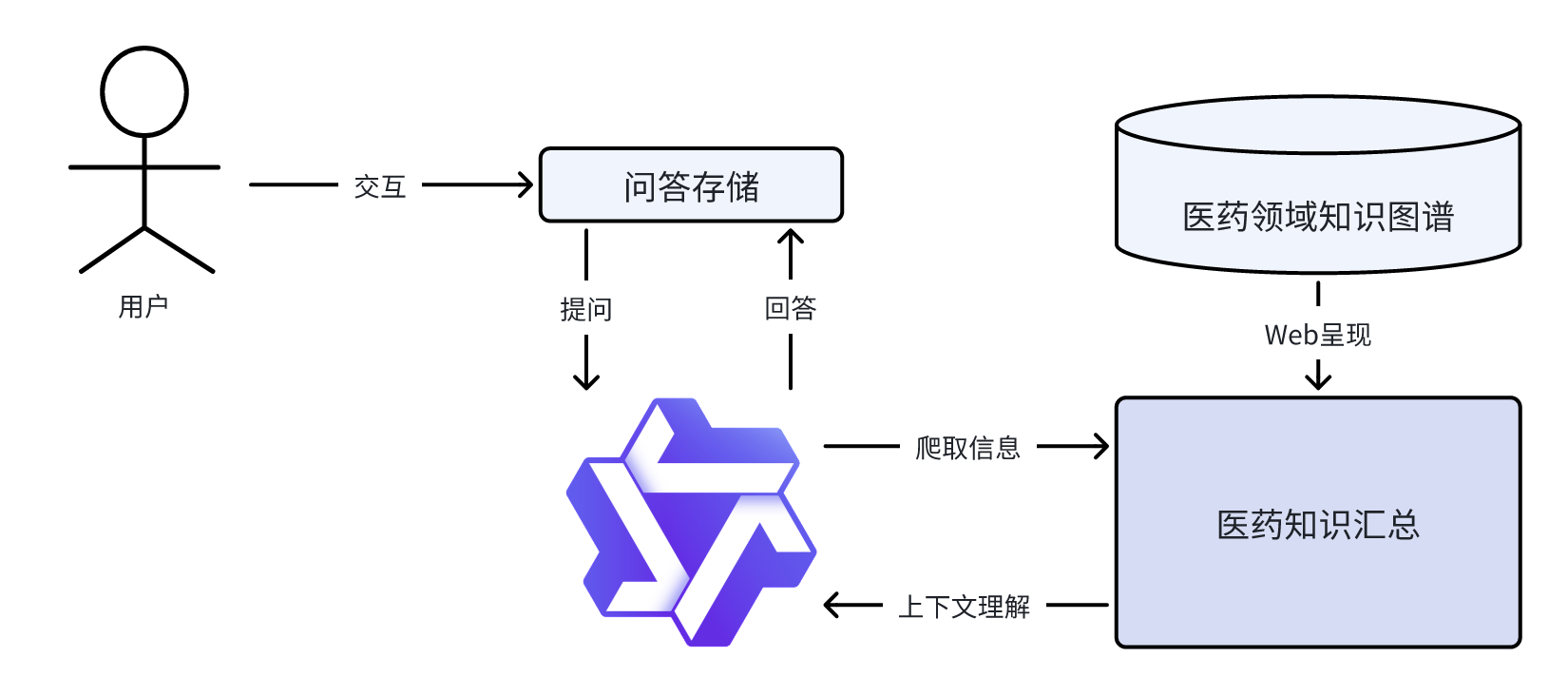
用户使用这个系统的时候,就是首先跟问答存储的部分互动。
互动开始后,问答存储的部分首先就为每一位用户维护一个session。然后,问答存储的部分就要去集齐三块拼图,分别是:
- 用户的提问
- 问答历史
- 拓展知识库
利用这三块拼图生成prompt,然后就交给大模型,大模型就开始针对这些上下文信息生成回答。
如果不考虑prompt为大模型带来的任何场景信息的话,这个prompt就可以直接简化为这样子:
prompt = """"
{用户的提问} {问答历史} {拓展知识库}
"""
当然,用中文看着怪怪的。不管三七二十一,总之把中文改成英文,应该就高大上了一些。于是,用human_input表示用户的提问,用chat_history表示问答历史,用text表示拓展知识库,于是就有:
prompt = """"
{human_input} {chat_history} {text}
"""
用户的提问
用户的提问跟大模型的回答,共同构成了问答的数据库。那么,我们应该怎么处理这些内容呢?当然,langchain很贴心的为我们准备了很丰富的工具,包括HumanMessage、AIMessage、SystemMessage、ChatMessage等。但那些都是后话了,我们不去想这么深入的东西,一步步来。
问答历史
问答历史,听着就像数据库一样。既然要保存数据库,那是不是得有一个类似memory、database的地方?没错,确实有一个,叫做langchain.memory.ConversationBufferMemory。
这个ConversationBufferMemory类本身具备human_prefix、ai_prefix以及memory_key三个属性,分别用来表示用户输入的前缀、大模型输出的前缀以及历史对话的前缀。这样的话,就能够按照默认的规则整理内容,从而让内容能够让人类能多少理得顺溜一点。比如,我输入Hello,那么经过这个ConversationBufferMemory类之后,就会变成Human: Hello,然后大模型输出Hello,就会变成AI: Hello。整理起来就成了:
["Human: Hello","AI: Hello"
]
他在代码中有什么实际作用吗?抱歉,在简单使用的场景下,确实没有什么用。在使用场景更为复杂的地方可能就有用了。
除了这个以外,该类继承自BaseChatMemory,也就继承了input_key属性。这个属性比较有意思的是,可以指定用户输入的部分是什么。
在很多教程中都不会说明这个字段,因为他是从父类继承下来的,不是自己直接就有的,而且这么设计有一个最神奇的用法,就在于:
如果你的prompt只有 2 2 2个变量,那么它就不必要存在。
怪不得大家都不会写这个参数呢。
当然这个也算好的,因为还有更坏的。还记得memory_key吗?还记得他的默认值是history对吧?所以,离谱就在于:
如果你的问答历史用的变量叫做history,那么它就不必要存在。
如果你是防御型编程选手,把变量名全都改成默认,然后省掉所有参数,确实就像把天真烂漫的新人拉进米奇♂妙妙屋一样(哦, 夜♂色)。
好像扯远了。
总之,在现在需要至少 3 3 3个拼图的需求下,最好还是区分好input_key,否则,除了chat_history以外的所有变量会全部塞进input_key,然后爆炸(raise Error)。
最好还是给定一个hunman_input变量,就像这样:
memory = ConversationBufferMemory(memory_key="chat_history", input_key="human_input")
读取api-key
首先,我们采用load_dotenv加载.env文件,获取到了api-key。
需要注意的是,load_dotenv对应的文件是项目根目录下的.env,或者与脚本同目录下的.env文件。
如果你在其他地方看到的是使用.streamlit/secrets.toml文件,这个是streamlit读取的默认配置文件。
还有用os设置环境变量的,比如:
os.environ["OPEN_API_KEY"] = "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
从结果上来说,这些都是完全相同的。
就跟穿秋裤一样,有些人喜欢穿一套的,所以前前后后整整齐齐的streamlit;有些人并不在意是不是一套,所以直接东拼西凑,毕竟最终的功能是要保暖。
P.S.:这个方法读取
api-key的效果并不是很稳定,有可能会突然就找不到api-key然后就报错。
使用Streamlit构建页面框架
然后,我们采用streamlit构建了一个基本的页面框架,就像写markdown一样轻松。
首先设置标题,也就是<head>标签下的<title>与<link rel="icon">标签:
st.set_page_config("Ebert", page_icon=":movie_camera:")
然后,在启动的时候为大模型提供一个问好的内容:
if "messages" not in st.session_state:st.session_state.messages = [{"role": "assistant","content": "Hi, I'm the GraphAcademy Chatbot! How can I help you?"},]
若存在session信息,则继续追加,否则重新启动一段对话。
当streamlit完成页面的搭建之后,就能够出现一个基本的页面了。
Prompt知识库的植入
这个部分也就是最后我们需要植入的text。如何理解这个text呢?我们以本文提到的医学领域为例。比方说我们现在需要让大模型回答心肌炎相关的问题,那么我们就只需要将心肌炎相关的内容给一个文本就好了。最简单的,就是令text=${心肌炎相关内容}。
当然,一般的产品需要有一定的灵活性,这个时候,我们就可以用web技术,将难以微调、难以prompt的知识库,提供一个网络访问接口,然后利用爬虫技术赋予text内容。
如何赋予呢?langchain贴心地为我们提供了接口,也就是langchain.chains.combine_documents_chain.stuff.StuffDocumentsChain。
这个类给出了一个注释:
This chain takes a list of documents and first combines them into a single string.
It does this by formatting each document into a string with the
document_promptand then joining them together withdocument_separator.It then adds that new string to the inputs with the variable name set by
document_variable_name.Those inputs are then passed to the
llm_chain.
大致意思就是,文件将通过document_variable_name输入这个chain。进一步地,这个chain将文件列表整理为一长串字符串,然后将每一个包装为一个prompt。把每一个prompt连起来,两两之间用一个分隔符分开,形成一个超级巨大的prompt,作为llm_chain的输入。
听不太懂?官方注释甚至贴心地给你了一个小案例:
from langchain.chains import StuffDocumentsChain, LLMChain
from langchain_core.prompts import PromptTemplate
from langchain_community.llms import OpenAI# This controls how each document will be formatted. Specifically,
# it will be passed to `format_document` - see that function for more details.
document_prompt = PromptTemplate(input_variables=["page_content"],template="{page_content}"
)
document_variable_name = "context"
llm = OpenAI()
# The prompt here should take as an input variable the
# `document_variable_name`
prompt = PromptTemplate.from_template("Summarize this content: {context}"
)
llm_chain = LLMChain(llm=llm, prompt=prompt)
chain = StuffDocumentsChain(llm_chain=llm_chain,document_prompt=document_prompt,document_variable_name=document_variable_name
)
所以,基本上使用StuffDocumentsChain就足够植入文档了。
Prompt知识库的执行
在完成知识库植入之后,就是执行的时候了。针对StuffDocumentsChain,我们只需要调用他的run方法即可:
response = stf_chain.run(human_input = message,chat_history = st.session_state.messages if st.session_state.messages else "",input_documents = load_documents(input_documents)
)
write_message('assistant', response)
run方法需要三个重要参数:
human_input:用户最新一次的提问;chat_history:以往的交互记录;input_documents:知识库的文字内容;
其中需要格外注意的是,input_documents需要的是Document类的对象列表。什么才是Document类的对象列表呢?就像这样:
from langchain.schema import Document
response = stf_chain.run(human_input = message,chat_history = st.session_state.messages if st.session_state.messages else "",input_documents = [Document(page_content="text1"), Document(page_content="text2")]
)
而如果需要异步获取文档的话,则在获取的过程中需要额外将文本转变为Document类型,即[Document(page_content="text from api")]。当然,这个过程已经封装在html2text库中了。
Prompt知识库详细内容植入
需要说明的是,在植入文档的过程中,有这么两个选项,一个是异步获取文档,一个是直接输入文档。
直接输入文档无非就是直接写死,当然也有很多其他的方法。不过这类更适合确认的模板。
而异步获取需要通过http获取。这个里面有一个很大的坑:多线程。
因为streamlit是单线程的,所以异步获取的时候,streamlit会直接报错,因为有时候数据会没在streamlit到达业务逻辑之前到达,那就导致对象为空,或者接口未实现。这种问题其实很难找到。
那么,异步获取的过程就是阻塞进程的过程。
有关Python的协程(coroutine)已经有很多说明了。我们需要借助类似asyncio等带有awaitable属性的库,用于创建一个新的线程,并且利用asyncio中的run_until_complete方法来阻塞进程。
这个过程将依靠futures类创建一个进程锁,所有的进程都将等待这个锁的释放。无论这个唯一正在运行的进程是成功了还是报错了,最终都将释放锁,从而解放其他的进程。
于是呢,这个进程对web的接口性能带来了较大的考验。如果是数据量极大、消耗时间极长的接口,往往会造成很多因为时间片过长而初始化失败的问题。
更新布局
在每次大模型回答出问题以及用户提起新问题的过程中,都将为chat_history增加新记录,这个新纪录将需要在streamlit页面中更新。无论是哪个角色更新了页面中的详细页面:
def write_message(role, content, save=True):if save:st.session_state.messages.append({"role": role, "content": content})with st.chat_message(role):st.markdown(content)# Display messages in Session State
for message in st.session_state.messages:write_message(message['role'], message['content'], save=False)
补全页面细节
为了接收用户输入,我们需要利用streamlit的输入框:
st.chat_input("Yo, what's up, bro?")
其次,这个函数将返回用户的输入,所以用一个变量接收:
prompt = st.chat_input("Yo, what's up, bro?")
然后,我们将用户的输入更新到页面上:
write_message('user', prompt)
然后我们就使用stf_chain返回一个结果,然后更新页面:
def handle_submit(message):response = stf_chain.run(human_input=message,chat_history="",input_documents=load_documents(url))write_message('assistant', response)handle_submit(prompt)
当然,有些教程还会提到给一个非常人性化的加载显示:
def handle_submit(message):with st.spinner('Thinking...'):response = stf_chain.run(human_input=message,chat_history="",input_documents=load_documents(url))write_message('assistant', response)
再加上我们还有海象运算符:=,就可以更简单:
if prompt := st.chat_input("Yo, what's up, bro?"):write_message('user', prompt)handle_submit(prompt)
就是这样啦。
这篇关于使用langchain接入通义千问与知识图谱的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




