本文主要是介绍YOLOv10在RK3588上的测试(进行中...),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.代码源
国内镜像站在gitcode。这个镜像站也基本上包含了github上常用项目的镜像。然后它的主发布源在这里:
GitCode - 全球开发者的开源社区,开源代码托管平台
yolov10是清华主导做的...
然后,在维护列表里看到了这个:
- 2024年05月31日:感谢kaylorchen整合rk3588!
2.三方性能评价

kaylorchen的yolov8 yolov10在3588平台的自测数据在这里(单位ms):
| V8l-2.0.0 | V8l-1.6.0 | V10l-2.0.0 | V10l-1.6.0 |
|---|---|---|---|
| 133.07572815534 | 133.834951456311 | 122.992233009709 | 204.471844660194 |
| V8n-2.0.0 | V8n-1.6.0 | V10n-2.0.0 | V10n-1.6.0 |
|---|---|---|---|
| 17.8990291262136 | 18.3300970873786 | 21.3009708737864 | 49.9883495145631 |
从FLOPs的数据看,相应的-l和-n的识别时间近似与yolov10公布的性能参数对照表保持一致。
3.实测(处理中...)
看到官方公布的模型特征,我最终选取的应该不是-n而是-s,实际部署时还会考虑-m
3.1 环境的建立
3.2 配置
3.3 模型训练
3.4 部署
3.5 实测数据
附录A epochs对模型识别精度的影响
这张图参见:
简述YOLOv8与YOLOv5的区别_yolov8和yolov5对比-CSDN博客
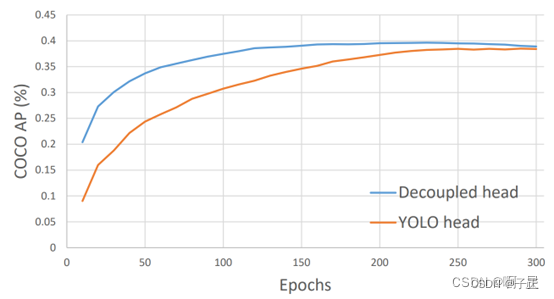
我因为在i5-12400上跑的实在是太慢,然后做实验时往往跑了两遍就结束了。看起来之后训练的遍数还得定在200~250次。普通的I5芯片,COCO数据集需要跑4~5天才能跑完。
看上面的数据点:训练集跑10遍,达到的识别精度大概是最终可能精度的25%...它在逐渐收敛。在蓝色的优化方法的末端,你能看到那个以为过度训练造成的识别精度下降的现象。机器学习的识别过程类似一个反馈环,识别效果出现震荡是正常的。
这篇关于YOLOv10在RK3588上的测试(进行中...)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



