本文主要是介绍论文笔记:ATime-Aware Trajectory Embedding Model for Next-Location Recommendation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Knowledge and Information Systems, 2018
1 intro
1.1 背景
- 随着基于位置的社交网络(LBSNs),如Foursquare和Facebook Places的日益流行,大量用户签到数据变得可用
- 这些大量签到数据的可用性带来了许多有用的应用,以提升基于位置服务的用户体验
- 其中一个任务是新兴的下一个位置推荐
- 下一个位置推荐根据用户过去的签到记录,预测可能访问的后续位置
- 时间信息在这个任务中扮演了重要角色
- 例如,如果访问时间是工作日的早晨,用户从“家”开始访问“地铁”,然后“办公室”(或工作地点)应该是对这位用户的合适推荐
- 如果访问时间是周末,则应推荐放松的地点
- 时间信息在这个任务中扮演了重要角色
1.2 现有的工作
- 现有的下一个位置推荐研究主要基于马尔可夫链属性模型连续签到之间的序列转换模式。
- 由于数据稀疏性和计算复杂性,序列转换限制于一阶转换,无法捕捉更长的序列上下文。
- 更重要的是,推荐任务中缺乏对多种时间因素的全面和深入考虑。
- 在现有研究中,用户偏好通常被视为静态的,这并不反映用户兴趣的演变特征
- 例如,学生可能在学期期间更频繁地在大学签到,而在作为某公司夏季实习生时则更频繁地在工作场所签到
- ——>她的签到行为在不同时间段内发生变化
- 例如,学生可能在学期期间更频繁地在大学签到,而在作为某公司夏季实习生时则更频繁地在工作场所签到
- 现有研究也忽略了周期性模式
- 例如,在工作日,用户可能早上在办公室签到,晚上在家签到
1.3 下一位置推荐的挑战性
- 首先,如上例所示,用户的签到行为会随时间改变
- 其次,即使我们能够根据用户推导出访问模式(例如,周末“家”→“商店”→“午餐”→“商店”→“晚餐”),仍然很难推断出每个模式的确切位置
- 因为多个候选位置可能适合
- 晚餐的下一个位置应基于多种考虑生成,包括自己的偏好、之前访问过的地点和其他时间因素
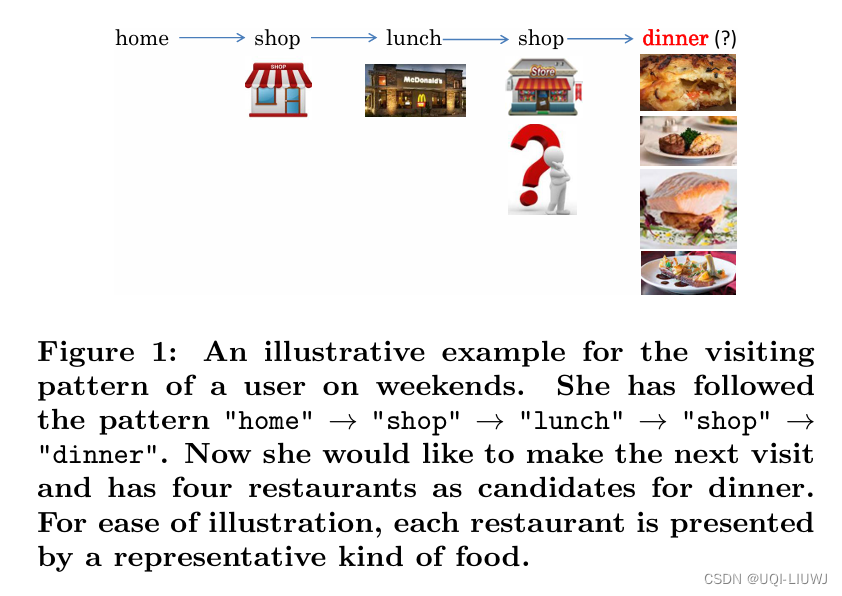
- 因为多个候选位置可能适合
1.4 论文思路
- 提出了一个新颖的时间感知轨迹嵌入模型(TA-TEM)
2 轨迹观察
- 如之前的论文所言,序列影响是轨迹数据中最重要的时间因素之一,即用户连续签到点之间存在马尔可夫链特性。
- 论文研究实际轨迹数据上的另外两种时间因素。
2.1 数据集
- 三个公共地理社交网络数据集,每个数据集包含一年的签到数据
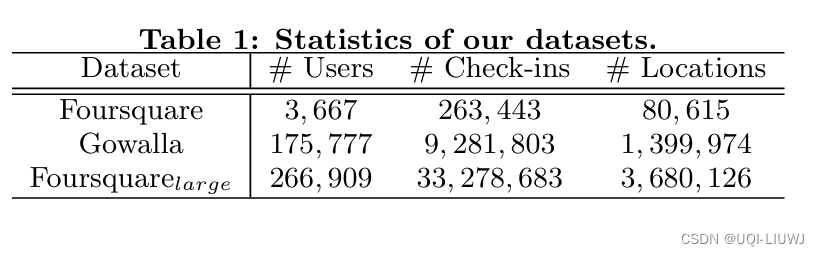
仅报告Gowalla数据集的结果,其他两个数据集的观察结果类似
2.2 观察1:用户对签到的偏好会随着长时间周期(例如,一个月)的变化而变化
- 直观地说,用户的兴趣可能会在一段时间后发生变化(例如,一个月),这可能导致不同时间段的访问行为不同
- 给定一个用户u,论文通过计算两个连续时间周期中u访问的位置集合的Jaccard相似度的平均值来计算重叠比率值(ORV)。
- 设置一个时间周期为一个月
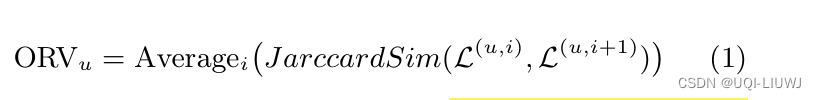
- 在上述等式中,L(u,i)是用户u在第i个月访问的位置集合
- 选择签到记录最多的前1000名用户,然后计算这些用户的平均ORV
- 设置一个时间周期为一个月
- 平均ORV是0.035(±0.002)
- ——>小的Jaccard相似性值表明,在连续两个月中用户的签到位置之间的重叠很少。
- 换句话说,用户对签到行为的偏好在长时间周期内会发生变化
2.3 观察2:周期性签到模式显著
- 直观地说,用户可能有一些规律的日常和周常活动,如中午吃饭和周末放松。
- 因此,位置的生成很可能会受到相应时间信息的影响,如一天中的小时和一周中的天
- 周常模式:
- 将轨迹分成按天的多个间隔,然后将所有用户在第i个间隔访问的位置组合成一个位置集合L(i)【一个簇】
- 计算这七个簇中两个位置集合的平均内部和外部相似性
- 内部和外部表示位置集合来自同一个和不同的簇
- 使用Jaccard系数来测量两个位置集合之间的相似性
- 将轨迹分成按天的多个间隔,然后将所有用户在第i个间隔访问的位置组合成一个位置集合L(i)【一个簇】
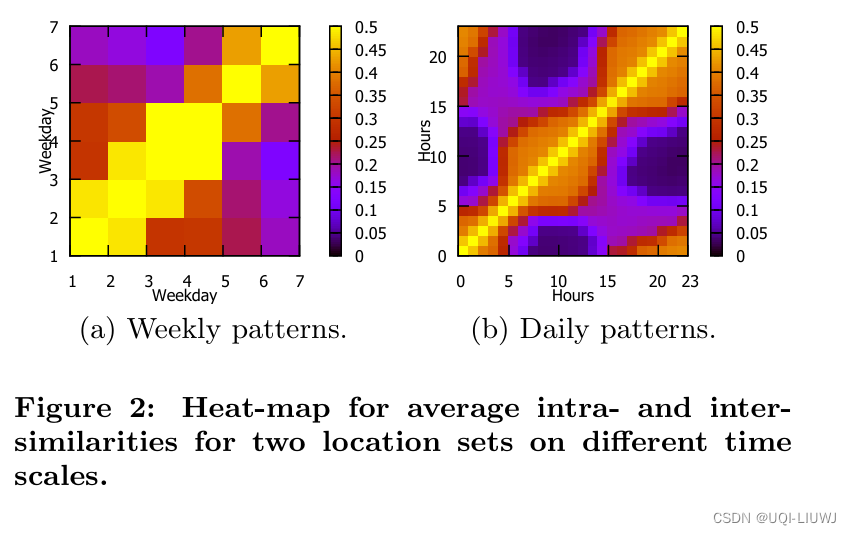
- 对角线条目的Jaccard系数显著高于非对角线条目
- ——>在一周内同一时间索引生成的两个位置集合比不同时间索引的更相似
- 基于小时索引进行类似的分析,结果绘制在图2(b)中,发现用户轨迹显示出有趣的时间模式
3 方法
3.1 轨迹嵌入:基本模型
- 类似于word2vec
- 位置j,窗口大小2K的上下文嵌入:
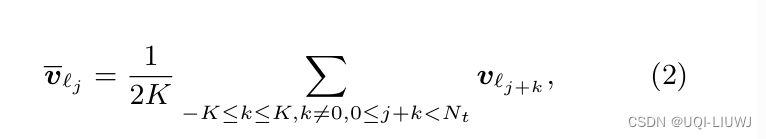
- 轨迹t的目标函数
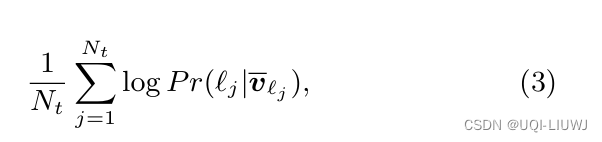
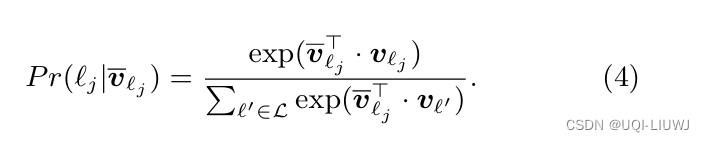
3.2 整合用户偏好变化
- 用户在签到时的偏好可能随时间变化(见观察1)
- 为了建模这一因素,论文将签到分为若干个月份,并假设用户u在第m个月与一个独特的人格vum相关联。
- 这里使用“人格”一词是为了反映用户随时间变化的偏好。
- 除了偏好变化外,还假设用户对位置有一个相对稳定的总体偏好,这有助于生成常去的地点,如工作场所和家

3.3 整合周期性模式
- 周期性签到模式描绘了观察2中提到的每周和每日的移动模式
- 当用户生成轨迹时,他的行为不仅受到自己的偏好影响,还受到周期性偏好的影响。
- 设hj和dt分别为轨迹t中第j个位置的一天中的小时索引和一周中的天索引。形式上,我们有:
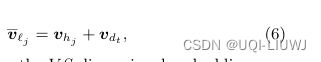
3.4 TA-TEM 模型
目标函数更新为:
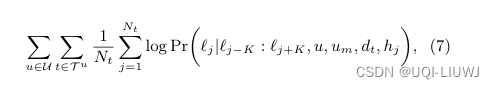
位置lj的上下文嵌入为:
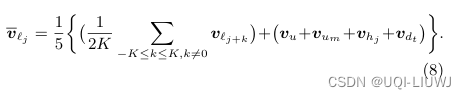
3.5 推荐位置排名
一旦所有嵌入向量都学习完成,我们按以下方式生成下一个位置推荐
- 给定用户u的前K个签到1,2,…,K1和下一个时间戳sK+1(对应于月份m、天d和小时h),使用以下函数来排名候选位置L:
4 实验
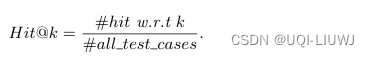
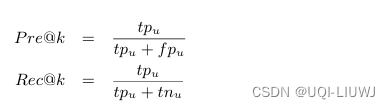
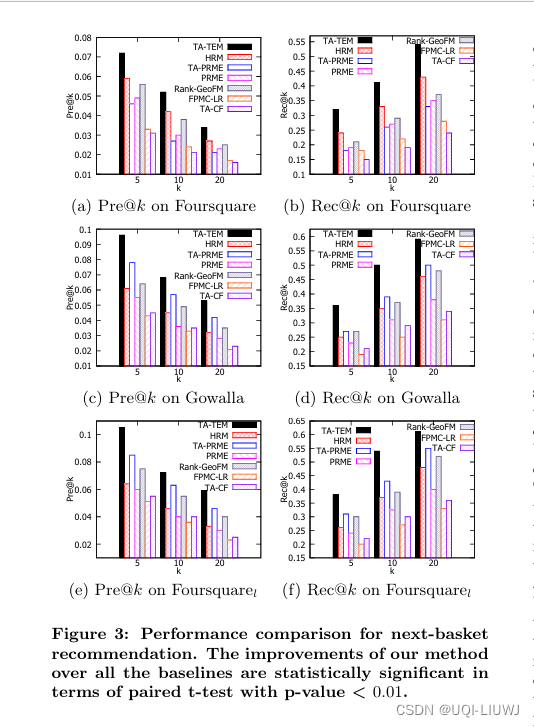
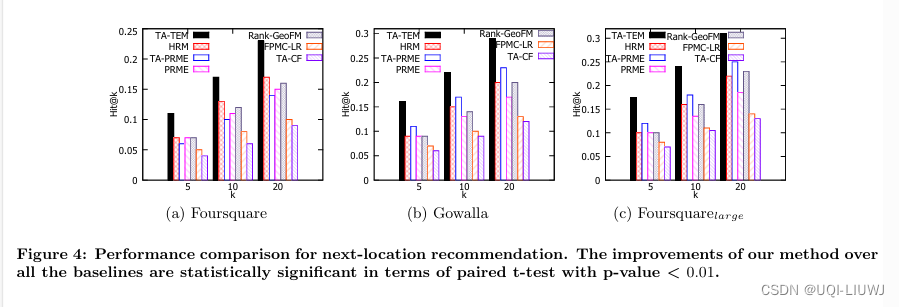
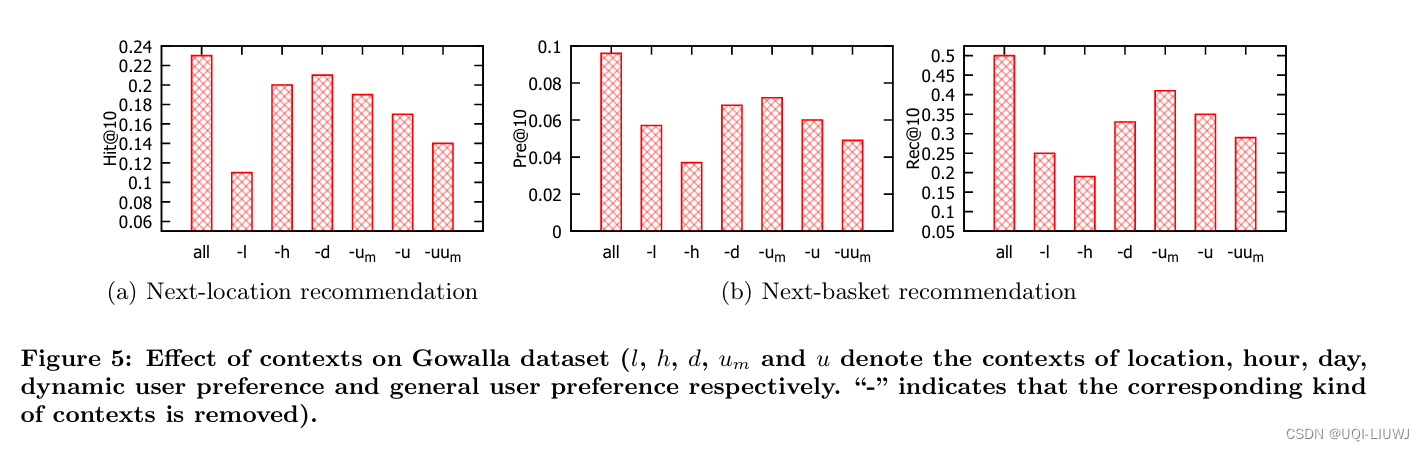
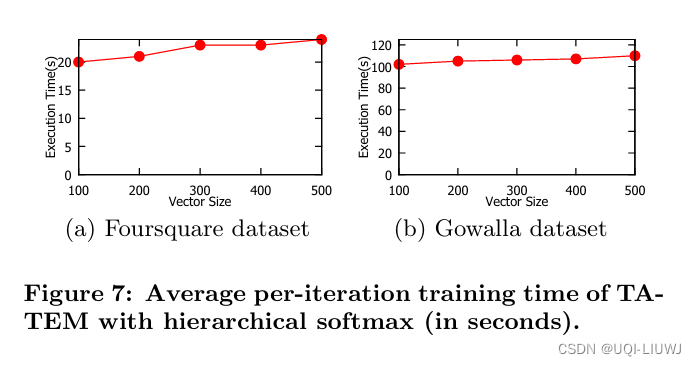
这篇关于论文笔记:ATime-Aware Trajectory Embedding Model for Next-Location Recommendation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




