本文主要是介绍pandas数据合并与重塑---concat方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
谈到pandas数据的行更新、表合并等操作,一般用到的方法有concat、join、merge。但这三种方法对于很多新手来说,都不太好分清使用的场合与用途。今天就pandas官网中关于数据合并和重述的章节做个使用方法的总结。
1、concat
- 1
- 2
参数说明
objs: series,dataframe或者是panel构成的序列lsit
axis: 需要合并链接的轴,0是行,1是列
join:连接的方式 inner,或者outer
其他一些参数不常用,用的时候再补上说明。
1.1 相同字段的表首尾相接
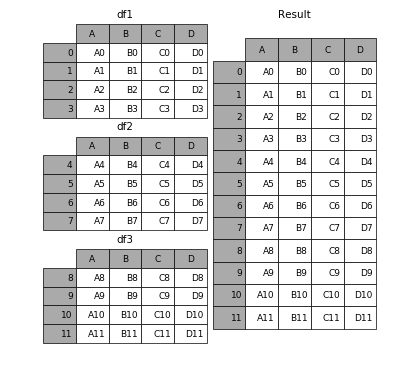
- 1
- 2
- 3
- 4
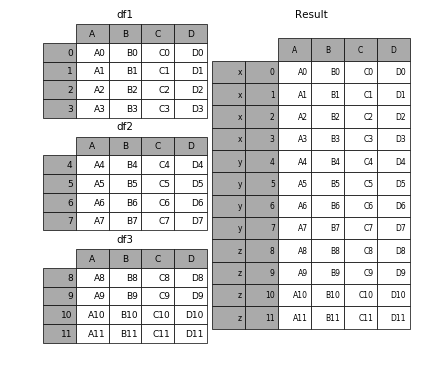
要在相接的时候在加上一个层次的key来识别数据源自于哪张表,可以增加key参数
- 1
效果如下
1.2 横向表拼接(行对齐)
1.2.1 axis
当axis = 1的时候,concat就是行对齐,然后将不同列名称的两张表合并
- 1
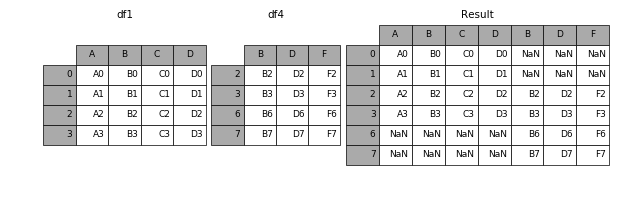
1.2.2 join
加上join参数的属性,如果为’inner’得到的是两表的交集,如果是outer,得到的是两表的并集。
- 1
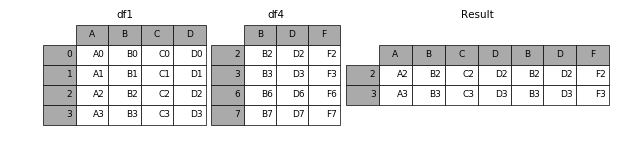
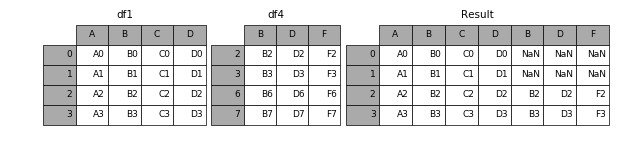
1.2.3 join_axes
如果有join_axes的参数传入,可以指定根据那个轴来对齐数据
例如根据df1表对齐数据,就会保留指定的df1表的轴,然后将df4的表与之拼接
- 1
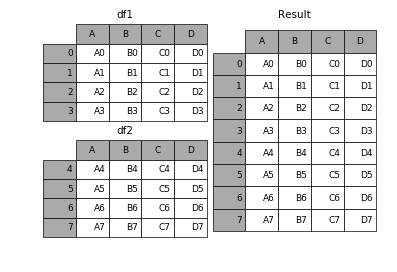
1.3 append
- 1
- 2
- 1
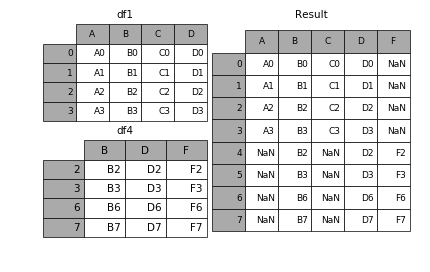
1.4 无视index的concat
如果两个表的index都没有实际含义,使用ignore_index参数,置true,合并的两个表就睡根据列字段对齐,然后合并。最后再重新整理一个新的index。
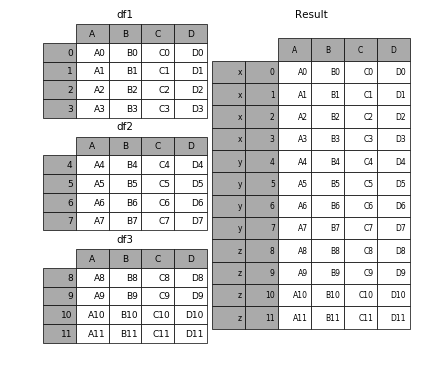
1.5 合并的同时增加区分数据组的键
前面提到的keys参数可以用来给合并后的表增加key来区分不同的表数据来源
1.5.1 可以直接用key参数实现
- 1
1.5.2 传入字典来增加分组键
- 1
- 2
- 3
1.6 在dataframe中加入新的行
append方法可以将 series 和 字典就够的数据作为dataframe的新一行插入。
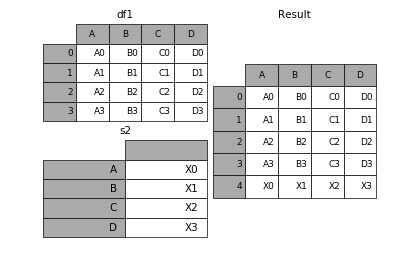
- 1
- 2
- 3
表格列字段不同的表合并
- 1
- 2
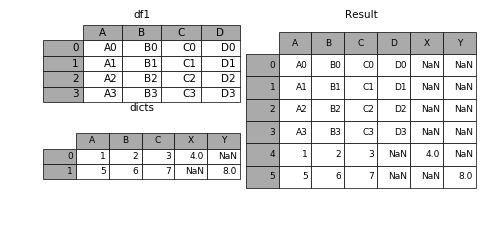
- 1
- 2
- 3
- 4
- 5
这篇关于pandas数据合并与重塑---concat方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





