本文主要是介绍深度学习500问——Chapter10:迁移学习(3),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
11.3 迁移学习的常用方法
11.3.1 数据分布自适应
11.3.2 边缘分布自适应
11.3.3 条件分布自适应
11.3.4 联合分布自适应
11.3.5 概率分布自适应方法优劣性比较
11.3.6 特征选择
11.3.7 统计特征对齐方法
11.3 迁移学习的常用方法
11.3.1 数据分布自适应
数据分布自适应(Distribution Adaption)是一类最常用的迁移学习方法。这种方法的基本思想是,由于源域和目标域的数据概率分布不同,那么最直接的方式就是通过一些变换,将不同的数据分布的距离拉近。
图19 形象地表示了几种数据分布的情况,简单来说,数据的边缘分布不同,就是数据整体不相似。数据的条件分布不同,就是数据整体相似,但是具体到每个类里,都不太相似。
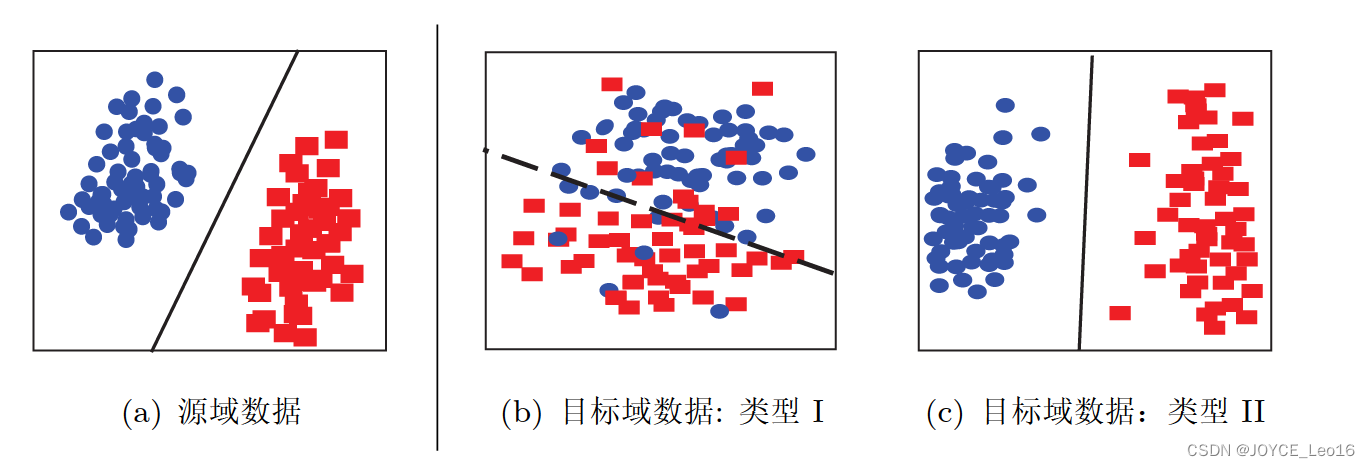
图19 不同数据分布的目标域数据
根据数据分布的性质,这类方法又可以分为边缘分布自适应、条件分布自适应以及联合分布自适应。下面我们分别介绍每类方法的基本原理和代表性研究工作。介绍每类研究工作时,我们首先给出基本思路,然后介绍该类方法的核心,最后结合最近的相关工作介绍该类方法的扩展。
11.3.2 边缘分布自适应
边缘分布自适应方法(Marginal Distribution Adaption)的目标是减小源域和目标域的边缘概率分布的距离,从而完成迁移学习。从形式上来说,边缘分布自适应方法是用P(Xs)和 P(Xt)之间的距离来近似两个领域之间的差异。即:
边缘分布自适应对应于图19中由图19(a) 迁移到 图19(b)的情形。
11.3.3 条件分布自适应
条件分布自适应方法(Condational Distribution Adaptation)的目标是减小源域和目标域的条件概率分布的距离,从而完成迁移学习。从形式上来说,条件分布自适应方法是用 P(ys|Xs) 和 P (yt|Xt)之间的距离来近似两个领域之间的差异。即:
条件分布自适应对应于图19中由19(a) 迁移到 图19(c)的情形。
目前单独利用条件分布自适应的工作较少,这种工作主要可以在[Saito et al.,2017]中找到。最近,中科院计算所的Wang等人提出了STL方法(Stratified Transfer Learning)[Wang et al.,2018]。作者提出了类内迁移(Intra-class Transfer)的思想,指出现有的绝大多数方法都只是学习一个全局的特征变换(Global DomainShift),而忽略了类内的相似性。类内迁移可以利用类内特征,实现更好的迁移效果。
STL方法的基本思路如图所示,首先利用大多数投票的思想,对无标定的位置行为生成伪标;然后在再生核希尔伯特空间中,利用类内相关性进行自适应地空间降维,使得不同情境中的行为数据之间的相关性增大;最后,通过二次标定,实现对未知标定数据的精准标定。
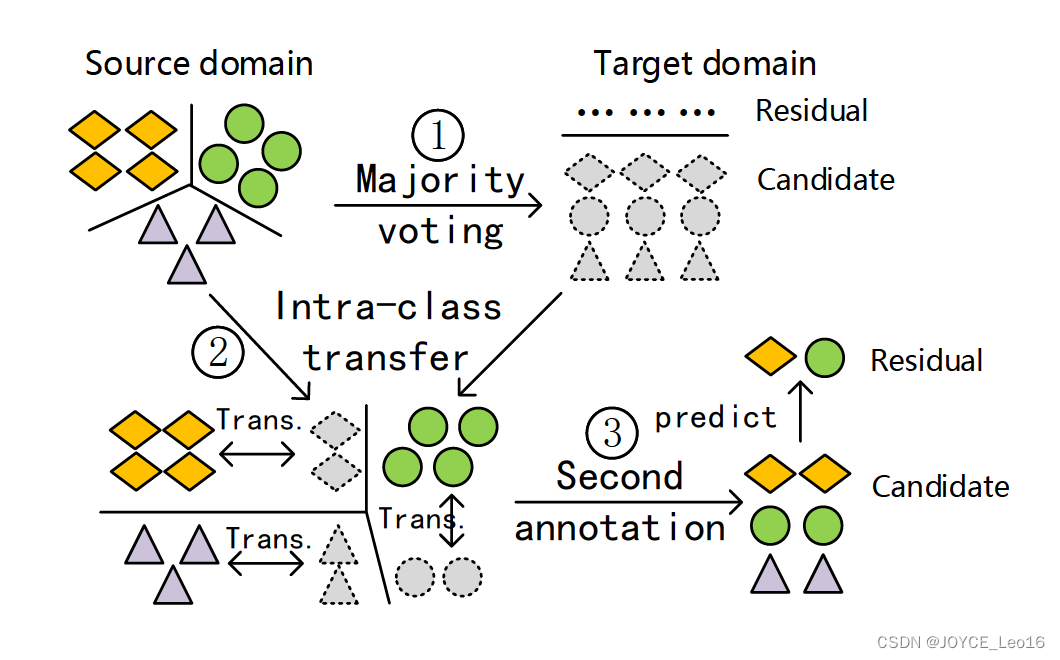
图21 STL 方法的示意图
11.3.4 联合分布自适应
联合分布自适应方法 (Joint Distribution Adaptation) 的目标是减小源域和目标域的联合概率分布的距离,从而完成迁移学习。从形式上来说,联合分布自适应方法是用P(xs) 和P(xt)之间的距离、以及P(ys|xs)和P(yt|xt)之间的距离来近似两个领域之间的差异。即:
联合分布自适应对应于图19中由图19(a)迁移到图19(b)的情形、以及图19(a)迁移到 图19(c)的情形。
11.3.5 概率分布自适应方法优劣性比较
综合上述三种概率分布自适应方法,我们可以得出如下的结论:
- 精度比较:BDA > JDA > TCA > 条件分布自适应。
- 将不同的概率分布自适应方法用于神经网络,是一个发展趋势。图23展示的结果表明将概率分布适配加入到深度网络中,往往会取得比非深度学习更好的结果。
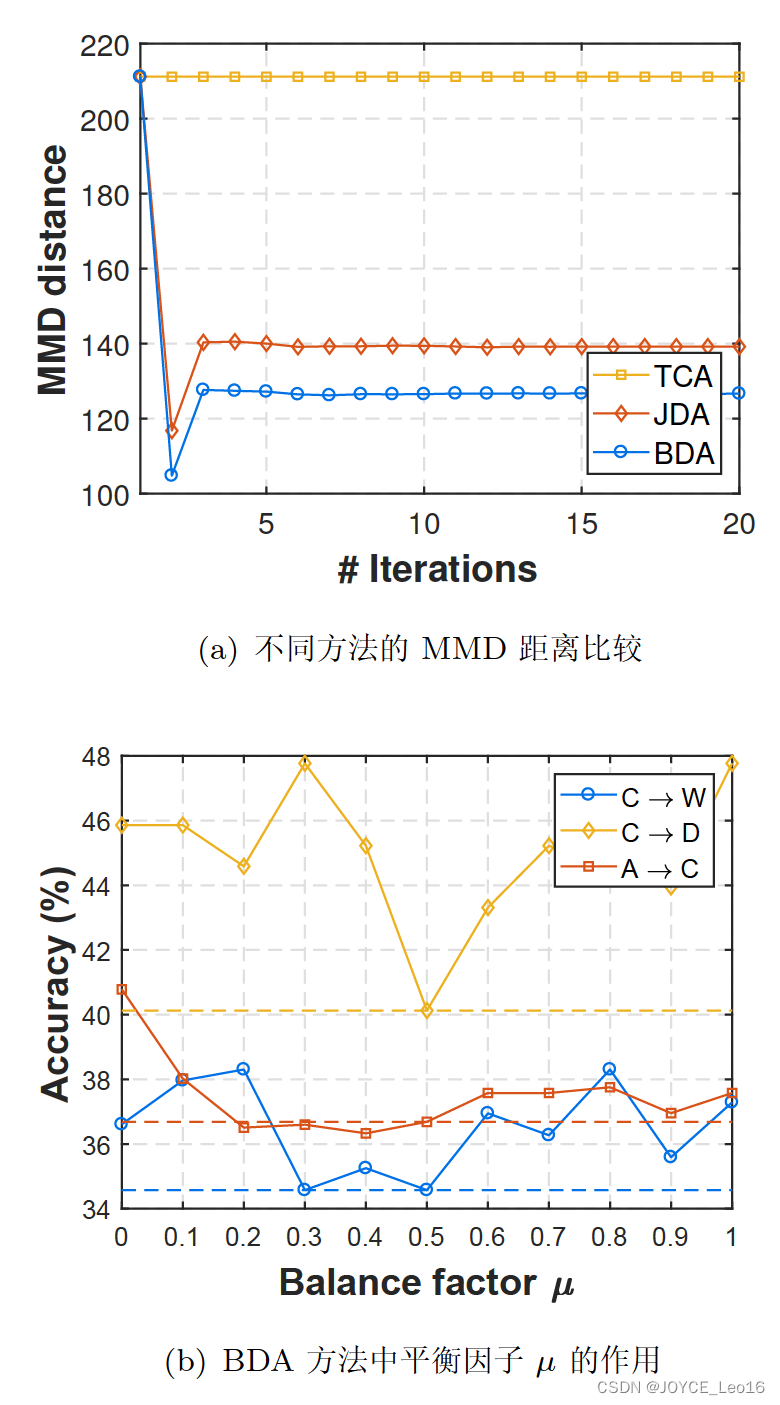
图22 BDA方法的效果
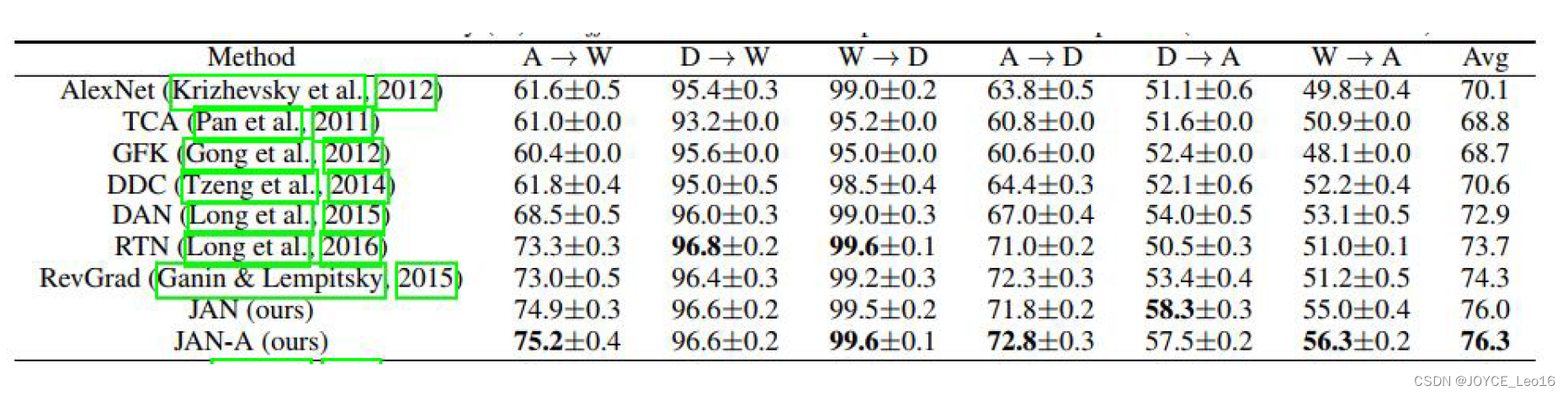
图23 不同分布自适应方法的精度比较
11.3.6 特征选择
特征选择的基本假设是:源域和目标域中均含有一部分公共的特征,在这部分公共的特征,源域和目标域的数据分布是一致的。因此,此类方法的目标就是,通过机器学习方法,选择出这部分共享的特征,即可依据这些特征构建模型。
图24形象地表示了特征选择法的主要思路。
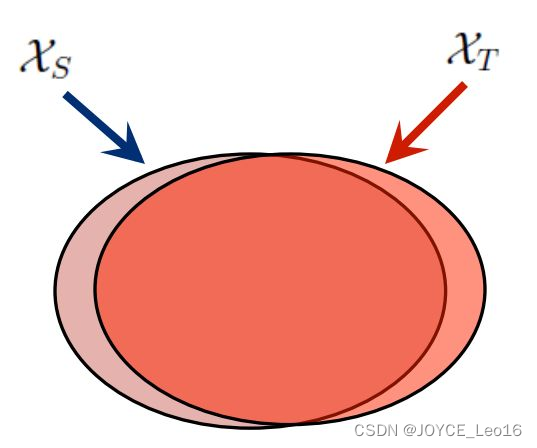
图24 特征选择法示意图
这这个领域比较经典的一个方法是发表在 2006 年的 ECML-PKDD 会议上,作者提出了一个叫做 SCL 的方法 (Structural Correspondence Learning) [Blitzer et al.,2006]。这个方法的目标就是我们说的,找到两个领域公共的那些特征。作者将这些公共的特征叫做Pivot feature。找出来这些Pivot feature,就完成了迁移学习的任务。
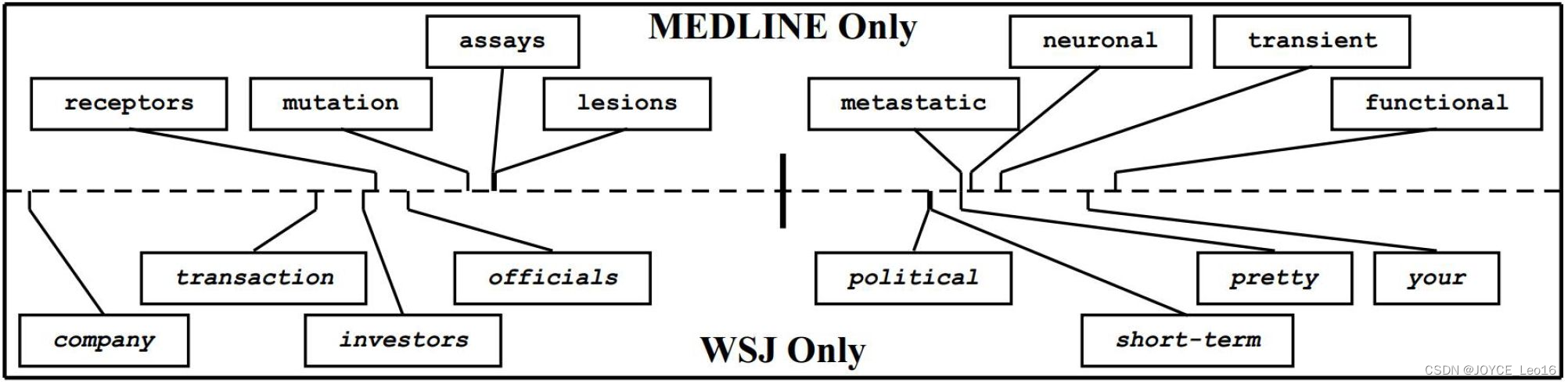
图25 特征选择法中的 Pivot feature 示意图
图 25形象地展示了 Pivot feature 的含义。 Pivot feature指的是在文本分类中,在不同领域中出现频次较高的那些词。总结起来:
- 特征选择法从源域和目标域中选择提取共享的特征,建立统一模型
- 通常与分布自适应方法进行结合
- 通常采用稀疏表示 ||A||2,1 实现特征选择
11.3.7 统计特征对齐方法
统计特征对齐方法主要将数据的统计特征进行变换对齐。对齐后的数据,可以利用传统机器学习方法构建分类器进行学习。SA方法(Subspace Alignment,子空间对齐)[Fernado et al.,2013]是其中的代表性成果。SA方法直接寻求一个线性变换M,将不同的数据实现变换对齐。SA方法的优化目标如下:
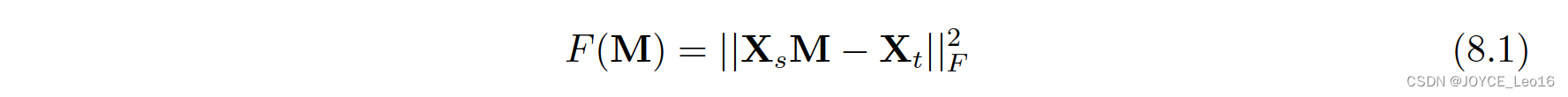
则变换 M 的值为:
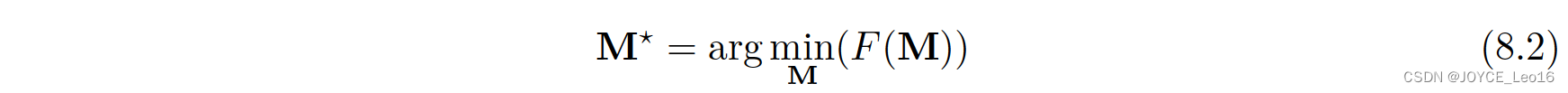
可以直接获得上述优化问题的闭式解:
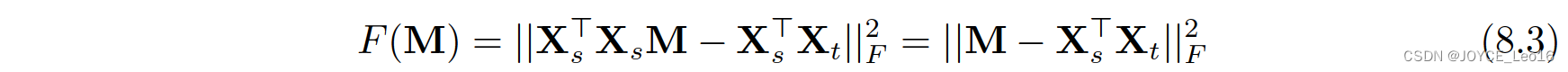
SA 方法实现简单,计算过程高效,是子空间学习的代表性方法。
这篇关于深度学习500问——Chapter10:迁移学习(3)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




