本文主要是介绍简述K-Means算法及实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
# -*- coding: utf-8 -*-from numpy import *
import time
import matplotlib.pyplot as plt# 计算欧几里德距离
def euclDistance(vector1, vector2):return sqrt(sum(power(vector2 - vector1, 2)))# 具有随机样本的初始质心
def initCentroids(dataSet, k):numSamples, dim = dataSet.shapecentroids = zeros((k, dim))for i in range(k):index = int(random.uniform(0, numSamples))centroids[i, :] = dataSet[index, :]return centroids# k-means 聚类
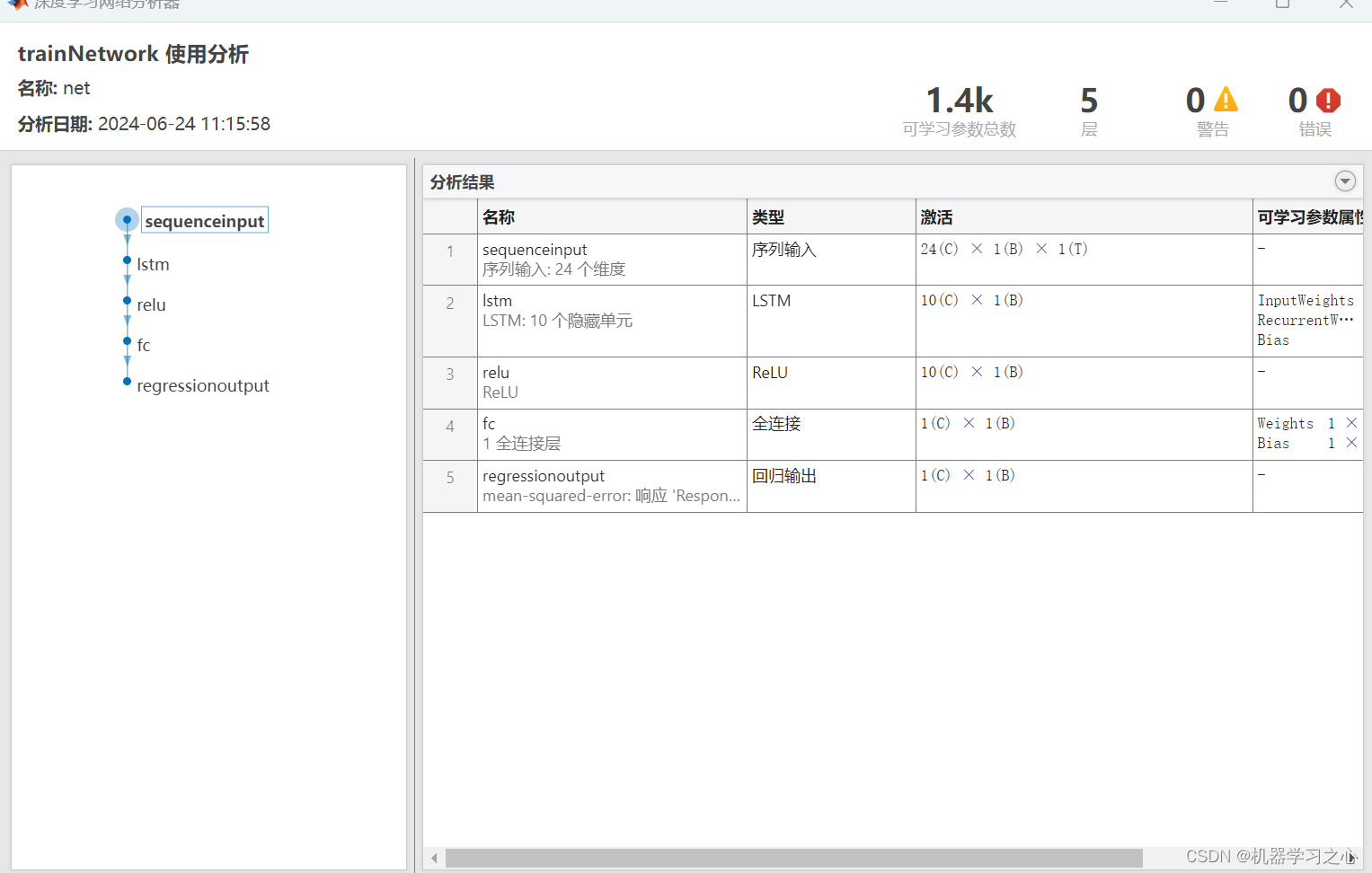
def kmeans(dataSet, k):numSamples = dataSet.shape[0]# 第一列存储该样本所属的集群,# 第二列存储此样本与其质心之间的误差clusterAssment = mat(zeros((numSamples, 2)))clusterChanged = True## 第1步:初始质心centroids = initCentroids(dataSet, k)while clusterChanged:clusterChanged = False## for each samplefor i in range(numSamples):minDist = 100000.0minIndex = 0## for each centroid## 步骤2:找到最接近的质心for j in range(k):distance = euclDistance(centroids[j, :], dataSet[i, :])if distance < minDist:minDist = distanceminIndex = j## 第3步:更新其群集if clusterAssment[i, 0] != minIndex:clusterChanged = TrueclusterAssment[i, :] = minIndex, minDist**2## 第4步:更新质心for j in range(k):pointsInCluster = dataSet[nonzero(clusterAssment[:, 0].A == j)[0]]centroids[j, :] = mean(pointsInCluster, axis = 0)print('Congratulations, cluster complete!')return centroids, clusterAssment# 显示您的群集仅适用于2-D数据
def showCluster(dataSet, k, centroids, clusterAssment):numSamples, dim = dataSet.shapeif dim != 2:print("Sorry! I can not draw because the dimension of your data is not 2!")return 1mark = ['or', 'ob', 'og', 'ok', '^r', '+r', 'sr', 'dr', '<r', 'pr']if k > len(mark):print ("Sorry! Your k is too large!")return 1# 绘制所有样本for i in range(numSamples):markIndex = int(clusterAssment[i, 0])plt.plot(dataSet[i, 0], dataSet[i, 1], mark[markIndex])mark = ['Dr', 'Db', 'Dg', 'Dk', '^b', '+b', 'sb', 'db', '<b', 'pb']# 画出质心for i in range(k):plt.plot(centroids[i, 0], centroids[i, 1], mark[i], markersize = 12)plt.show()
这篇关于简述K-Means算法及实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!