本文主要是介绍【语义分割】——读源码、论文理解OCRNet,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

论文:https://arxiv.org/pdf/1909.11065.pdf
源码:https://git.io/openseg and https://git.io/HRNet.OCR
.
1. 核心思想
微软亚洲研究院提出的 OCR 方法的主要思想是显式地把像素分类问题转化成物体区域分类问题,这与语义分割问题的原始定义是一致的,即每一个像素的类别就是该像素属于的物体的类别,换言之,与 PSPNet 和 DeepLabv3 的上下文信息最主要的不同就在于 OCR 方法显式地增强了物体信息。
链接:https://zhuanlan.zhihu.com/p/196685234
2. 网络结构
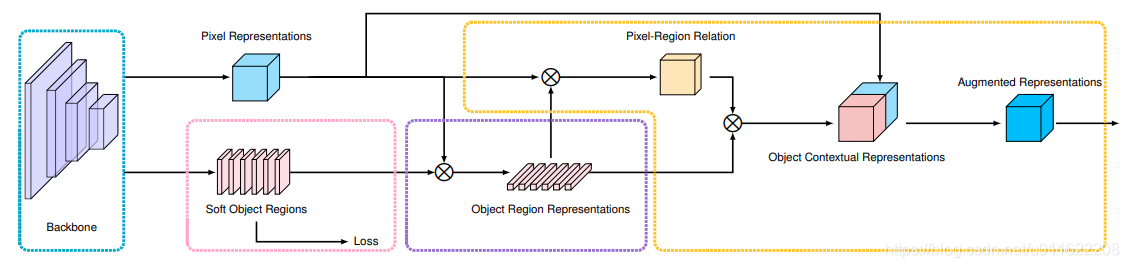
图2
这里我们假设经backone输出的特征为:b×c×h×w
OCR 方法的实现主要包括3个阶段:
(1) 根据网络中间层的特征表示估测一个粗略的语义分割结果作为 OCR 方法的一个输入 ,即软物体区域(Soft Object Regions)
解释: 这里就是采用1×1的卷积核做输出层,比如我们有17个类别,则网络输出为:b×17×h×w
code:
self.aux_head = nn.Sequential(nn.Conv2d(fc_dim, fc_dim,kernel_size=1, stride=1, padding=0),BatchNorm2d(fc_dim),nn.ReLU(inplace=True),nn.Conv2d(fc_dim, num_class,kernel_size=1, stride=1, padding=0, bias=True))
out_aux = self.aux_head(feats)
(2) 根据粗略的语义分割结果和网络最深层的特征表示计算出 K 组向量,即物体区域表示(Object Region Representations),其中每一个向量对应一个语义类别的特征表示,
解释:这里粗略的语义分割结果为:b×17×h×w,最深层的特征表示为backone最后输出的特征:b×c×h×w,二者采用matmul之后,得到一个b×17*c的矩阵,该矩阵表示有17个类别,每个类别可以用一个512的向量来表示描述
code
class SpatialGather_Module(nn.Module):"""Aggregate the context features according to the initial predicted probability distribution.Employ the soft-weighted method to aggregate the context."""def __init__(self, cls_num=0, scale=1):super(SpatialGather_Module, self).__init__()self.cls_num = cls_numself.scale = scaledef forward(self, feats, probs):batch_size, c, h, w = probs.size(0), probs.size(1), probs.size(2), probs.size(3)probs = probs.view(batch_size, c, -1) # batch × c × hwfeats = feats.view(batch_size, feats.size(1), -1)feats = feats.permute(0, 2, 1) # batch x hw x c probs = F.softmax(self.scale * probs, dim=2)# batch x k x hwocr_context = torch.matmul(probs, feats)\.permute(0, 2, 1).unsqueeze(3)# batch x k x creturn ocr_context(3) 计算网络最深层输出的像素特征表示(Pixel Representations)与计算得到的物体区域特征表示(Object Region Representation)之间的关系矩阵,然后根据每个像素和物体区域特征表示在关系矩阵中的数值把物体区域特征加权求和,得到最后的物体上下文特征表示 OCR (Object Contextual Representation) 。当把物体上下文特征表示 OCR 与网络最深层输入的特征表示拼接之后作为上下文信息增强的特征表示(Augmented Representation),可以基于增强后的特征表示预测每个像素的语义类别,具体算法框架可以参考图2。综上,OCR 可计算一组物体区域的特征表达,然后根据物体区域特征表示与像素特征表示之间的相似度将这些物体区域特征表示传播给每一个像素。
网络最深层的像素特征表示:b×c×h×w,物体区域特征表示:b×17×c,采用matmul操作,得到关系矩阵b×h×w×17,这里很容易将关系矩阵理解为分割结果,因为二者的维度是一样的。但是论文对17所在的维度做了softmax,然后和物体的上下文特征表示:b×17×c,用matmul操作,得到物体的上下文特征表示:b×c×h×w,所以,上文的17可以理解为每个像素点预测每个类别的概率(这样和分割的结果也就没啥区别了,但是后面用softmax,和matmul之后,又转换成了特征表示,这也就是最关键的部分吧)。然后,再和最深层的像素特征表示:b×c×h×w,拼接起来:b×2c×h×w,最后加一个输出层Conv2d(2c->classes:17)
Code:
转载自:https://www.zhihu.com/search?type=content&q=ocrnet
缺点
- 由于采用了类似attention的方式:物体区域特征表示,所以网络训练时收敛很慢,需要上百个epoch才能到很好的结果
这篇关于【语义分割】——读源码、论文理解OCRNet的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







