本文主要是介绍可转债全部历史因子数据,提供api支持,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天在写可转债系统,顺便下载了一下服务器的可转债数据,给大家研究使用
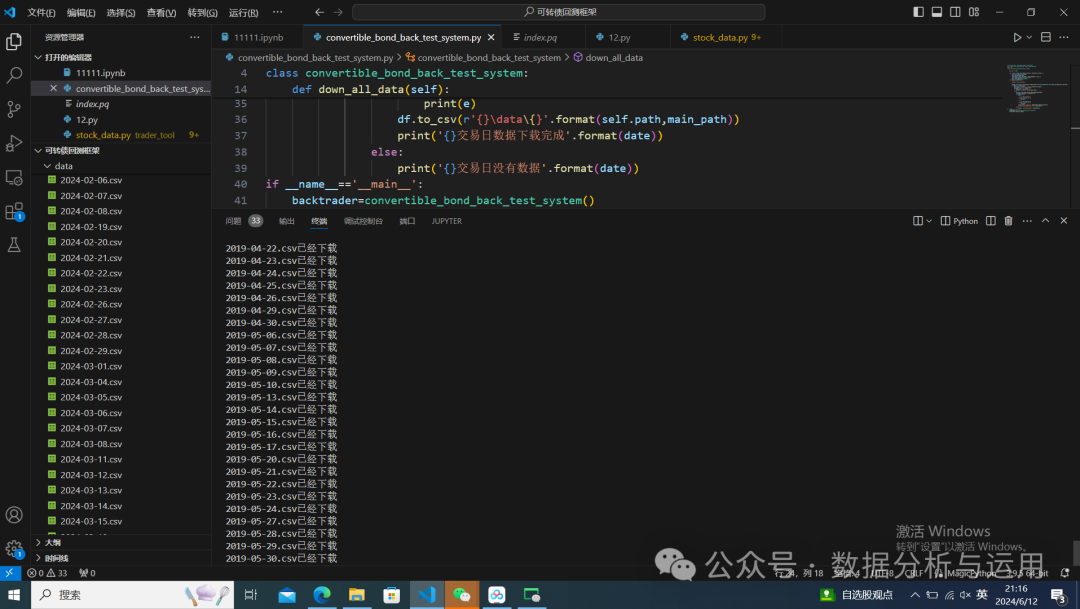
from trader_tool.stock_data import stock_datafrom trader_tool.lude_data_api import lude_data_apiimport osclass convertible_bond_back_test_system:'''可转债回测系统'''def __init__(self,start_date='20180101',end_date='20240612'):self.start_date=start_dateself.end_date=end_dateself.path=os.path.dirname(os.path.abspath(__file__))self.lude_data_api=lude_data_api()self.stock_data=stock_data()def down_all_data(self):'''下载服务器可转债全部数据'''trader_list=self.stock_data.get_trader_date_list(start_date=self.start_date,end_date=self.end_date)for date in trader_list:all_path=os.listdir(r'{}\data'.format(self.path))main_path='{}.csv'.format(date)if main_path in all_path:print('{}已经下载'.format(main_path))else:df=self.lude_data_api.get_bond_data(date=date)stats=df['数据状态'].tolist()[-1]if stats==True:try:del df['更新时间']except Exception as e:print(e)try:del df['数据时间']except Exception as e:print(e)df.to_csv(r'{}\data\{}'.format(self.path,main_path))print('{}交易日数据下载完成'.format(date))else:print('{}交易日没有数据'.format(date))if __name__=='__main__':backtrader=convertible_bond_back_test_system()backtrader.down_all_data()
原始的数据来自禄得,不用在商业用途,感谢老师的数据
网页 https://lude.cc/
我网页也支持数据下载 网页 http://120.78.132.143:8023/
点击可转债数据,禄得数据
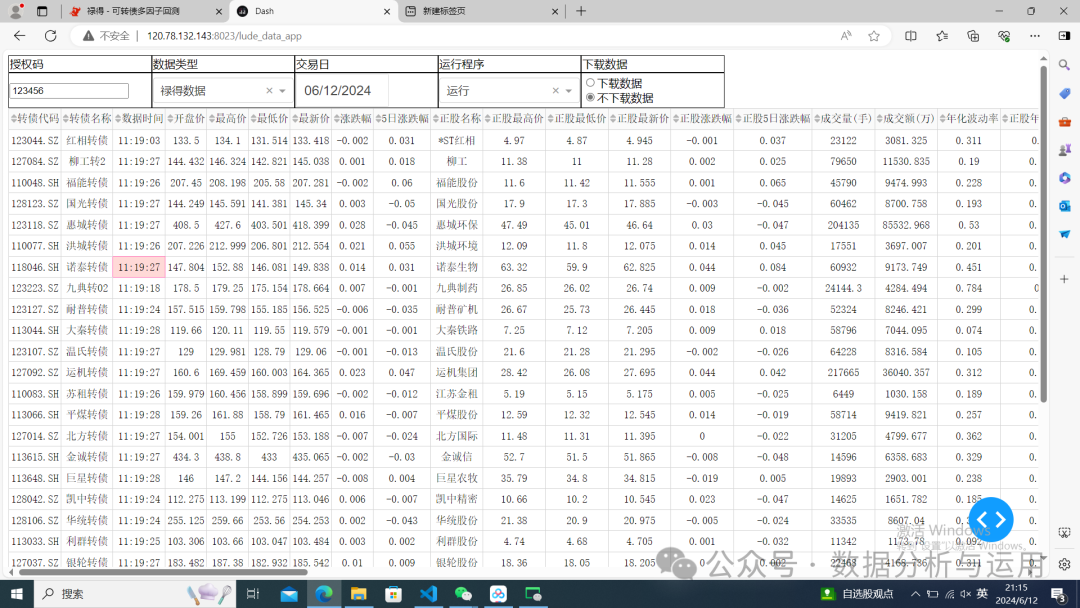
可以点击下载数据,选择日期
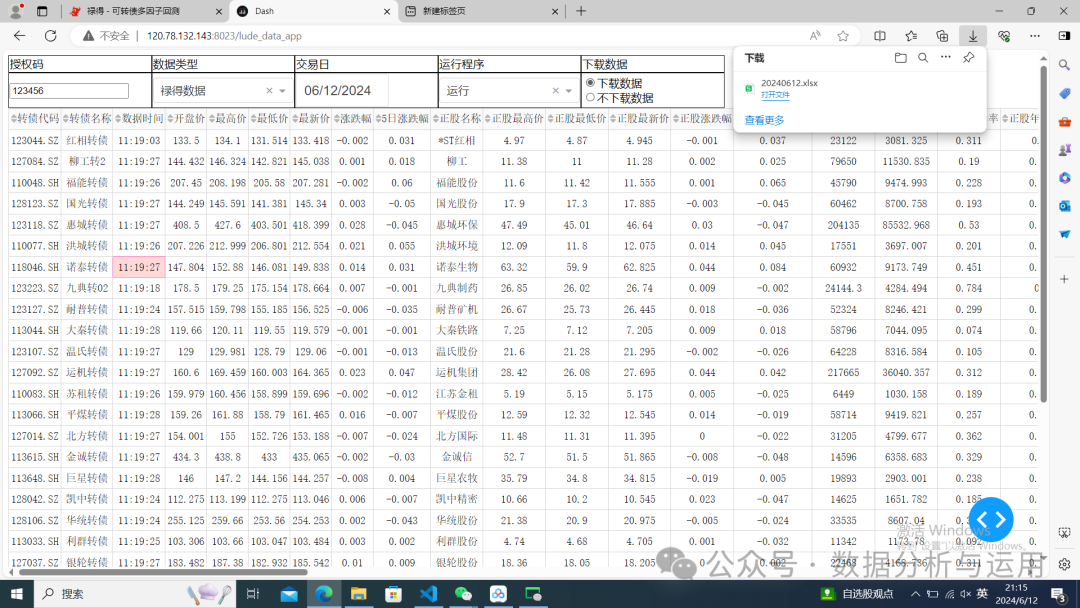
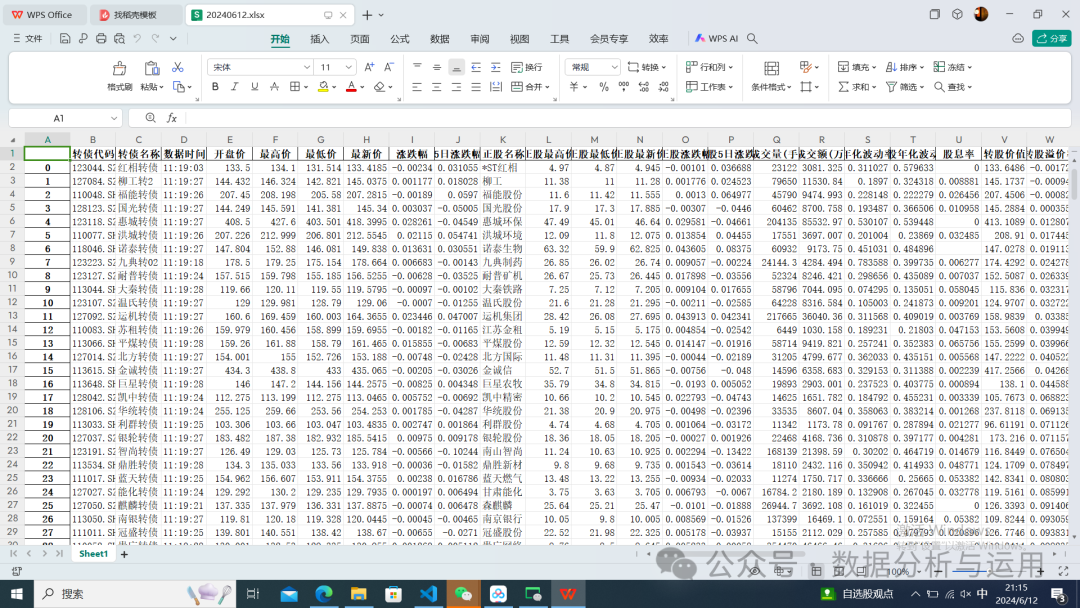
下载的数据
利用程序自动下载全部历史的数据
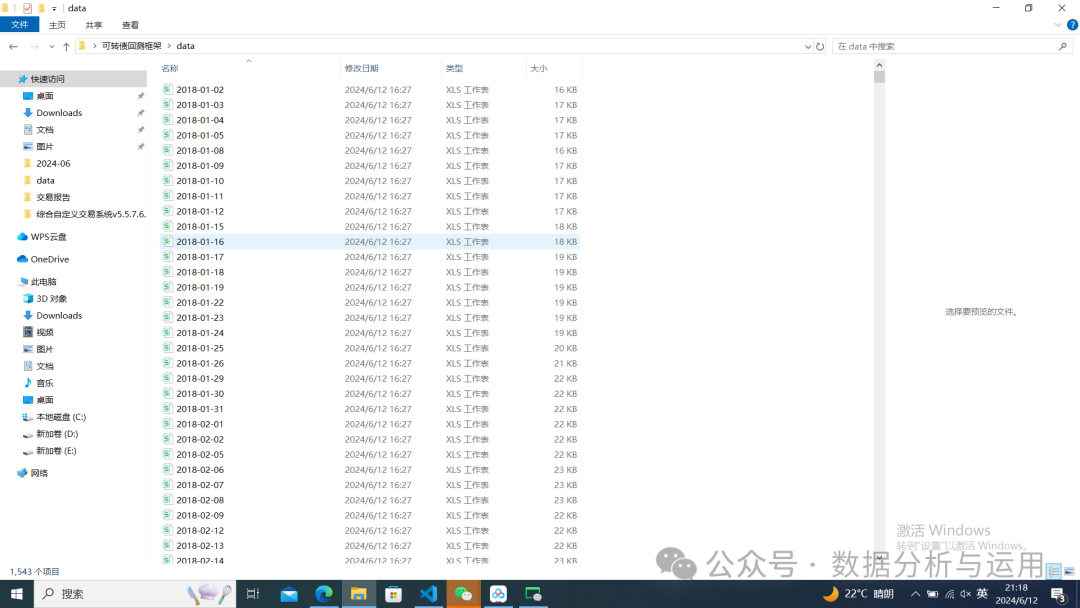
全部的历史数据
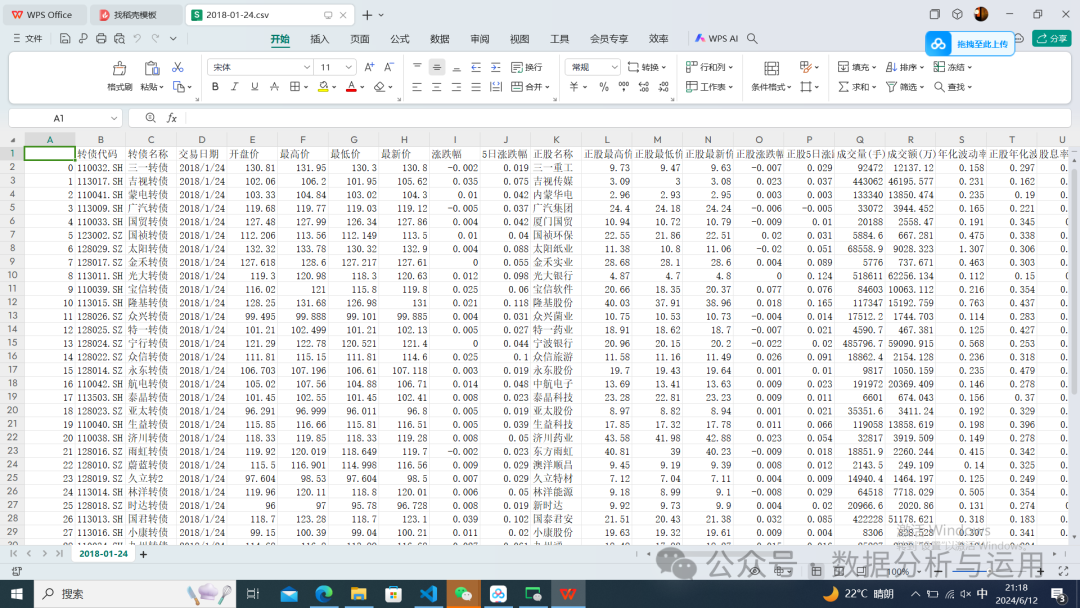
需要全部数据的直接回复20240612就可以

下载我服务器数据的api
import pandas as pdimport requestsimport jsonclass lude_data_api:def __init__(self,url='http://120.78.132.143',port='8023',password='123456'):'''手动下载存数据库禄得数据apiurl服务器port端口password授权码'''self.url=urlself.port=portself.password=passworddef get_bond_data(self,date='2024-04-26'):'''获取可转债数据'''url='{}:{}/_dash-update-component'.format(self.url,self.port)headers={'Content-Type':'application/json'}data={"output":"lude_data_maker_table.data@669dd4696a628d8290353c138057eb97","outputs":{"id":"lude_data_maker_table","property":"data@669dd4696a628d8290353c138057eb97"},"inputs":[{"id":"password","property":"value","value":self.password},{"id":"lude_data_data_type","property":"value","value":"禄得数据"},{"id":"lude_data_end_date","property":"date","value":date},{"id":"lude_data_run","property":"value","value":"运行"},{"id":"lude_data_down_data","property":"value","value":"不下载数据"}],"changedPropIds":["lude_data_run.value"]}res=requests.post(url=url,data=json.dumps(data),headers=headers)text=res.json()df=pd.DataFrame(text['response']['lude_data_maker_table']['data'])return dfdef get_bond_spot_data(self,date='2024-05-23'):'''获取可转债实时数据'''url='{}:{}/_dash-update-component'.format(self.url,self.port)headers={'Content-Type':'application/json'}data={"output":"lude_data_maker_table.data@669dd4696a628d8290353c138057eb97","outputs":{"id":"lude_data_maker_table","property":"data@669dd4696a628d8290353c138057eb97"},"inputs":[{"id":"password","property":"value","value":self.password},{"id":"lude_data_data_type","property":"value","value":"实时数据"},{"id":"lude_data_end_date","property":"date","value":date},{"id":"lude_data_run","property":"value","value":"运行"},{"id":"lude_data_down_data","property":"value","value":"不下载数据"}],"changedPropIds":["lude_data_run.value"]}res=requests.post(url=url,data=json.dumps(data),headers=headers)text=res.json()df=pd.DataFrame(text['response']['lude_data_maker_table']['data'])return dfif __name__=='__main__':models=lude_data_api()df=models.get_bond_data(date='2024-05-23')print(df)df=models.get_bond_spot_data(date='2024-05-23')
这篇关于可转债全部历史因子数据,提供api支持的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








