本文主要是介绍HBase原理 | HBase RegionServer宕机数据恢复,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
HBase采用类LSM的架构体系,数据写入并没有直接写入数据文件,而是会先写入缓存(Memstore),在满足一定条件下缓存数据再会异步刷新到硬盘。为了防止数据写入缓存之后不会因为RegionServer进程发生异常导致数据丢失,在写入缓存之前会首先将数据顺序写入HLog中。如果不幸一旦发生RegionServer宕机或者其他异常,这种设计可以从HLog中进行日志回放进行数据补救,保证数据不丢失。HBase故障恢复的最大看点就在于如何通过HLog回放补救丢失数据。
HLog简介
为了更好的理解HBase故障恢复原理,需要对HLog有简单的认识。HLog的整个生命历程可以使用下面一张图来表示:

1. HLog构建:详见另一篇博文《HBase-数据写入流程解析》中相关章节,此处再将HLog的结构示意图拿出来:

上图可以看出,一个HLog由RegionServer上所有Region的日志数据构成,日志数据的最小单元为<HLogKey,WALEdit>,其中HLogKey由sequenceid、writetime、clusterid、regionname以及tablename组成。其中sequenceid是日志写入时分配给数据的一个自增数字,先写入的日志数据sequenceid小,后写入的sequenceid大。
2. HLog滚动:HBase后台启动了一个线程会每隔一段时间(由参数’hbase.regionserver.logroll.period’决定,默认1小时)进行日志滚动,即新生成一个新的日志文件。可见,HLog日志文件并不是一个大文件,而是会产生很多小文件。有些同学就会问了,为什么需要产生多个日志文件,一个日志文件不好吗?这是因为随着数据的不断写入,HLog所占空间将会变的越来越大,然而很多日志数据其实已经没有任何作用了,这部分数据完全可以被删掉。而删除数据最好是一个文件一个文件整体删除,因此设计了日志滚动机制,方便文件整体删除。类似于Binlog的处理机制。
3. HLog失效:上文提到,很多日志数据在之后会因为失效进而可以被删除,并且删除操作是以文件为单元执行的。那怎么判断一个日志文件里面的数据失效了呢?首先从原理上讲一旦数据从Memstore中落盘,对应的日志就可以被删除,因此一个文件所有数据失效,只需要看该文件中最大sequenceid对应的数据是否已经落盘就可以,HBase会在每次执行flush的时候纪录对应的最大的sequenceid,如果前者小于后者,则可以认为该日志文件失效。一旦判断失效就会将该文件从WALs文件夹移动到OldWALs文件夹。
4. HLog删除:HMaster后台会启动一个线程每隔一段时间(由参数’hbase.master.cleaner.interval’,默认1分钟)会检查一次文件夹OldWALs下的所有失效日志文件,确认是否可以被删除,确认之后执行删除操作。又有同学问了,刚才不是已经确认可以被删除了吗?这里基于两点考虑,第一对于使用HLog进行主从复制的业务来说,第三步的确认并不完整,需要继续确认是否该HLog还在应用于主从复制;第二对于没有执行主从复制的业务来讲,HBase依然提供了一个过期的TTL(由参数’hbase.master.logcleaner.ttl’决定,默认10分钟),也就是说OldWALs里面的文件最多依然再保存10分钟。
HBase故障恢复三部曲
HBase的故障恢复我们都以RegionServer宕机恢复为例,引起RegionServer宕机的原因各种各样,有因为Full GC导致、网络异常导致、官方Bug导致(close wait端口未关闭)以及DataNode异常导致等等。
这些场景下一旦RegionServer发生宕机,HBase都会马上检测到这种宕机,并且在检测到宕机之后会将宕机RegionServer上的所有Region重新分配到集群中其他正常RegionServer上去,再根据HLog进行丢失数据恢复,恢复完成之后就可以对外提供服务,整个过程都是自动完成的,并不需要人工介入。基本原理如下图所示:

HBase检测宕机是通过Zookeeper实现的, 正常情况下RegionServer会周期性向Zookeeper发送心跳,一旦发生宕机,心跳就会停止,超过一定时间(SessionTimeout)Zookeeper就会认为RegionServer宕机离线,并将该消息通知给Master。上述步骤中比较特殊的是HLog切分,其他步骤相信都能够理解,为什么需要切分HLog?大家都知道当前(0.98)版本中一台RegionServer只有一个HLog文件,即所有Region的日志都是混合写入该HLog的,然而,回放日志是以Region为单元进行的,一个Region一个Region回放,因此在回放之前首先需要将HLog按照Region进行分组,每个Region的日志数据放在一起,方便后面按照Region进行回放。这个分组的过程就称为HLog切分。
根据实现方式的不同,HBase的故障恢复前后经历了三种不同模式,如下图所示,下面会针对每一种模式进行详细介绍:

LogSplitting
HBase的最初阶段是使用如下流程进行日志切分的,整个过程都由HMaster控制执行。如下图所示:
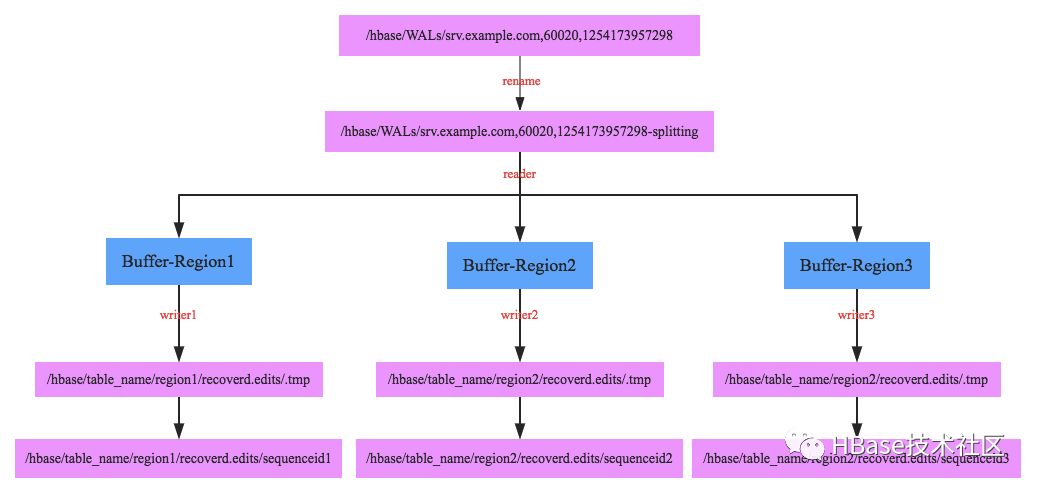
1. 将待切分日志文件夹重命名,为什么需要将文件夹重命名呢?这是因为在某些场景下RegionServer并没有真正宕机,但是HMaster会认为其已经宕机并进行故障恢复,比如最常见的RegionServer发生长时间Full GC,这种场景下用户并不知道RegionServer宕机,所有的写入更新操作还会继续发送到该RegionServer,而且由于该RegionServer自身还继续工作所以会接收用户的请求,此时如果不重命名日志文件夹,就会发生HMaster已经在使用HLog进行故障恢复了,但是RegionServer还在不断写入HLog
2. 启动一个读线程依次顺序读出每个HLog中所有<HLogKey,WALEdit>数据对,根据HLogKey所属的Region不同写入不同的内存buffer中,如上图Buffer-Region1内存存放Region1对应的所有日志数据,这样整个HLog所有数据会被完整group到不同的buffer中
3. 每个buffer会对应启动一个写线程,负责将buffer中的数据写入hdfs中(对应的路径为/hbase/table_name/region/recoverd.edits/.tmp),再等Region重新分配到其他RegionServer之后按顺序回放对应Region的日志数据。
这种日志切分可以完成最基本的任务,但是效率极差,在某些场景下(集群整体宕机)进行恢复可能需要N个小时!也因为恢复效率太差,所以开发了Distributed Log Splitting架构。
Distributed Log Splitting
Distributed Log Splitting是Log Splitting的分布式实现,它借助Master和所有RegionServer的计算能力进行日志切分,其中Master作为协调者,RegionServer作为实际的工作者。基本工作原理如下图所示:
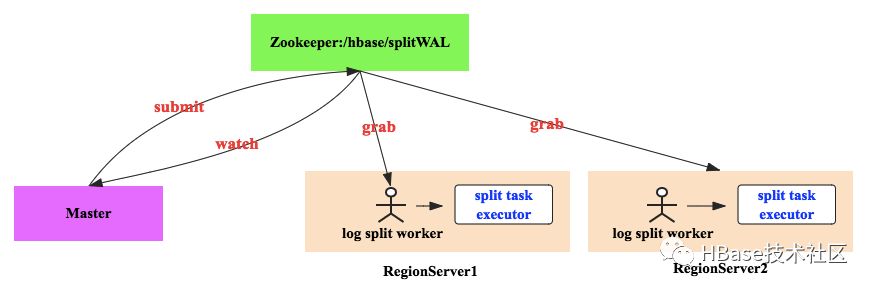
1. Master会将待切分日志路径发布到Zookeeper节点上(/hbase/splitWAL),每个日志作为一个任务,每个任务都会有对应状态,起始状态为TASK_UNASSIGNED
2. 所有RegionServer启动之后都注册在这个节点上等待新任务,一旦Master发布任务之后,RegionServer就会抢占该任务
3. 抢占任务实际上首先去查看任务状态,如果是TASK_UNASSIGNED状态,说明当前没有人占有,此时就去修改该节点状态为TASK_OWNED。如果修改失败,说明其他RegionServer也在抢占,修改成功表明任务抢占成功。
4. RegionServer抢占任务成功之后会分发给相应线程处理,如果处理成功,会将该任务对应zk节点状态修改为TASK_DONE,一旦失败会修改为TASK_ERR
5. Master会一直监听在该ZK节点上,一旦发生状态修改就会得到通知。任务状态变更为TASK_ERR的话,Master会重新发布该任务,而变更为TASK_DONE的话,Master会将对应的节点删除
下图是RegionServer抢占任务以及抢占任务之后的工作流程:
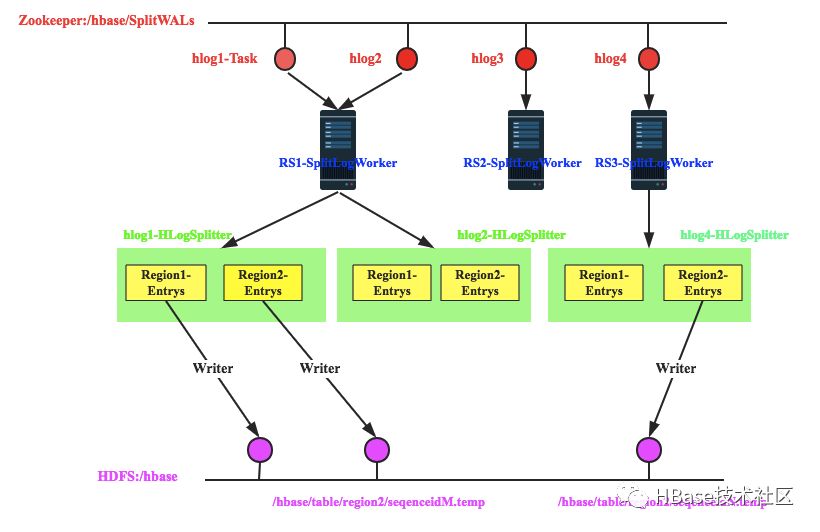
1. 假设Master当前发布了4个任务,即当前需要回放4个日志文件,分别为hlog1、hlog2、hlog3和hlog4
2. RegionServer1抢占到了hlog1和hlog2日志,RegionServer2抢占到了hlog3日志,RegionServer3抢占到了hlog4日志
3. 以RegionServer1为例,其抢占到hlog1和hlog2日志之后会分别分发给两个HLogSplitter线程进行处理,HLogSplitter负责对日志文件执行具体的切分,切分思路还是首先读出日志中每一个<HLogKey, WALEdit>数据对,根据HLogKey所属Region写入不同的Region Buffer
4. 每个Region Buffer都会有一个对应的写线程,将buffer中的日志数据写入hdfs中,写入路径为/hbase/table/region2/seqenceid.temp,其中seqenceid是一个日志中某个region对应的最大sequenceid
5. 针对某一region回放日志只需要将该region对应的所有文件按照sequenceid由小到大依次进行回放即可
这种Distributed Log Splitting方式可以很大程度上加快整个故障恢复的进程,正常故障恢复时间可以降低到分钟级别。然而,这种方式会产生很多日志小文件,产生的文件数将会是M * N,其中M是待切分的总hlog数量,N是一个宕机RegionServer上的Region个数。假如一个RegionServer上有200个Region,并且有90个hlog日志,一旦该RegionServer宕机,那这种方式的恢复过程将会创建 90 * 200 = 18000个小文件。这还只是一个RegionServer宕机的情况,如果是整个集群宕机小文件将会更多!!!
Distributed Log Replay
该方案在基本流程上做了一些改动,如下图所示:

相比Distributed Log Splitting方案,流程上的改动主要有两点:先重新分配Region,再切分回放HLog;Region重新分配打开之后状态设置为recovering,核心在于recovering状态的Region可以对外提供写服务,不能提供读服务,而且不能执行split、merge等操作。
DLR的HLog切分回放基本框架类似于Distributed Log Splitting,但它在分解完HLog为Region-Buffer之后并没有去写入小文件,而是直接去执行回放。这样设计可以大大减少小文件的读写IO消耗,解决DLS的切身痛点。
可见,在写可用率以及恢复性能上,DLR要远远优于DLS方案,官方也给出了一个简单的测试报告:
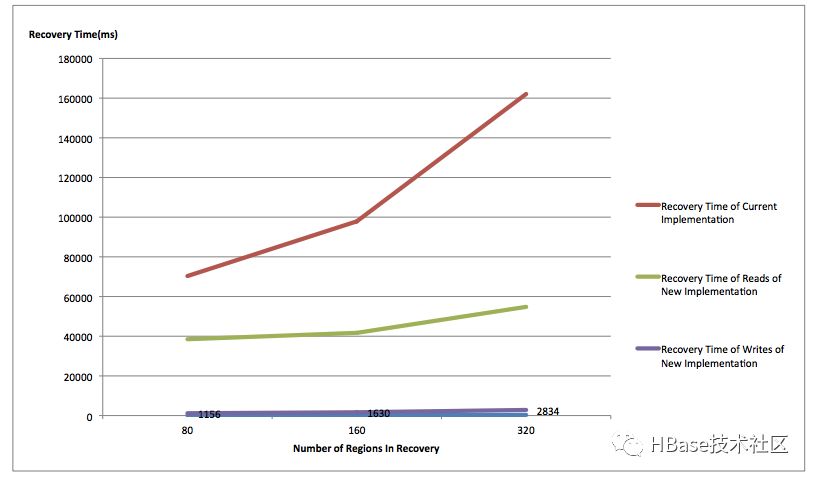
可见,DLR在写可用恢复是最快的,读可用恢复稍微弱一点,但都比DLS好很多
了解了DLR的解决方案后,再回头看DLS的实现方案,就不禁要问上一句:为什么DLS需要将Buffer中的数据写入小文件中?个人认为原因最有可能是写入小文件之后,同一个Region的不同日志数据可以按照文件名中sequenceid由小到大进行顺序回放,完全可以模拟当时数据写入的流程,不会有丝毫偏差。而如果不写小文件,很难在分布式环境下对sequenceid进行排序,这里就有一个问题,不按顺序对HLog进行回放会不会出现问题?这个问题可以分为下面两个层面进行讨论:
1. 不同时间更新的相同rowkey,不按顺序回放会不会有问题?比如WAL1中有<rowkey, t1>,WAL2中有<rowkey,t2>,正常情况下应该先回放<rowkey,t1>对应的日志数据,再回放<rowkey,t2>对应的日志数据,如果顺序颠倒会不会有问题?
第一眼看到这样的问题觉得一定不行啊,正常情况下<rowkey,t2>对应的日志数据才是最后的真正数据,一旦颠倒之后不就变成<rowkey,t1>对应的日志数据了。
这里需要关注更新时间的概念,rowkey回放时,如果写入时间戳定义为回放时间的话,肯定会有异常的。但是如果回放日志数据的时候rowkey写入时间戳被定义为当时rowkey数据写入日志的时间的话,就正常了。按照上面例子,顺序即使颠倒,先写<rowkey,t2>再写<rowkey,t1>,但是写入数据的时间戳(版本)依然保持不变时t2和t1的话,最大版本数据还是<rowkey,t2>,用户读取最新数据依然是<rowkey,t2>,和回放顺序并没有关系。
2. 相同时间戳更新的相同rowkey,不按顺序回放会不会有问题?比如WAL1中有<rowkey, t0>,WAL2中有<rowkey,t0>,正常情况下也应该先回放前者,再回放后者,如果顺序颠倒会不会有问题?
为什么同一时间会有多条相同rowkey的写入更新,而且还在不同的日志文件中?大家肯定会有这样的疑问。问题中‘同一时间’的单位是ms,在很多写入吞吐量很大的场景下同一毫秒写入大量数据并不是不可能,那先后写入两条相同rowkey的数据也必然可能,至于为什么在不同文件,假如刚好第一次更新完rowkey的时候日志截断了,第二次更新就会落入下一个日志。
那这种情况下前后两次更新时间戳还一致,颠倒顺序就办法分出哪个版本大了呀!莫慌,不是还有sequenceid~,只要在回放的时候将日志数据原生sequenceid也一同写入,不就可以在时间戳相同的情况下根据sequenceid进行判断了。具体实现只需要写入一个replay标示(用来表示该数据时回放写入)和相应的sequenceid,用户在读取的时候如果遇到两个都带有replay标示而且rowkey、cf、column、时间戳都相同的情况,还需要比较sequenceid就可以分辨出来哪个数据版本更大。
具体可以参考这个官方jira:https://issues.apache.org/jira/browse/HBASE-8701
在0.95版本DLR功能已经基本实现,一度在0.99版本已经设为默认,但是因为还是有一些功能性缺陷(主要是在rolling upgrades的场景下可能会导致数据丢失),又在1.1版本取消了默认设置。用户可以通过设置参数hbase.master.distributed.log.replay = true 来开启DLR功能,当然前提是将HFile格式设置为V3(v3格式HFile引入了tag功能,replay标示就是用tag进行实现的)
总结
本文主要介绍了HLog相关知识,同时基于此对HBase中RegionServer宕机之后整个恢复流程以及原理进行了深入分析,重点分析了DLS方案以及DLR方案,希望和大家一起学习HBase故障恢复模块知识。文中如有错误,可以一起讨论学习。
这篇关于HBase原理 | HBase RegionServer宕机数据恢复的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







