本文主要是介绍【对抗样本】【FGSM】Explaining and Harnessing Adversarial Examples 代码复现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介
参考Pytorch官方的代码Adversarial Example Generation
参数设置(main.py)
# 模型选择:GPU
device = 'mps' if torch.backends.mps.is_available() else 'cpu'
# 数据集位置
dataset_path = '../../../Datasets'
batch_size = 1
shuffle = True
download = False
# 学习率
learning_rate = 0.001
# 预训练模型位置
model_path = "../../../Pretrained_models/Model/MNISTModel_9.pth"transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,)),transforms.Grayscale(),
])
# 扰动参数
epsilons = [0, .05, .1, .15, .2, .25, .3]
device:用于选择训练设备,本人是mac m1的电脑,所以使用mps训练dataset_path:指定数据集路径batch_size:用于DataLoader,判断每次抓取数据的数量shuffle:用于DataLoader,判断是否洗牌download:判断数据集是否下载learning_rate:设置学习率model_path:指定预训练模型路径transform:指定数据集转化规则,用于对数据集中输入的图像进行预处理ToTensor:转化为Tensor数据类型,同时将图片进行归一化Normalize:正则化Grayscale:转化为灰度图像
epsilons:设置扰动参数,用于测试不同扰动的对抗样本的正确率
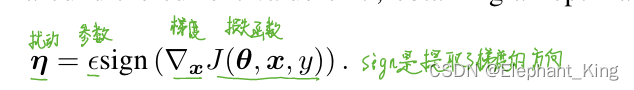
对抗样本代码主流程(main.py)
因为习惯了C++的语法,还是喜欢定义main函数,比较直观哈哈哈哈哈
主要分为三步
- 对数据的生成与预处理
if __name__ == '__main__':# 1.预处理train_dataset = datasets.MNIST(dataset_path, train=True, download=download, transform=transform)val_dataset = datasets.MNIST(dataset_path, train=False, download=download, transform=transform)train_DataLoader = DataLoader(train_dataset, batch_size=batch_size, shuffle=shuffle)val_DataLoader = DataLoader(val_dataset, batch_size=batch_size, shuffle=shuffle)model = torch.load(model_path).to(device)
- 数据集生成
- DataLoader 生成
- 预训练模型加载
- 开始测试
# 2.开始测试# 记录不同扰动下的准确度accuracies = []# 记录样本examples = []# 对每个epsilon运行测试for eps in epsilons:# 进行对抗样本攻击acc, ex = test(model, device, val_DataLoader, eps)# 将此扰动的准确度记录accuracies.append(acc)# 二维数组,行代表不同的epsilon,列代表当前epsilon生成的对抗样本examples.append(ex)共测试扰动参数为0, 0.05, 0.1, 0.15, 0.2, 0.25, 0.3
- 记录每种扰动参数的准确率与生成的对抗样本
- 对每种扰动参数生成对抗样本并进行攻击(调用test.py)
- 绘图并进行可视化
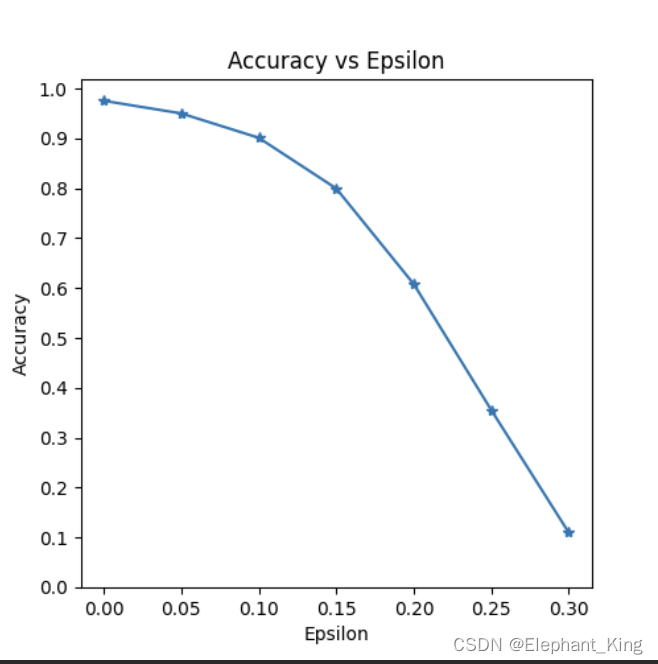
# 创建一个新的图形对象,图形大小设置为 5x5 英寸plt.figure(figsize=(5, 5))# 用epsilons作为x轴数据,accuracies作为y轴数据# *-代表数据点用*标记,点之间用直线链接plt.plot(epsilons, accuracies, "*-")# 设置y轴刻度,# np.arange(0, 1.1, step=0.1)生成0~1的数组,步长为0.1plt.yticks(np.arange(0, 1.1, step=0.1))# 设置x轴刻度# 生成0~0.3的数组,步长为0.05plt.xticks(np.arange(0, .35, step=0.05))# 将图标标题设为Accuracy vs Epsilonplt.title("Accuracy vs Epsilon")# x轴标签为Epsilonplt.xlabel("Epsilon")# y轴标签为Accuracyplt.ylabel("Accuracy")# 显示图表plt.show()
cnt = 0plt.figure(figsize=(8, 10))# 行代表不同的epsilonfor i in range(len(epsilons)):# 列代表同一epsilon生成的图像for j in range(len(examples[i])):cnt += 1plt.subplot(len(epsilons), len(examples[0]), cnt)plt.xticks([], [])plt.yticks([], [])if j == 0:plt.ylabel("Eps: {}".format(epsilons[i]), fontsize=14)orig, adv, ex = examples[i][j]plt.title("{} -> {}".format(orig, adv))plt.imshow(ex, cmap="gray")plt.tight_layout()plt.show()

对抗样本攻击流程(test.py)
def test(model, device, test_loader, epsilon):
传入四个参数
model:传入训练好的神经网络device:训练设备,mpstest_loader:测试集的DataLoaderepsilon:扰动参数
import torch.nn.functional as F
from torchvision import transforms
import timefrom src.attack import fgsm_attack, denormdef test(model, device, test_loader, epsilon):model.eval()accuracy = 0adv_examples = []start_time = time.time()for img, label in test_loader:img, label = img.to(device), label.to(device)# 作用是允许 PyTorch 跟踪输入图像的梯度,以便进行反向传播时计算对抗扰动。img.requires_grad = Trueoutput = model(img)init_pred = output.argmax(dim=1, keepdim=True)# 如果已经预测错误了,就不用进行后续操作了,进行下一轮循环if init_pred.item() != label.item():continueloss = F.nll_loss(output, label)model.zero_grad()loss.backward()# 收集图片梯度data_grad = img.grad.data# 恢复图片到原始尺度data_denorm = denorm(img, device)perturbed_data = fgsm_attack(data_denorm, epsilon, data_grad)"""重新进行归一化处理如果不对生成的对抗样本进行归一化处理,程序可能会受到以下几个方面的影响:1. 输入数据分布不一致模型在训练时,输入数据经过了归一化处理,使得数据的分布具有均值和标准差的特定统计特性。如果对抗样本在进行攻击后没有进行归一化处理,其数据分布将与模型训练时的数据分布不一致。这种不一致可能导致模型对对抗样本的预测不准确。2. 模型性能下降由于输入数据分布的变化,模型的权重和偏置项可能无法适应未归一化的数据,从而导致模型性能下降。模型可能无法正确分类这些未归一化的对抗样本,从而影响模型的预测准确率。3. 扰动效果不可控在 FGSM 攻击中,添加的扰动是在未归一化的数据上进行的。如果不进行归一化处理,这些扰动在模型输入阶段可能会被放大或缩小,影响攻击的效果。这样,攻击的成功率和对抗样本的生成效果可能会变得不可控。"""perturbed_data_normalized = transforms.Normalize((0.1307,), (0.3081,))(perturbed_data)output = model(perturbed_data_normalized)final_pred = output.argmax(dim=1, keepdim=True)if final_pred.item() == label.item():accuracy += 1if epsilon == 0 and len(adv_examples) < 5:"""perturbed_data 是经过FGSM攻击后的对抗样本,仍是一个tensor张量squeeze 会移除所有大小为1的维度比如MNIST中batch_size = 1 channel=1 像素为28x28,则perturbed_data.shape = (1,1,28,28)通过squeeze会变为(28,28)detach 代表不在跟踪其梯度,类似于你有一个银行账户(相当于张量 x),你希望在这个账户基础上做一些假设性的计算(比如计划未来的支出),但不希望这些假设性的计算影响到实际的账户余额。银行账户余额(张量 x):你现在的账户余额是 $1000。你可以对这个余额进行正常的交易(如存款、取款),这些交易会影响余额。假设性的计算(使用 detach()):你想做一些假设性的计算,比如计划未来的支出,看看在不同情况下余额会变成多少。你将当前余额复制一份(使用 detach()),对这份复制的余额进行操作。不管你对复制的余额进行什么操作,都不会影响到实际的账户余额。cpu 将张量从GPU移到CPU,因为NumPy不支持GPU张量numpy 将tensor转化为Numpy数组"""adv_ex = perturbed_data.squeeze().detach().cpu().numpy()adv_examples.append((init_pred.item(), final_pred.item(), adv_ex))else:if len(adv_examples) < 5:adv_ex = perturbed_data.squeeze().detach().cpu().numpy()adv_examples.append((init_pred.item(), final_pred.item(), adv_ex))# Calculate final accuracy for this epsilonfinal_acc = accuracy / float(len(test_loader))end_time = time.time()print(f"Epsilon: {epsilon}\tTest Accuracy = {accuracy} / {len(test_loader)} = {final_acc},Time = {end_time - start_time}")# Return the accuracy and an adversarial examplereturn final_acc, adv_examp
需要注意的是,在生成对抗样本的时候,需要先调用自定义的denorm方法进行反归一化,具体的原因是
# 反归一化data_denorm = denorm(img, device)# 生成对抗样本perturbed_data = fgsm_attack(data_denorm, epsilon, data_grad)# 将对抗样本标准化perturbed_data_normalized = transforms.Normalize((0.1307,), (0.3081,))(perturbed_data)
在我们构建生成数据集时的transform时,
ToTensor不仅有转化数据类型的作用,还有归一化的作用,将原来单通道像素值0~255归一化到0~1Normalize进行了标准化操作,在标准化后可能出现像素值又>1的情况,又因为在fgsm_attack方法中
perturbed_image = torch.clamp(perturbed_image, 0, 1)
将图像重新归一化,所以我们需要使用denorm,在生成对抗样本之前进行反归一化,目的是将预处理标准化可能>1的情况进行消除,重新回到0~1
如果不进行反归一化,会导致生成的对抗样本与原图的偏差较大
在生成对抗样本后,重新进行标准化
adv_example主要用于存储五个生成的对抗样本,用于后续的图像生成
对抗样本生成(attack.py)
def fgsm_attack(image, epsilon, data_grad):"""Perform FGSM with:param image: 输入图片:param epsilon: 𝜀超参数:param data_grad: 梯度:return:"""# 获取梯度方向sign_data_grad = data_grad.sign()# 对原始图像添加扰动perturbed_image = image + epsilon * sign_data_grad# 将生成的对抗样本的扰动控制在0~1之间perturbed_image = torch.clamp(perturbed_image, 0, 1)return perturbed_image
传入的参数为
image:Tensor类型的图片epsilon:扰动的参数data_grad:图片的梯度
方法的作用为生成对抗样本
- 根据传入的梯度参数获取梯度的方向
- 将原始图片家养梯度方向的扰动,使得生成的图像在视觉上与原始图像几乎相同,但模型的预测可能会发生变化
- 将生成的对抗样本的扰动控制在0~1之间
反归一化(attack.py)
def denorm(batch, device, mean=[0.1307], std=[0.3081]):
batch:传入的图像device:训练设备mean:均值std:标准差
def denorm(batch, device, mean=[0.1307], std=[0.3081]):"""Convert a batch of tensors to their original scale.Args:batch (torch.Tensor): Batch of normalized tensors.device:mean (torch.Tensor or list): Mean used for normalization.std (torch.Tensor or list): Standard deviation used for normalization.Returns:torch.Tensor: batch of tensors without normalization applied to them."""if isinstance(mean, list):mean = torch.tensor(mean, requires_grad=True).to(device)if isinstance(std, list):std = torch.tensor(std, requires_grad=True).to(device)return batch * std.view(1, -1, 1, 1) + mean.view(1, -1, 1, 1)将图像重新归一化
完整代码
见Github
这篇关于【对抗样本】【FGSM】Explaining and Harnessing Adversarial Examples 代码复现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




