本文主要是介绍Logistic函数与Logistic回归,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Logistic函数与Logistic回归
Logistic函数的表示形式如下:
它的函数图像如下,由于函数图像很像一个“S”型,所以该函数又叫 sigmoid 函数。

满足的性质:
1.对称性,关于(0,0.5)中心对称

2.逻辑斯谛方程即微分方程

最早logistic函数是皮埃尔·弗朗索瓦·韦吕勒在1844或1845年在研究它与人口增长的关系时命名的。广义Logistic曲线可以模仿一些情况人口增长( P )的 S 形曲线。起初阶段大致是 指数增长;然后随着开始变得饱和,增加变慢;最后,达到成熟时增加停止。
当一个物种迁入到一个新生态系统中后,其数量会发生变化。假设该物种的起始数量小于环境的最大容纳量,则数量会增长。该物种在此生态系统中有天敌、食物、空间等资源也不足(非理想环境),则增长函数满足逻辑斯谛方程,图像呈S形,此方程是描述在资源有限的条件下种群增长规律的一个最佳数学模型。在以下内容中将具体介绍逻辑斯谛方程的原理、生态学意义及其应用。
二.Logistic Regression(逻辑回归)
Logistic regression (逻辑回归)是当前业界比较常用的机器学习方法,用于估计某种事物的可能性。之前在经典之作《数学之美》中也看到了它用于广告预测,也就是根据某广告被用户点击的可能性,把最可能被用户点击的广告摆在用户能看到的地方,然后叫他“你点我啊!”用户点了,你就有钱收了。这就是为什么我们的电脑现在广告泛滥的原因了。
还有类似的某用户购买某商品的可能性,某病人患有某种疾病的可能性啊等等。这个世界是随机的(当然了,人为的确定性系统除外,但也有可能有噪声或产生错误的结果,只是这个错误发生的可能性太小了,小到千万年不遇,小到忽略不计而已),所以万物的发生都可以用可能性或者几率(odds)来表达。“几率”指的是某事物发生的可能性与不发生的可能性的比值。
Logistic regression可以用来回归,也可以用来分类,主要是二分类。它不像SVM直接给出一个分类的结果,Logistic Regression给出的是这个样本属于正类或者负类的可能性是多少,当然在多分类的系统中给出的是属于不同类别的可能性,进而通过可能性来分类。
考虑具有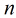
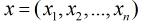
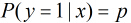
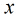
概率。那么Logistic回归模型可以表示为
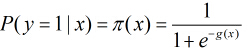
这里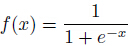
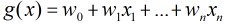
那么在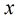

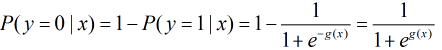
所以事件发生与不发生的概率之比为
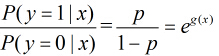
这个比值称为事件的发生比(the odds of experiencing an event),简记为odds。考查logistic回归模型的特点,一个事件的几率(odds)是指这件事发生的概率与不发生概率的比值,如果事件发生的概率是p,那么该事件的几率是p/(1-p),
对odds取对数得到
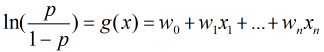
可以看出Logistic回归都是围绕一个Logistic函数来展开的。接下来就讲如何用极大似然估计求分类器的参数。
假设有
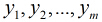
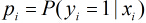
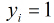
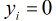
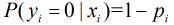
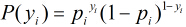
因为各个观测样本之间相互独立,那么它们的联合分布为各边缘分布的乘积。得到似然函数为
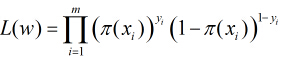
然后我们的目标是求出使这一似然函数的值最大的参数估计,最大似然估计就是求出参数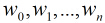
取得最大值,对函数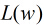
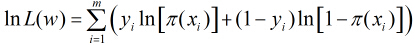
继续对这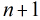
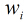
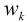
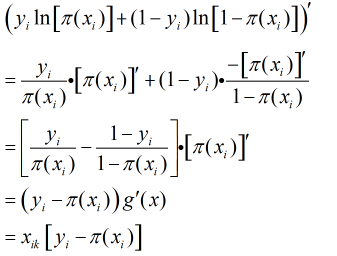
所以得到
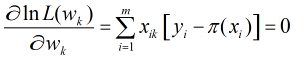
这样的方程一共有
上述方程比较复杂,一般方法似乎不能解之,所以我们引用了牛顿-拉菲森迭代方法求解。
利用牛顿迭代求多元函数的最值问题以后再讲。。。
简单牛顿迭代法:http://zh.m.wikipedia.org/wiki/%E7%89%9B%E9%A1%BF%E6%B3%95
实际上在上述似然函数求最大值时,可以用梯度上升算法,一直迭代下去。梯度上升算法和牛顿迭代相比,收敛速度
慢,因为梯度上升算法是一阶收敛,而牛顿迭代属于二阶收敛。
这篇关于Logistic函数与Logistic回归的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




