本文主要是介绍focal loss的几种实现版本(Keras/Tensorflow),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
起源于在工作中使用focal loss遇到的一个bug,我仔细的学习多个靠谱的focal loss讲解及实现版本
通过测试,我发现了这样一个奇怪的现象,几乎每个版本的focal loss实现对同样的输入计算出的loss都是不同的。
通过仔细的比对和思考,我总结了三种我认为正确的focal loss实现方法,并将代码分享出来。
完整的代码我整理到了我的github代码库AI-Toolbox中,代码戳这里
何为focal loss
focal loss 是随网络RetinaNet一起提出的一个令人惊艳的损失函数 paper 下载,主要针对的是解决正负样本比例严重偏斜所产生的模型难以训练的问题。
这里假设你对focal loss有所了解,简单回顾下公式 ,focal loss的定义如下:
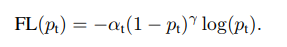
其中
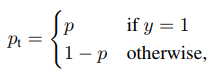
公式中 γ {\gamma} γ和 α {\alpha} α是两个可以调节的超参数。
γ {\gamma} γ的含义更好理解一些,其作用是削弱那些模型已经能够较好预测的样本产生损失的权重,使模型更专注于学习那些较难的hard case。
而 α t {\alpha}_t αt的定义,原文中的表述是:
For notational convenience, we define αt analogously to how we defined pt
也就是说, α t {\alpha}_t αt的定义可以同理于 p t p_t pt的定义。它的作用是平衡类别之间的权重。
这里补充一句,网上能够找到的各种不同版本的focal loss实现,分歧基本都出现在这里。由于focal loss最初是伴随着目标检测中判断某个区域是物体or背景(二分类问题)出现的,当我们使用focal loss来解决更一般化的问题时(比如多分类问题、多标签预测问题), α t {\alpha}_t αt 如何定义便会产生分歧,很难说哪种是绝对正统的,因为不同的定义赋予了损失函数不同的功能,可以针对不同的问题。
让我们来看看,我总结的三种实现版本。
focal loss for binary classification
针对二分类版本的 focal loss 实现
def binary_focal_loss(gamma=2, alpha=0.25):"""Binary form of focal loss.适用于二分类问题的focal lossfocal_loss(p_t) = -alpha_t * (1 - p_t)**gamma * log(p_t)where p = sigmoid(x), p_t = p or 1 - p depending on if the label is 1 or 0, respectively.References:https://arxiv.org/pdf/1708.02002.pdfUsage:model.compile(loss=[binary_focal_loss(alpha=.25, gamma=2)], metrics=["accuracy"], optimizer=adam)"""alpha = tf.constant(alpha, dtype=tf.float32)gamma = tf.constant(gamma, dtype=tf.float32)def binary_focal_loss_fixed(y_true, y_pred):"""y_true shape need be (None,1)y_pred need be compute after sigmoid"""y_true = tf.cast(y_true, tf.float32)alpha_t = y_true*alpha + (K.ones_like(y_true)-y_true)*(1-alpha)p_t = y_true*y_pred + (K.ones_like(y_true)-y_true)*(K.ones_like(y_true)-y_pred) + K.epsilon()focal_loss = - alpha_t * K.pow((K.ones_like(y_true)-p_t),gamma) * K.log(p_t)return K.mean(focal_loss)return binary_focal_loss_fixed
在使用本损失函数前,假设你已经将每个样本使用sigmoid映射成了一个0-1之间的数,代表二分类的概率。
在keras中使用此函数作为损失函数,只需在编译模型时指定损失函数为focal loss:
model.compile(loss=[binary_focal_loss(alpha=.25, gamma=2)], metrics=["accuracy"], optimizer=optimizer)
focal loss for multi category 版本1
针对多分类问题或多标签问题的 focal loss 实现1.
前面已经提到网上不同的实现版本中 α t {\alpha}_t αt的定义存在一定的分歧
当我们使用 α t {\alpha}_t αt来控制不同类别 / 标签 的权重时,实现代码如下:
def multi_category_focal_loss1(alpha, gamma=2.0):"""focal loss for multi category of multi label problem适用于多分类或多标签问题的focal lossalpha用于指定不同类别/标签的权重,数组大小需要与类别个数一致当你的数据集不同类别/标签之间存在偏斜,可以尝试适用本函数作为lossUsage:model.compile(loss=[multi_category_focal_loss1(alpha=[1,2,3,2], gamma=2)], metrics=["accuracy"], optimizer=adam)"""epsilon = 1.e-7alpha = tf.constant(alpha, dtype=tf.float32)#alpha = tf.constant([[1],[1],[1],[1],[1]], dtype=tf.float32)#alpha = tf.constant_initializer(alpha)gamma = float(gamma)def multi_category_focal_loss1_fixed(y_true, y_pred):y_true = tf.cast(y_true, tf.float32)y_pred = tf.clip_by_value(y_pred, epsilon, 1. - epsilon)y_t = tf.multiply(y_true, y_pred) + tf.multiply(1-y_true, 1-y_pred)ce = -tf.log(y_t)weight = tf.pow(tf.subtract(1., y_t), gamma)fl = tf.matmul(tf.multiply(weight, ce), alpha)loss = tf.reduce_mean(fl)return lossreturn multi_category_focal_loss1_fixed
注意,你需要将 α {\alpha} α指定为一个数组,数组大小需要与类别个数一致,代表着每一个类别对应的权重。
当你的数据集不同类别/标签之间存在偏斜,可以尝试适用本函数作为loss。
我们将核心函数copy出来做一个简单的测试,来验证 α {\alpha} α平衡类别间权重的有效性。
import os
from keras import backend as K
import tensorflow as tf
import numpy as npos.environ["CUDA_VISIBLE_DEVICES"] = '0'def multi_category_focal_loss1(y_true, y_pred):epsilon = 1.e-7gamma = 2.0#alpha = tf.constant([[2],[1],[1],[1],[1]], dtype=tf.float32)alpha = tf.constant([[1],[1],[1],[1],[1]], dtype=tf.float32)y_true = tf.cast(y_true, tf.float32)y_pred = tf.clip_by_value(y_pred, epsilon, 1. - epsilon)y_t = tf.multiply(y_true, y_pred) + tf.multiply(1-y_true, 1-y_pred)ce = -tf.log(y_t)weight = tf.pow(tf.subtract(1., y_t), gamma)fl = tf.matmul(tf.multiply(weight, ce), alpha)loss = tf.reduce_mean(fl)return loss
Y_true = np.array([[1, 1, 1, 1, 1], [0, 0, 0, 0, 0]])
Y_pred = np.array([[0.3, 0.99, 0.8, 0.97, 0.85], [0.9, 0.05, 0.1, 0.09, 0]], dtype=np.float32)
print(K.eval(multi_category_focal_loss1(Y_true, Y_pred)))
假设我们正在处理一个5个输出的多label预测问题,按照上面的示例,假设我们的模型对于第一个label相比于其它标签的预测很糟糕(这可能是由于第一个label出现的概率很小,在算损失时没有话语权导致的)。
上面代码的运算结果是1.2347984
我们使用 α {\alpha} α来调节第一个label的权重,尝试将 α {\alpha} α修改为:
alpha = tf.constant([[2],[1],[1],[1],[1]], dtype=tf.float32)
重新运行,损失增大为2.4623184,说明损失函数成功的放大了第一个类别的权重,会使模型更重视第一个label的正确预测。
focal loss for multi category 版本2
针对多分类问题或多标签问题的 focal loss 实现2.
当我们使用 α t {\alpha}_t αt 来控制真值y_true为 1 or 0 时的权重时
即 y = 1 时的权重为 α {\alpha} α, y = 0时的权重为 1 − α 1-{\alpha} 1−α
实现代码如下:
def multi_category_focal_loss2(gamma=2., alpha=.25):"""focal loss for multi category of multi label problem适用于多分类或多标签问题的focal lossalpha控制真值y_true为1/0时的权重1的权重为alpha, 0的权重为1-alpha当你的模型欠拟合,学习存在困难时,可以尝试适用本函数作为loss当模型过于激进(无论何时总是倾向于预测出1),尝试将alpha调小当模型过于惰性(无论何时总是倾向于预测出0,或是某一个固定的常数,说明没有学到有效特征)尝试将alpha调大,鼓励模型进行预测出1。Usage:model.compile(loss=[multi_category_focal_loss2(alpha=0.25, gamma=2)], metrics=["accuracy"], optimizer=adam)"""epsilon = 1.e-7gamma = float(gamma)alpha = tf.constant(alpha, dtype=tf.float32)def multi_category_focal_loss2_fixed(y_true, y_pred):y_true = tf.cast(y_true, tf.float32)y_pred = tf.clip_by_value(y_pred, epsilon, 1. - epsilon)alpha_t = y_true*alpha + (tf.ones_like(y_true)-y_true)*(1-alpha)y_t = tf.multiply(y_true, y_pred) + tf.multiply(1-y_true, 1-y_pred)ce = -tf.log(y_t)weight = tf.pow(tf.subtract(1., y_t), gamma)fl = tf.multiply(tf.multiply(weight, ce), alpha_t)loss = tf.reduce_mean(fl)return lossreturn multi_category_focal_loss2_fixed
注意,你需要将 α {\alpha} α指定为一个数组,数组大小需要与类别个数一致,代表着每一个类别对应的权重。
当你的模型欠拟合,学习存在困难时,可以尝试适用本函数作为loss
当模型过于激进(无论何时总是倾向于预测出1),尝试将alpha调小
当模型过于“懒惰”时(无论何时总是倾向于预测出0,或是某一个固定的常数,说明没有学到有效特征),尝试将alpha调大,鼓励模型预测出1。
同样地,我们将核心函数copy出来做一个简单的测试,来验证 α {\alpha} α平衡0-1权重的有效性。
import os
from keras import backend as K
import tensorflow as tf
import numpy as npos.environ["CUDA_VISIBLE_DEVICES"] = '0'def multi_category_focal_loss2_fixed(y_true, y_pred):epsilon = 1.e-7gamma=2.alpha = tf.constant(0.5, dtype=tf.float32)y_true = tf.cast(y_true, tf.float32)y_pred = tf.clip_by_value(y_pred, epsilon, 1. - epsilon)alpha_t = y_true*alpha + (tf.ones_like(y_true)-y_true)*(1-alpha)y_t = tf.multiply(y_true, y_pred) + tf.multiply(1-y_true, 1-y_pred)ce = -tf.log(y_t)weight = tf.pow(tf.subtract(1., y_t), gamma)fl = tf.multiply(tf.multiply(weight, ce), alpha_t)loss = tf.reduce_mean(fl)return loss
Y_true = np.array([[1, 1, 1, 1, 1], [0, 1, 1, 1, 1]])
Y_pred = np.array([[0.9, 0.99, 0.8, 0.97, 0.85], [0.9, 0.95, 0.91, 0.99, 1]], dtype=np.float32)
print(K.eval(multi_category_focal_loss2_fixed(Y_true, Y_pred)))
仍然假设我们正在处理一个5个输出的多label预测问题
按照上面的示例,假设这次我们遇到的问题是,所有的标签都会有很高的概率出现1,这时我们的模型发现了一个投机取巧的办法,将每个结果都预测为1,即可得到很小的loss,于是模型严重的欠拟合。
上面代码的运算结果是0.093982555,如我们所料,损失并不大,这显然会影响模型成功收敛。
我们使用 α {\alpha} α来抑制模型输出1的权重,尝试将 α {\alpha} α修改为:
alpha = tf.constant(0.25, dtype=tf.float32)
重新运行,损失增大为0.14024596,说明损失函数成功的放大了这种投机行为的损失。
参考文献
focal loss paper
Keras自定义Loss函数
Keras中自定义复杂的loss函数
github: focal-loss-keras 实现1
github: focal-loss-keras 实现2
kaggle kernel: FocalLoss for Keras
Focal Loss理解
应用:Multi-class classification with focal loss for imbalanced datasets
这篇关于focal loss的几种实现版本(Keras/Tensorflow)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







